audiolm pytorch
2.2.3
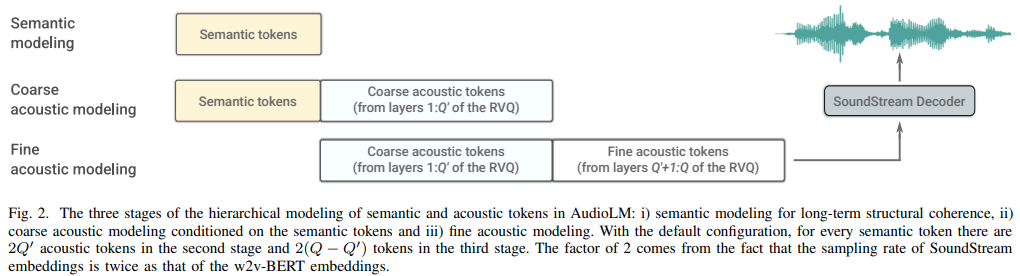
Implementação de AudioLM, uma abordagem de modelagem de linguagem para geração de áudio a partir da pesquisa do Google, em Pytorch
Também amplia o trabalho de condicionamento com classificador de orientação livre com T5. Isso permite fazer texto para áudio ou TTS, não oferecido no artigo. Sim, isso significa que VALL-E pode ser treinado a partir deste repositório. É essencialmente o mesmo.
Por favor, junte-se se estiver interessado em replicar este trabalho abertamente
Este repositório agora também contém uma versão licenciada pelo MIT do SoundStream. Também é compatível com EnCodec, que também é licenciado pelo MIT no momento em que este artigo foi escrito.
Atualização: AudioLM foi essencialmente usado para ‘resolver’ a geração musical no novo MusicLM
No futuro, este clipe de filme não faria mais sentido. Você apenas solicitaria uma IA.
Stability.ai pelo generoso patrocínio ao trabalho e pesquisa de ponta em inteligência artificial de código aberto
? Huggingface por suas incríveis bibliotecas de aceleração e transformadores
MetaAI para Fairseq e a licença liberal
@eonglints e Joseph por oferecerem seus conselhos profissionais e experiência, bem como pull requests!
@djqualia, @yigityu, @inspirit e @BlackFox1197 por ajudar na depuração do soundstream
Allen e LWprogramming pela revisão do código e envio de correções de bugs!
Ilya por encontrar um problema com a redução da resolução do discriminador multiescala e pelas melhorias do treinador de fluxo de som
Andrey por identificar uma perda ausente no fluxo sonoro e me guiar através dos hiperparâmetros adequados do espectrograma mel
Alejandro e Ilya por compartilharem seus resultados com o treinamento de fluxo sonoro e por resolverem alguns problemas com as incorporações posicionais de atenção local
Programação LW para adicionar compatibilidade com Encodec!
Programação LW para encontrar um problema com o manuseio do token EOS durante a amostragem do FineTransformer !
@YoungloLee por identificar um grande bug na convolução causal 1d para fluxo de som relacionado ao preenchimento que não leva em conta os avanços!
Hayden por apontar algumas discrepâncias no discriminador multiescala do Soundstream
$ pip install audiolm-pytorchExistem duas opções para o codec neural. Se você quiser usar o Encodec de 24kHz pré-treinado, basta criar um objeto Encodec da seguinte forma:
from audiolm_pytorch import EncodecWrapper
encodec = EncodecWrapper ()
# Now you can use the encodec variable in the same way you'd use the soundstream variables below. Caso contrário, para permanecer mais fiel ao artigo original, você pode usar SoundStream . Primeiro, SoundStream precisa ser treinado em um grande corpus de dados de áudio
from audiolm_pytorch import SoundStream , SoundStreamTrainer
soundstream = SoundStream (
codebook_size = 4096 ,
rq_num_quantizers = 8 ,
rq_groups = 2 , # this paper proposes using multi-headed residual vector quantization - https://arxiv.org/abs/2305.02765
use_lookup_free_quantizer = True , # whether to use residual lookup free quantization - there are now reports of successful usage of this unpublished technique
use_finite_scalar_quantizer = False , # whether to use residual finite scalar quantization
attn_window_size = 128 , # local attention receptive field at bottleneck
attn_depth = 2 # 2 local attention transformer blocks - the soundstream folks were not experts with attention, so i took the liberty to add some. encodec went with lstms, but attention should be better
)
trainer = SoundStreamTrainer (
soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 4 ,
grad_accum_every = 8 , # effective batch size of 32
data_max_length_seconds = 2 , # train on 2 second audio
num_train_steps = 1_000_000
). cuda ()
trainer . train ()
# after a lot of training, you can test the autoencoding as so
soundstream . eval () # your soundstream must be in eval mode, to avoid having the residual dropout of the residual VQ necessary for training
audio = torch . randn ( 10080 ). cuda ()
recons = soundstream ( audio , return_recons_only = True ) # (1, 10080) - 1 channel Seu SoundStream treinado pode então ser usado como um tokenizador genérico para áudio
audio = torch . randn ( 1 , 512 * 320 )
codes = soundstream . tokenize ( audio )
# you can now train anything with the codebook ids
recon_audio_from_codes = soundstream . decode_from_codebook_indices ( codes )
# sanity check
assert torch . allclose (
recon_audio_from_codes ,
soundstream ( audio , return_recons_only = True )
) Você também pode usar fluxos de som específicos para AudioLM e MusicLM importando AudioLMSoundStream e MusicLMSoundStream respectivamente
from audiolm_pytorch import AudioLMSoundStream , MusicLMSoundStream
soundstream = AudioLMSoundStream (...) # say you want the hyperparameters as in Audio LM paper
# rest is the same as above A partir da versão 0.17.0 , agora você pode invocar o método de classe no SoundStream para carregar arquivos de checkpoint, sem precisar lembrar de suas configurações.
from audiolm_pytorch import SoundStream
soundstream = SoundStream . init_and_load_from ( './path/to/checkpoint.pt' ) Para usar o rastreamento de pesos e preconceitos, primeiro defina use_wandb_tracking = True no SoundStreamTrainer e faça o seguinte
trainer = SoundStreamTrainer (
soundstream ,
...,
use_wandb_tracking = True
)
# wrap .train() with contextmanager, specifying project and run name
with trainer . wandb_tracker ( project = 'soundstream' , run = 'baseline' ):
trainer . train () Em seguida, três transformadores separados ( SemanticTransformer , CoarseTransformer , FineTransformer ) precisam ser treinados
ex. SemanticTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
# hubert checkpoints can be downloaded at
# https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
flash_attn = True
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () ex. CoarseTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SoundStream , CoarseTransformer , CoarseTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
coarse_transformer = CoarseTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
codebook_size = 1024 ,
num_coarse_quantizers = 3 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = CoarseTransformerTrainer (
transformer = coarse_transformer ,
codec = soundstream ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train () ex. FineTransformer
import torch
from audiolm_pytorch import SoundStream , FineTransformer , FineTransformerTrainer
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
fine_transformer = FineTransformer (
num_coarse_quantizers = 3 ,
num_fine_quantizers = 5 ,
codebook_size = 1024 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = FineTransformerTrainer (
transformer = fine_transformer ,
codec = soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()Todos juntos agora
from audiolm_pytorch import AudioLM
audiolm = AudioLM (
wav2vec = wav2vec ,
codec = soundstream ,
semantic_transformer = semantic_transformer ,
coarse_transformer = coarse_transformer ,
fine_transformer = fine_transformer
)
generated_wav = audiolm ( batch_size = 1 )
# or with priming
generated_wav_with_prime = audiolm ( prime_wave = torch . randn ( 1 , 320 * 8 ))
# or with text condition, if given
generated_wav_with_text_condition = audiolm ( text = [ 'chirping of birds and the distant echos of bells' ])Atualização: parece que isso vai funcionar, dado 'VALL-E'
ex. Transformador Semântico
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = 500 ,
dim = 1024 ,
depth = 6 ,
has_condition = True , # this will have to be set to True
cond_as_self_attn_prefix = True # whether to condition as prefix to self attention, instead of cross attention, as was done in 'VALL-E' paper
). cuda ()
# mock text audio dataset (as an example)
# you will have to extend your own from `Dataset`, and return an audio tensor as well as a string (the audio description) in any order (the framework will autodetect and route it into the transformer)
from torch . utils . data import Dataset
class MockTextAudioDataset ( Dataset ):
def __init__ ( self , length = 100 , audio_length = 320 * 32 ):
super (). __init__ ()
self . audio_length = audio_length
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
mock_audio = torch . randn ( self . audio_length )
mock_caption = 'audio caption'
return mock_caption , mock_audio
dataset = MockTextAudioDataset ()
# instantiate semantic transformer trainer and train
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
dataset = dataset ,
batch_size = 4 ,
grad_accum_every = 8 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()
# after much training above
sample = trainer . generate ( text = [ 'sound of rain drops on the rooftops' ], batch_size = 1 , max_length = 2 ) # (1, < 128) - may terminate early if it detects [eos] Porque todas as classes de treinador usam ? Accelerator, você pode facilmente fazer treinamento multi gpu usando o comando accelerate da mesma forma
Na raiz do projeto
$ accelerate configEntão, no mesmo diretório
$ accelerate launch train . py Transformador Grosso completo
use fairseq vq-wav2vec para embeddings
adicionar condicionamento
adicionar orientação gratuita do classificador
adicione consecutivo único para
incorporar a capacidade de usar recursos intermediários de Hubert como tokens semânticos, recomendado por eonglints
acomodar áudio de duração variável, trazer token eos
certifique-se de trabalhos consecutivos exclusivos com transformador grosso
bastante imprimindo todas as perdas do discriminador para registrar
manipular ao gerar tokens semânticos, os últimos logits podem não ser necessariamente os últimos na sequência, dado o processamento consecutivo único
código de amostragem completo para transformadores grossos e finos, o que será complicado
certifique-se de que a inferência completa com ou sem solicitação funcione na classe AudioLM
complete o código de treinamento completo para soundstream, cuidando do treinamento do discriminador
adicionar penalidade de gradiente eficiente para discriminadores de fluxo sonoro
conecte a amostra hz do conjunto de dados de som -> transformadores e faça uma reamostragem adequada durante o treinamento - pense se deve permitir que o conjunto de dados tenha arquivos de som variados ou aplicar a mesma amostra hz
código completo de treinamento do transformador para todos os três transformadores
refatore para que o transformador semântico tenha um wrapper que lide com consecutivos únicos, bem como wav para hubert ou vq-wav2vec
simplesmente não atende automaticamente ao token eos no lado do prompt (semântico para transformador grosso, grosso para transformador fino)
adicionar abandono estruturado de mascaramento causal esquecido, muito melhor do que abandono tradicional
descubra como suprimir o registro em fairseq
afirmar que todos os três transformadores passados para o audiolm são compatíveis
permitem incorporações posicionais relativas especializadas em transformadores finos com base em posições de correspondência absoluta de quantizadores entre grosso e fino
permitir vq residual agrupado no soundstream (use GroupedResidualVQ da biblioteca vector-quantize-pytorch), do hifi-codec
adicione atenção instantânea com NoPE
aceitar onda principal no AudioLM como um caminho para um arquivo de áudio e reamostrar automaticamente para semântica versus acústica
adicione cache de chave/valor a todos os transformadores, acelerando a inferência
projetar um transformador hierárquico grosso e fino
investigue a decodificação de especificações, primeiro teste em transformadores x e, em seguida, faça a portabilidade, se aplicável
refazer os embeddings posicionais na presença de grupos no resíduo vq
teste com síntese de fala para começar
ferramenta cli, algo como audiolm generate <wav.file | text> e salve o arquivo wav gerado no diretório local
retornar uma lista de ondas no caso de áudio de duração variável
apenas tome cuidado com o caso extremo no treinamento condicionado por texto do transformador grosso, onde a onda bruta é reamostrada em frequências diferentes. determinar automaticamente como rotear com base no comprimento
@inproceedings { Borsos2022AudioLMAL ,
title = { AudioLM: a Language Modeling Approach to Audio Generation } ,
author = { Zal{'a}n Borsos and Rapha{"e}l Marinier and Damien Vincent and Eugene Kharitonov and Olivier Pietquin and Matthew Sharifi and Olivier Teboul and David Grangier and Marco Tagliasacchi and Neil Zeghidour } ,
year = { 2022 }
} @misc { https://doi.org/10.48550/arxiv.2107.03312 ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco } ,
publisher = { arXiv } ,
url = { https://arxiv.org/abs/2107.03312 } ,
year = { 2021 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @article { Ho2022ClassifierFreeDG ,
title = { Classifier-Free Diffusion Guidance } ,
author = { Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.12598 }
} @misc { crowson2022 ,
author = { Katherine Crowson } ,
url = { https://twitter.com/rivershavewings }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Liu2022FCMFC ,
title = { FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners } ,
author = { Hao Liu and Xinyang Geng and Lisa Lee and Igor Mordatch and Sergey Levine and Sharan Narang and P. Abbeel } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13432 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Li2021LocalViTBL ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and K. Zhang and Jie Cao and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2104.05707 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @article { Hu2017SqueezeandExcitationN ,
title = { Squeeze-and-Excitation Networks } ,
author = { Jie Hu and Li Shen and Gang Sun } ,
journal = { 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
year = { 2017 } ,
pages = { 7132-7141 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @article { Kazemnejad2023TheIO ,
title = { The Impact of Positional Encoding on Length Generalization in Transformers } ,
author = { Amirhossein Kazemnejad and Inkit Padhi and Karthikeyan Natesan Ramamurthy and Payel Das and Siva Reddy } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.19466 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

