meshgpt pytorch
1.8.1
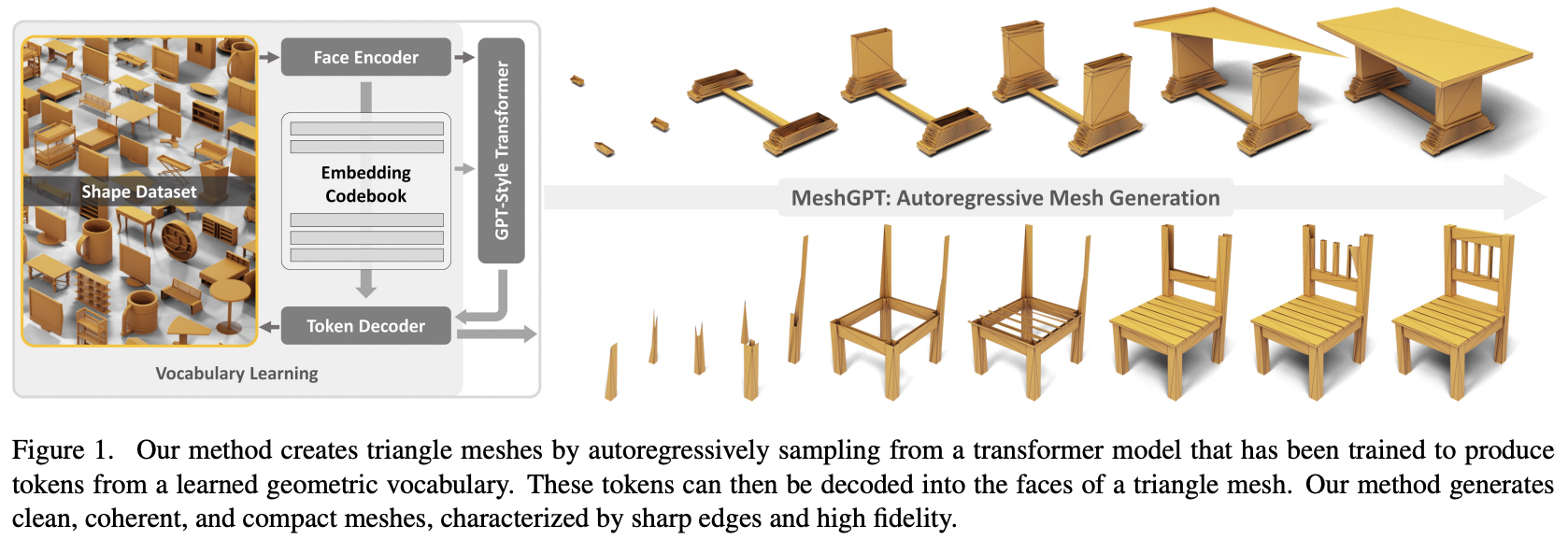
Implementação de MeshGPT, geração de malha SOTA usando Atenção, em Pytorch
Também adicionará condicionamento de texto, para eventual recurso de texto para 3D
Por favor, junte-se se estiver interessado em colaborar com outras pessoas para replicar este trabalho
Atualização: Marcus treinou e carregou um modelo funcional para? Abraçando cara!
StabilityAI, programa de subsídios de IA de código aberto A16Z e ? Huggingface pelos generosos patrocínios, bem como aos meus outros patrocinadores, por me proporcionarem a independência para abrir o código-fonte da atual pesquisa de inteligência artificial
Einops por facilitar minha vida
Marcus pela revisão inicial do código (apontando alguns recursos derivados ausentes), bem como pela execução dos primeiros experimentos completos bem-sucedidos
Marcus pelo primeiro treinamento bem-sucedido de uma coleção de formas condicionadas em rótulos
Quexi Ma por encontrar vários bugs com tratamento automático de eos
Yingtian por encontrar um bug com o desfoque gaussiano das posições para suavização de rótulo espacial
Marcus mais uma vez por executar os experimentos para validar que é possível estender o sistema de triângulos para quádruplos
Marcus por identificar um problema com o condicionamento de texto e por realizar todos os experimentos que levaram à sua resolução
$ pip install meshgpt-pytorch import torch
from meshgpt_pytorch import (
MeshAutoencoder ,
MeshTransformer
)
# autoencoder
autoencoder = MeshAutoencoder (
num_discrete_coors = 128
)
# mock inputs
vertices = torch . randn (( 2 , 121 , 3 )) # (batch, num vertices, coor (3))
faces = torch . randint ( 0 , 121 , ( 2 , 64 , 3 )) # (batch, num faces, vertices (3))
# make sure faces are padded with `-1` for variable lengthed meshes
# forward in the faces
loss = autoencoder (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training...
# you can pass in the raw face data above to train a transformer to model this sequence of face vertices
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768
)
loss = transformer (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets
faces_coordinates , face_mask = transformer . generate ()
# (batch, num faces, vertices (3), coordinates (3)), (batch, num faces)
# now post process for the generated 3d asset Para síntese de forma 3D condicionada por texto, basta definir condition_on_text = True em seu MeshTransformer e, em seguida, passar sua lista de descrições como argumento de palavra-chave texts
ex.
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768 ,
condition_on_text = True
)
loss = transformer (
vertices = vertices ,
faces = faces ,
texts = [ 'a high chair' , 'a small teapot' ],
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets conditioned on text
faces_coordinates , face_mask = transformer . generate (
texts = [ 'a long table' ],
cond_scale = 8. , # a cond_scale > 1. will enable classifier free guidance - can be placed anywhere from 3. - 10.
remove_parallel_component = True # from https://arxiv.org/abs/2410.02416
) Se você deseja tokenizar malhas, para uso em seu transformador multimodal, basta invocar .tokenize em seu autoencoder (ou o mesmo método na instância do autoencoder trainer para o modelo exponencialmente suavizado)
mesh_token_ids = autoencoder . tokenize (
vertices = vertices ,
faces = faces
)
# (batch, num face vertices, residual quantized layer) Na raiz do projeto, execute
$ cp .env.sample .envcodificador automático
face_edges diretamente de faces e vértices transformador
invólucro de treinador com aceleração hf
condicionamento de texto usando a própria biblioteca CFG
transformadores hierárquicos (usando o transformador RQ)
corrigir o cache na camada gateloop simples em outro repositório
atenção local
corrigir cache kv para transformador hierárquico de dois estágios - 7x mais rápido agora e mais rápido que o transformador não hierárquico original
corrigir cache para camadas gateloop
permitir a personalização das dimensões do modelo da rede de atenção fina versus grossa
descubra se o autoencoder é realmente necessário - é necessário, as ablações estão no papel
tornar o transformador eficiente
opção de decodificação especulativa
gaste um dia em documentação
@inproceedings { Siddiqui2023MeshGPTGT ,
title = { MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers } ,
author = { Yawar Siddiqui and Antonio Alliegro and Alexey Artemov and Tatiana Tommasi and Daniele Sirigatti and Vladislav Rosov and Angela Dai and Matthias Nie{ss}ner } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265457242 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Leviathan2022FastIF ,
title = { Fast Inference from Transformers via Speculative Decoding } ,
author = { Yaniv Leviathan and Matan Kalman and Y. Matias } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:254096365 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Lee2022AutoregressiveIG ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook-Shin Han } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11513-11522 } ,
url = { https://api.semanticscholar.org/CorpusID:247244535 }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
}

