yoloface
1.0.0
O YOLOv3 (You Only Look Once) é um algoritmo de detecção de objetos em tempo real de última geração. O modelo publicado reconhece 80 objetos diferentes em imagens e vídeos. Para obter mais detalhes, você pode consultar este artigo.
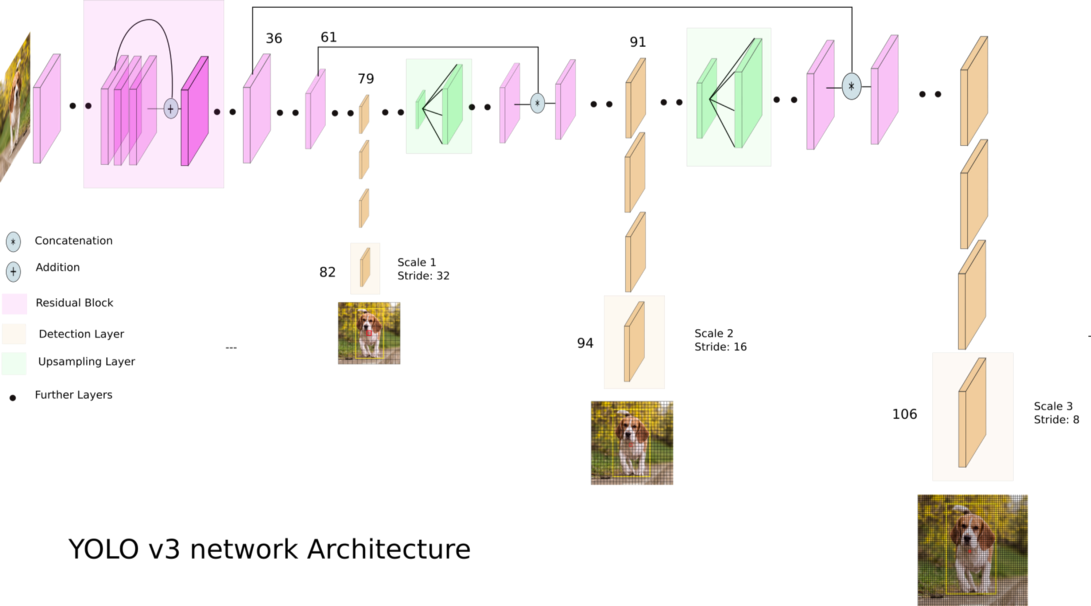
Crédito: Ayoosh Kathuria
O módulo OpenCV dnn suporta a execução de inferência em modelos de aprendizado profundo pré-treinados de estruturas populares como TensorFlow, Torch, Darknet e Caffe.
O desenvolvimento deste projeto será isolado em ambiente virtual Python. Isso nos permite experimentar diferentes versões de dependências.
Existem muitas maneiras de instalar virtual environment (virtualenv) , consulte o guia Python Virtual Environments: A Primer para diferentes plataformas, mas aqui estão algumas:
$ pip install virtualenv$ pip install --upgrade virtualenvCrie um ambiente virtual Python 3.6 para este projeto e ative o virtualenv:
$ virtualenv -p python3.6 yoloface
$ source ./yoloface/bin/activateA seguir, instale as dependências deste projeto:
$ pip install -r requirements.txt$ git clone https://github.com/sthanhng/yoloface Para detecção de rosto, você deve baixar o arquivo de pesos YOLOv3 pré-treinado que foi treinado no conjunto de dados WIDER FACE: A Face Detection Benchmark deste link e colocá-lo no diretório model-weights/ .
Execute o seguinte comando:
entrada de imagem
$ python yoloface.py --image samples/outside_000001.jpg --output-dir outputs/entrada de vídeo
$ python yoloface.py --video samples/subway.mp4 --output-dir outputs/Webcam
$ python yoloface.py --src 1 --output-dir outputs/
Este projeto está licenciado sob a licença MIT - consulte o arquivo LICENSE.md para obter mais detalhes.


