rtdl revisiting models
1.0.0
Importante
Confira o novo modelo DL tabular: TabM
arXiv? Pacote Python Outros projetos DL tabulares
Esta é a implementação oficial do artigo "Revisitando Modelos de Aprendizado Profundo para Dados Tabulares".
Em uma frase: modelos do tipo MLP ainda são boas linhas de base e o FT-Transformer é uma nova e poderosa adaptação da arquitetura do Transformer para problemas de dados tabulares.
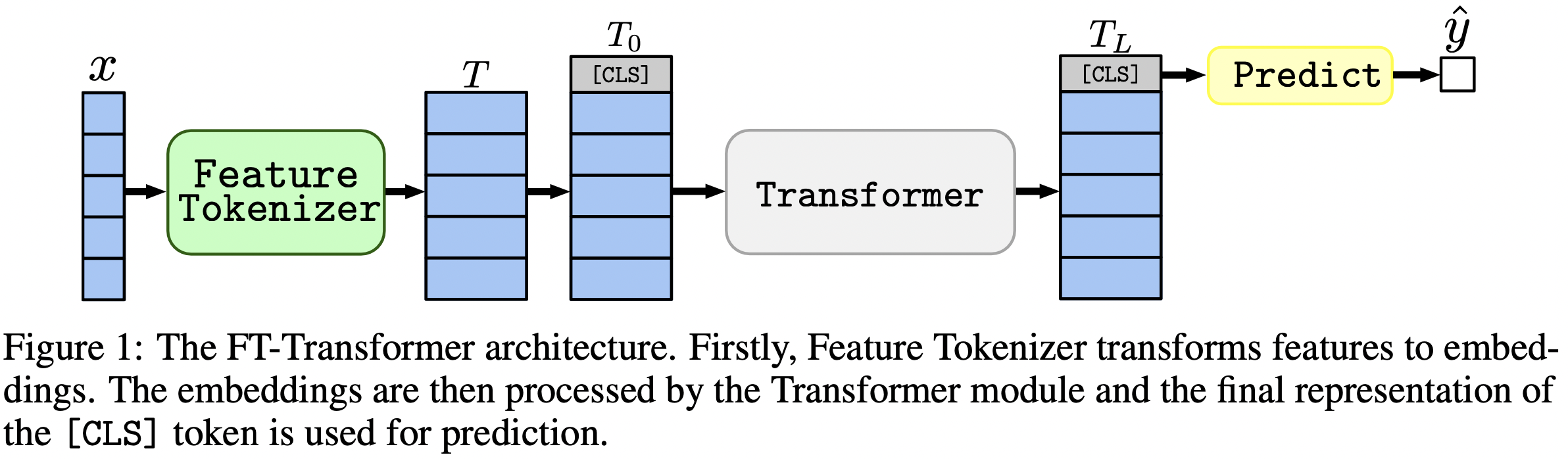
O artigo enfoca arquiteturas para problemas de dados tabulares. Os resultados:
O pacote Python no diretório package/ é a forma recomendada de usar o artigo na prática e em trabalhos futuros.
O resto do documento :
O diretório output/ contém vários resultados e hiperparâmetros (ajustados) para vários modelos e conjuntos de dados usados no artigo.
Por exemplo, vamos explorar as métricas do modelo MLP. Primeiro, vamos carregar os relatórios (os arquivos stats.json ):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])Agora, para cada conjunto de dados, vamos calcular a média da pontuação do teste de todas as sementes aleatórias:
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))A saída corresponde exatamente à Tabela 2 do artigo:
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
A abordagem acima também pode ser usada para explorar hiperparâmetros para obter intuição sobre valores típicos de hiperparâmetros para diferentes algoritmos. Por exemplo, é assim que se pode calcular a taxa mediana de aprendizagem ajustada para o modelo MLP:
Observação
Para alguns algoritmos (por exemplo, MLP), projetos mais recentes oferecem mais resultados que podem ser explorados de forma semelhante. Por exemplo, consulte este artigo no TabR.
Aviso
Use esta abordagem com cautela. Ao estudar valores de hiperparâmetros:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536Observação
Esta seção é longa. Use o recurso "Esboço" no GitHub em seu editor de texto para obter uma visão geral desta seção.
O código está organizado da seguinte forma:
bin :ensemble.py realiza montagemtune.py realiza ajuste de hiperparâmetrosanalysis_gbdt_vs_nn.py executa os experimentoscreate_synthetic_data_plots.py constrói gráficoslib contém ferramentas comuns usadas por programas no binoutput contém arquivos de configuração (entradas para programas em bin ) e resultados (métricas, configurações ajustadas, etc.)package contém o pacote Python para este artigo Instalar conda
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-modelsEste ambiente é necessário apenas para experimentar o TabNet. Para todos os outros casos use o ambiente PyTorch.
As instruções são as mesmas do ambiente PyTorch (incluindo a instalação do PyTorch!), mas:
python=3.7.10cudatoolkit=10.0pip install -r requirements.txt faça o seguinte:pip install tensorflow-gpu==1.14tensorboard em requirements.txtLICENÇA : ao baixar nosso conjunto de dados você aceita licenças de todos os seus componentes. Não impomos quaisquer novas restrições além dessas licenças. Você pode encontrar a lista de fontes na seção “Referências” do nosso artigo.
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz Esta seção fornece apenas comandos específicos com poucos comentários. Após concluir o tutorial, recomendamos verificar a próxima seção para melhor compreensão de como trabalhar com o repositório. Também ajudará a entender melhor o tutorial.
Neste tutorial, reproduziremos os resultados do MLP no conjunto de dados California Housing. Iremos cobrir:
Observe que as chances de obter exatamente os mesmos resultados são bastante baixas, porém, não devem diferir muito dos nossos. Antes de executar qualquer coisa, vá até a raiz do repositório e defina explicitamente CUDA_VISIBLE_DEVICES (se você planeja usar GPU):
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0Antes de começarmos, vamos verificar se o ambiente está configurado com sucesso. Os comandos a seguir devem treinar um MLP no conjunto de dados California Housing:
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml O resultado deve estar no diretório draft/check_environment . Por enquanto, o conteúdo do resultado não é importante.
Nossa configuração para ajustar o MLP no conjunto de dados California Housing está localizada em output/california_housing/mlp/tuning/0.toml . Para reproduzir o ajuste, copie nossa configuração e execute seu ajuste:
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml O resultado do seu ajuste estará localizado em output/california_housing/mlp/tuning/reproduced , você pode compará-lo com o nosso: output/california_housing/mlp/tuning/0 . O arquivo best.toml contém a melhor configuração que avaliaremos na próxima seção.
Agora temos que avaliar a configuração ajustada com 15 sementes aleatórias diferentes.
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done Nosso diretório com resultados de avaliação está localizado ao lado do seu, ou seja, em output/california_housing/mlp/tuned .
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced Seus resultados estarão localizados em output/california_housing/mlp/tuned_reproduced_ensemble , você pode compará-los com os nossos: output/california_housing/mlp/tuned_ensemble .
Use a abordagem descrita aqui para resumir os resultados do experimento conduzido (modifique o filtro de caminho em .glob(...) adequadamente: tuned -> tuned_reproduced ).
Etapas semelhantes podem ser executadas para todos os modelos e conjuntos de dados. O processo de ajuste é um pouco diferente no caso da pesquisa em grade: você deve executar todas as configurações desejadas e escolher manualmente a melhor com base no desempenho da validação . Por exemplo, consulte output/epsilon/ft_transformer .
Você deve executar scripts Python na raiz do repositório. A maioria dos programas espera um arquivo de configuração como único argumento. A saída será um diretório com o mesmo nome da configuração, mas sem a extensão. As configurações são escritas em TOML. As listas de possíveis argumentos para os programas não são fornecidas e devem ser inferidas a partir de scripts (normalmente, a configuração é representada pela variável args nos scripts). Se quiser usar CUDA, você deverá definir explicitamente a variável de ambiente CUDA_VISIBLE_DEVICES . Por exemplo:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.tomlSe você for usar CUDA o tempo todo, poderá salvar a variável de ambiente no ambiente Conda:
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " A opção -f ( --force ) removerá os resultados existentes e executará o script do zero:
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config bin/tune.py suporta continuação:
python bin/tune.py path/to/config.toml --continuestats.json e outros resultados Para todos os scripts, stats.json é a parte mais importante da saída. O conteúdo varia de programa para programa. Pode conter:
As previsões para conjuntos de treinamento, validação e teste geralmente também são salvas.
Agora você sabe tudo o que precisa para reproduzir todos os resultados e estender este repositório às suas necessidades. O tutorial também deve estar mais claro agora. Sinta-se à vontade para abrir questões e fazer perguntas.
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


