PALM E
0.0.4

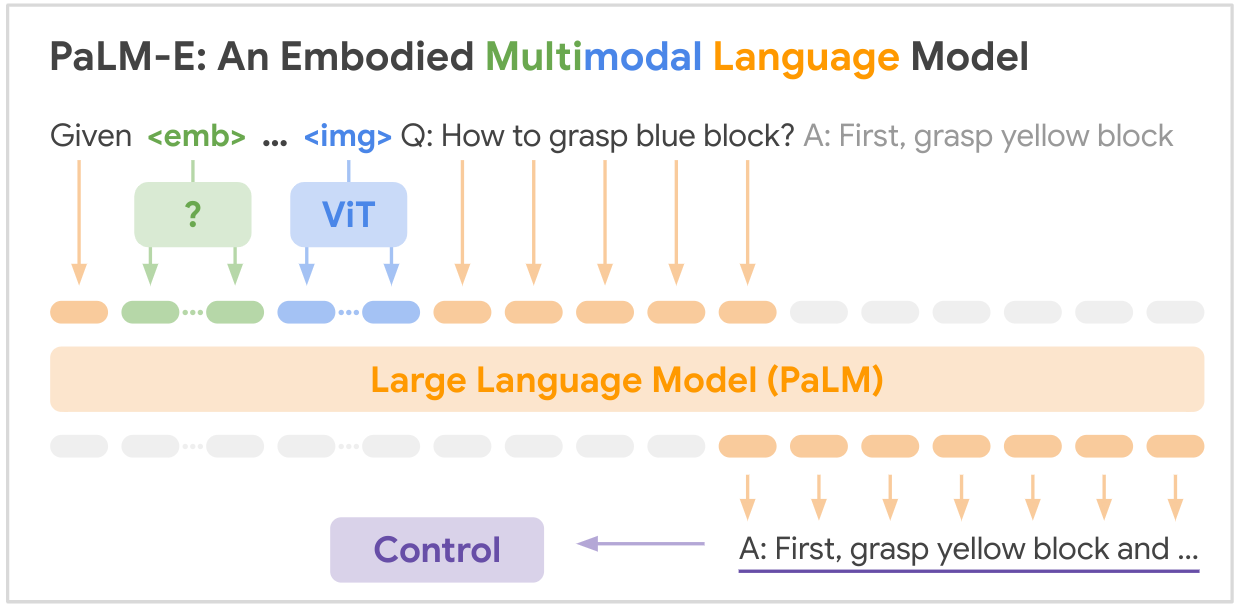
Esta é a implementação de código aberto do modelo de base multimodal SOTA "PALM-E: An Empowered Multimodal Language Model" do Google. PALM-E é um único grande modelo multimodal incorporado, que pode abordar uma variedade de tarefas de raciocínio incorporadas, desde uma variedade de modalidades de observação, em múltiplas modalidades e, além disso, exibe transferência positiva: o modelo se beneficia de diversos treinamentos conjuntos em domínios de linguagem, visão e linguagem visual em escala de Internet.
LINK DE PAPEL: PaLM-E: um modelo de linguagem multimodal incorporado
pip install palme import torch
from palme . model import PalmE
#usage
img = torch . randn ( 1 , 3 , 256 , 256 )
caption = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
model = PalmE ()
output = model ( img , caption )
print ( output . shape ) # (1, 1024, 20000)
Aqui está uma tabela de resumo dos principais conjuntos de dados mencionados no artigo:
| Conjunto de dados | Tarefas | Tamanho | Link |
|---|---|---|---|
| TAMPA | Planejamento de manipulação robótica, VQA | 96.000 cenas | Conjunto de dados personalizado |
| Tabela de idiomas | Planejamento de manipulação robótica | Conjunto de dados personalizado | Link |
| Manipulação Móvel | Navegação robótica e planejamento de manipulação, VQA | 2912 sequências | Baseado no conjunto de dados SayCan |
| WebLI | Recuperação de imagem-texto | 66 milhões de pares de legenda de imagem | Link |
| VQAv2 | Resposta visual a perguntas | 1,1 milhão de perguntas sobre imagens COCO | Link |
| OK-VQA | Resposta visual a perguntas que requerem conhecimento externo | 14.031 perguntas sobre imagens COCO | Link |
| COCO | Legendagem de imagens | 330 mil imagens com legendas | Link |
| Wikipédia | Corpus de texto | N / D | Link |
Os principais conjuntos de dados de robótica foram coletados especificamente para este trabalho, enquanto os conjuntos de dados maiores de linguagem de visão (WebLI, VQAv2, OK-VQA, COCO) são referências padrão nesse campo. Os conjuntos de dados variam de dezenas de milhares de exemplos para os domínios da robótica a dezenas de milhões para dados de linguagem de visão em escala da Internet.
Seu brilho é necessário! Junte-se a nós e, juntos, vamos tornar o PALM-E ainda mais inspirador:
? Correções, ? melhorias, documentos ou ideias – todos são bem-vindos! Vamos moldar o futuro da IA, de mãos dadas.
@article{driess2023palme,
title={PALM-E: An Embodied Multimodal Language Model},
author={Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff, Klaus and Zeng, Andy and Mordatch, Igor and Florence, Pete},
journal={arXiv preprint arXiv:2303.03378},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.03378}
}

