perfusion pytorch
0.1.23
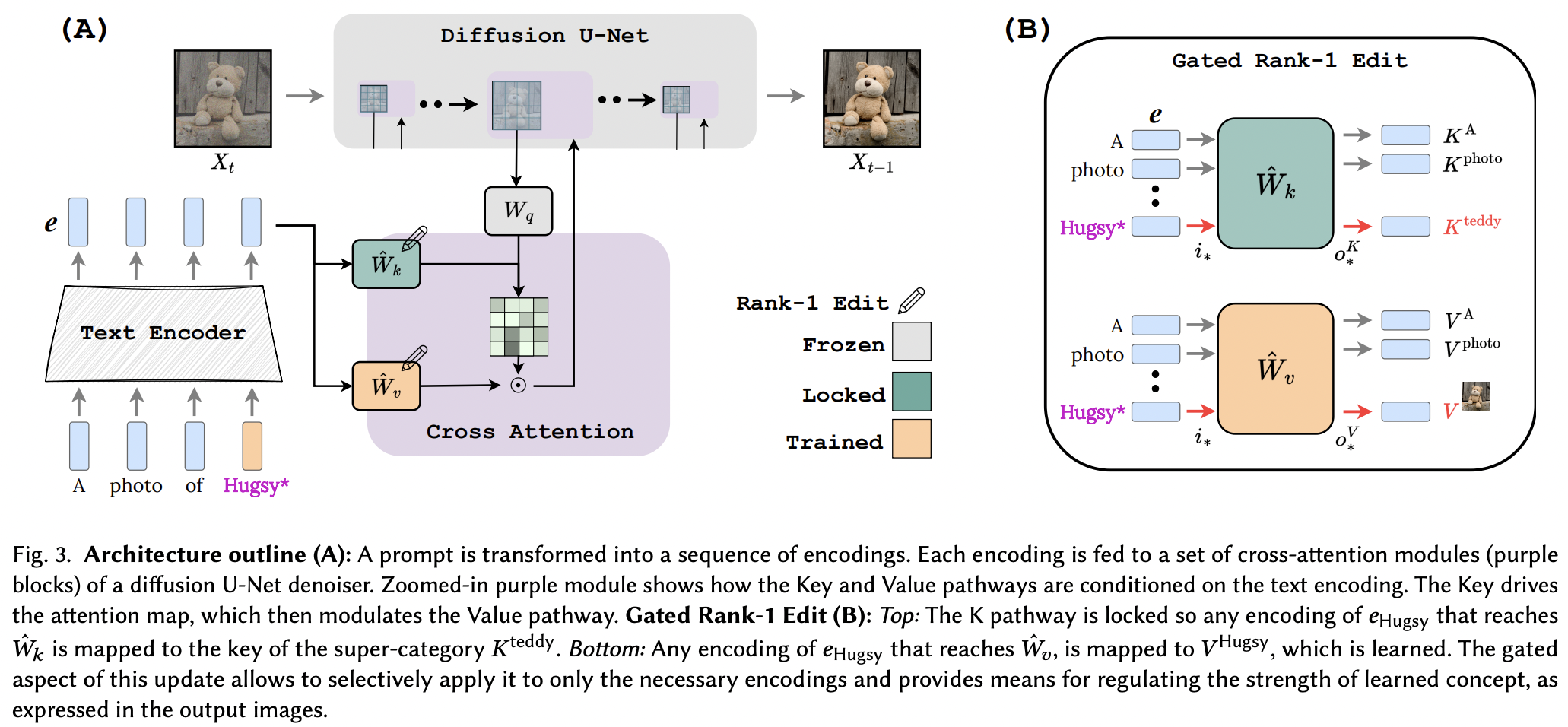
Implementação de edição de classificação um bloqueada por chave. Página do projeto
O ponto de venda deste artigo são parâmetros extras extremamente baixos por conceito adicionado, até 100kb.
Parece que eles aplicaram com sucesso a técnica de edição Rank-1 de um artigo de edição de memória para LLM, com algumas melhorias. Eles também identificaram que as chaves determinam o “onde” do novo conceito, enquanto os valores determinam o “o quê”, e propõem bloqueio de chave local/global para um conceito de superclasse (enquanto aprendem os valores).
Para os pesquisadores por aí, se este artigo for confirmado, as ferramentas neste repositório devem funcionar para qualquer outra rede de texto para <insert modality> usando condicionamento de atenção cruzada. Apenas um pensamento
StabilityAI pelo patrocínio generoso, assim como meus outros patrocinadores por aí
Yoad Tewel pelas múltiplas revisões de código e e-mails esclarecedores
Brad Vidler por pré-computar a matriz de covariância para o CLIP usado no Stable Diffusion 1.5!
Todos os mantenedores do OpenClip, por seus modelos de texto-imagem de aprendizagem contrastiva de código aberto SOTA
$ pip install perfusion-pytorch import torch
from torch import nn
from perfusion_pytorch import Rank1EditModule
to_keys = nn . Linear ( 768 , 320 , bias = False )
to_values = nn . Linear ( 768 , 320 , bias = False )
wrapped_to_keys = Rank1EditModule (
to_keys ,
is_key_proj = True
)
wrapped_to_values = Rank1EditModule (
to_values
)
text_enc = torch . randn ( 4 , 77 , 768 ) # regular input
text_enc_with_superclass = torch . randn ( 4 , 77 , 768 ) # init_input in algorithm 1, for key-locking
concept_indices = torch . randint ( 0 , 77 , ( 4 ,)) # index where the concept or superclass concept token is in the sequence
key_pad_mask = torch . ones ( 4 , 77 ). bool ()
keys = wrapped_to_keys (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
values = wrapped_to_values (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
# after much training ...
wrapped_to_keys . eval ()
wrapped_to_values . eval ()
keys = wrapped_to_keys ( text_enc )
values = wrapped_to_values ( text_enc ) O repositório também contém um EmbeddingWrapper que facilita o treinamento em um novo conceito (e para eventual inferência com vários conceitos)
import torch
from torch import nn
from perfusion_pytorch import EmbeddingWrapper
embed = nn . Embedding ( 49408 , 512 ) # open clip embedding, somewhere in the module tree of stable diffusion
# wrap it, and will automatically create a new concept for learning, based on the superclass embed string
wrapped_embed = EmbeddingWrapper (
embed ,
superclass_string = 'dog'
)
# now just pass in your prompts with the superclass id
embeds_with_new_concept , embeds_with_superclass , embed_mask , concept_indices = wrapped_embed ([
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]) # (3, 77, 512), (3, 77, 512), (3, 77), (3,)
# now pass both embeds through clip text transformer
# the embed_mask needs to be passed to the cross attention as key padding mask Se você puder identificar a instância CLIP dentro da instância de difusão estável, também poderá passá-la diretamente para o OpenClipEmbedWrapper para obter tudo o que precisa no futuro para as camadas de atenção cruzada
ex.
from perfusion_pytorch import OpenClipEmbedWrapper
texts = [
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]
wrapped_clip_with_new_concept = OpenClipEmbedWrapper (
stable_diffusion . path . to . clip ,
superclass_string = 'dog'
)
text_enc , superclass_enc , mask , indices = wrapped_clip_with_new_concept ( texts )
# (3, 77, 512), (3, 77, 512), (3, 77), (3,) conecte-se com SD 1.5, começando com dreambooth-sd de xiao
mostre um exemplo no leia-me para inferência com vários conceitos
inferir automaticamente onde a projeção de chaves e valores está se não for especificada para a função make_key_value_proj_rank1_edit_modules_
o wrapper de incorporação deve ter o cuidado de substituir pelo ID do token da superclasse e retornar a incorporação pela superclasse
revise vários conceitos - graças ao Yoad
oferecem uma função que conecta a atenção cruzada
lidar com vários conceitos em um prompt na inferência - somatório do termo sigmóide + saídas
oferecem uma maneira de combinar conceitos aprendidos separadamente de vários Rank1EditModule em um para inferência
Rank1EditModule s adicione o mascaramento zero-shot do conceito proposto no artigo
cuide da função que recebe o conjunto de dados e o codificador de texto e pré-calcula a matriz de covariância necessária para a atualização de classificação 1
em vez de fazer com que o pesquisador se preocupe com diferentes taxas de aprendizagem, ofereça o truque do gradiente fracionário de outro artigo (para aprender a incorporação do conceito)
@article { Tewel2023KeyLockedRO ,
title = { Key-Locked Rank One Editing for Text-to-Image Personalization } ,
author = { Yoad Tewel and Rinon Gal and Gal Chechik and Yuval Atzmon } ,
journal = { ACM SIGGRAPH 2023 Conference Proceedings } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:258436985 }
} @inproceedings { Meng2022LocatingAE ,
title = { Locating and Editing Factual Associations in GPT } ,
author = { Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:255825985 }
}

