lion pytorch
0.2.3
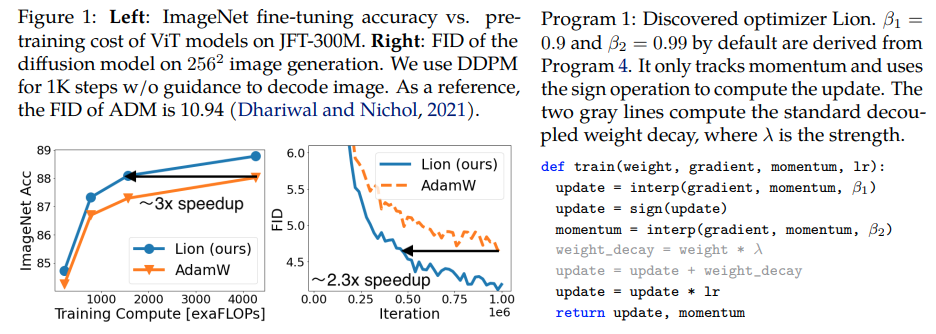
Lion, Evo L ved S i gn M ome n tum, novo otimizador descoberto pelo Google Brain que é supostamente melhor que Adam(w), em Pytorch. Esta é quase uma cópia direta daqui, com algumas pequenas modificações.
É tão simples que podemos torná-lo acessível e usado por todos o mais rápido possível para treinar alguns ótimos modelos, se realmente funcionar?
Taxa de aprendizagem e redução de peso: os autores escrevem na Seção 5 - Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength. O valor inicial, o valor de pico e o valor final no cronograma da taxa de aprendizagem devem ser alterados simultaneamente com a mesma proporção em relação ao AdamW, evidenciado por um pesquisador.
Cronograma de taxa de aprendizagem: os autores usam o mesmo cronograma de taxa de aprendizagem para Lion que AdamW no artigo. No entanto, eles observam um ganho maior ao usar um esquema de decaimento de cosseno para treinar ViT, em comparação com um esquema recíproco de raiz quadrada.
β1 e β2: os autores escrevem na Seção 5 - The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively. Semelhante a como as pessoas reduzem β2 para 0,99 ou menos e aumentam ε para 1e-6 no AdamW para melhorar a estabilidade, usar β1=0.95, β2=0.98 no Lion também pode ser útil para mitigar a instabilidade durante o treinamento, sugerido pelos autores. Isso foi corroborado por um pesquisador.
Atualização: parece funcionar para minha modelagem de linguagem autorregressiva local enwik8.
Atualização 2: experimentos, parecem muito piores do que Adam se a taxa de aprendizado se mantiver constante.
Atualização 3: Dividindo a taxa de aprendizado por 3, obtendo resultados iniciais melhores do que Adam. Talvez Adam tenha sido destronado depois de quase uma década.
Atualização 4: usar a regra prática de taxa de aprendizado 10 vezes menor do artigo resultou na pior execução. Então acho que ainda precisa de um pouco de ajuste.
Um resumo das atualizações anteriores: conforme mostrado nos experimentos, o Leão com uma taxa de aprendizado 3x menor vence o Adam. Ainda é necessário um pouco de ajuste, pois uma taxa de aprendizado 10 vezes menor leva a um resultado pior.
Atualização 5: até agora ouvimos todos os resultados positivos para modelagem de linguagem, quando bem feito. Também ouvi resultados positivos para treinamento significativo de texto em imagem, embora seja necessário um pouco de ajuste. Os resultados negativos parecem estar relacionados a problemas e arquiteturas fora do que foi avaliado no artigo - RL, redes feedforward, arquiteturas híbridas estranhas com LSTMs + convoluções etc. Anedotas negativas também confirmam que esta técnica é sensível ao tamanho do lote, quantidade de dados/aumento . A ser definido qual é o cronograma de taxa de aprendizagem ideal e se o resfriamento afeta os resultados. Curiosamente, também tivemos um resultado positivo no clipe aberto, que se tornou negativo à medida que o tamanho do modelo foi aumentado (mas pode ser resolvido).
Atualização 6: problema de abertura do clipe resolvido pelo autor, definindo uma temperatura inicial mais alta.
Atualização 7: recomendaria este otimizador apenas na configuração de tamanhos de lote altos (64 ou superior)
$ pip instalar leão-pytorch
Alternativamente, usando conda:
$ conda instalar leão-pytorch
# toy modelimport torchfrom torch import nnmodel = nn.Linear(10, 1)# import Lion e instanciar com parâmetrosfrom lion_pytorch import Lionopt = Lion(model.parameters(), lr=1e-4, Weight_decay=1e-2)# forward e perda reversa = modelo (torch.randn (10)) perda.backward () # otimizador stepopt.step () opt.zero_grad ()
Para usar um kernel fundido para atualizar os parâmetros, primeiro pip install triton -U --pre , então
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # defina como True para usar o kernel cuda com Triton lang (Tillet et al))
Stability.ai pelo generoso patrocínio ao trabalho e pesquisa de ponta em inteligência artificial de código aberto
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},autor = {Chen, Xiangning e Liang, Chen e Huang, Da e Real, Esteban e Wang, Kaiyuan e Liu, Yao e Pham, Hieu e Dong, Xuanyi e Luong, Thang e Hsieh, Cho-Jui e Lu, Yifeng e Le, Quoc V.}, título = {descoberta simbólica de algoritmos de otimização}, editor = {arXiv}, ano = {2023}} @article{Tillet2019TritonAI,title = {Triton: uma linguagem intermediária e compilador para cálculos de redes neurais lado a lado},author = {Philippe Tillet e H. Kung e D. Cox},journal = {Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Linguagens de aprendizagem e programação}, ano = {2019}} @misc{Schaipp2024,autor = {Fabian Schaipp},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {Otimizadores cautelosos: melhorando o treinamento com uma linha de código},author = {Kaizhao Liang e Lizhang Chen e Bo Liu e Qiang Liu},ano = {2024},url = {https://api .semanticscholar.org/CorpusID:274234738}} 

