algebraic nnhw
1.0.0
Este repositório contém o código-fonte para arquiteturas de hardware de ML que requerem quase metade do número de unidades multiplicadoras para atingir o mesmo desempenho, executando algoritmos alternativos de produto interno que trocam quase metade das multiplicações por adições baratas de baixa largura de bits, enquanto ainda produzem saída idêntica como o produto interno convencional. Isso aumenta o rendimento teórico e os limites de eficiência computacional dos aceleradores de ML. Consulte a seguinte publicação do jornal para obter os detalhes completos:
TE Pogue e N. Nicolici, "Algoritmos e arquiteturas rápidas de produtos internos para aceleradores de redes neurais profundas", em IEEE Transactions on Computers, vol. 73, não. 2, pp. 495-509, fevereiro de 2024, doi: 10.1109/TC.2023.3334140.
URL do artigo: https://ieeexplore.ieee.org/document/10323219
Versão de acesso aberto: https://arxiv.org/abs/2311.12224
Resumo: Apresentamos um novo algoritmo chamado Free-pipeline Fast Inner Product (FFIP) e sua arquitetura de hardware que melhora um algoritmo rápido de produto interno (FIP) pouco explorado proposto por Winograd em 1968. Ao contrário dos algoritmos de filtragem mínima Winograd não relacionados para camadas convolucionais, o FIP é aplicável a todas as camadas do modelo de aprendizado de máquina (ML) que podem se decompor principalmente em multiplicação de matrizes, incluindo camadas totalmente conectadas, convolucionais, recorrentes e de atenção/transformador. Implementamos o FIP pela primeira vez em um acelerador de ML e, em seguida, apresentamos nosso algoritmo FFIP e arquitetura generalizada que melhoram inerentemente a frequência de clock do FIP e, como consequência, o rendimento por um custo de hardware semelhante. Por fim, contribuímos com otimizações específicas de ML para algoritmos e arquiteturas FIP e FFIP. Mostramos que o FFIP pode ser perfeitamente incorporado em aceleradores ML de matriz sistólica de ponto fixo tradicionais para atingir o mesmo rendimento com metade do número de unidades de acumulação múltipla (MAC), ou pode dobrar o tamanho máximo da matriz sistólica que pode caber em dispositivos com um orçamento fixo de hardware. Nossa implementação FFIP para modelos de ML não esparsos com entradas de ponto fixo de 8 a 16 bits alcança maior rendimento e eficiência computacional do que as melhores soluções anteriores da categoria no mesmo tipo de plataforma computacional.
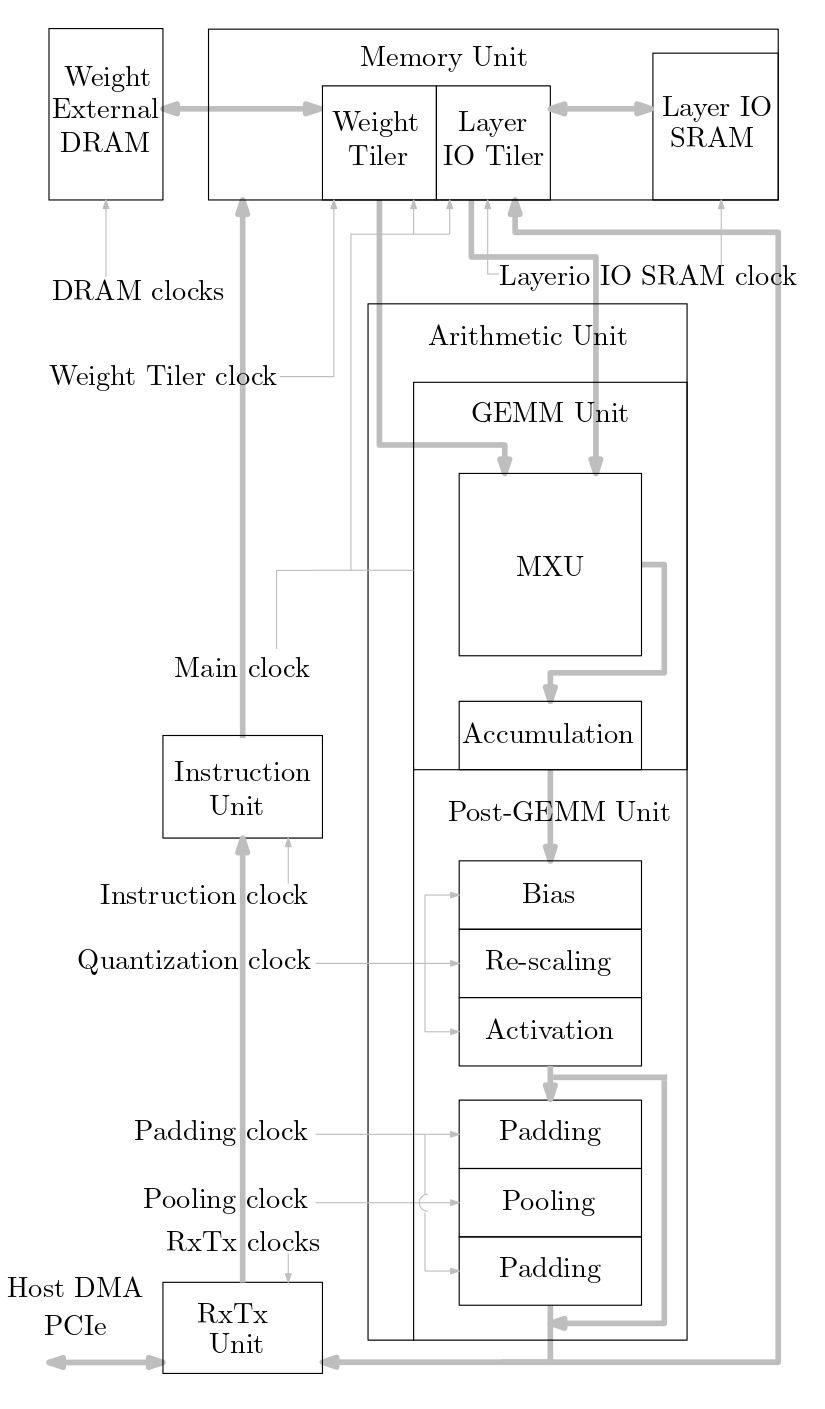
O diagrama a seguir mostra uma visão geral do sistema acelerador de ML implementado neste código-fonte:
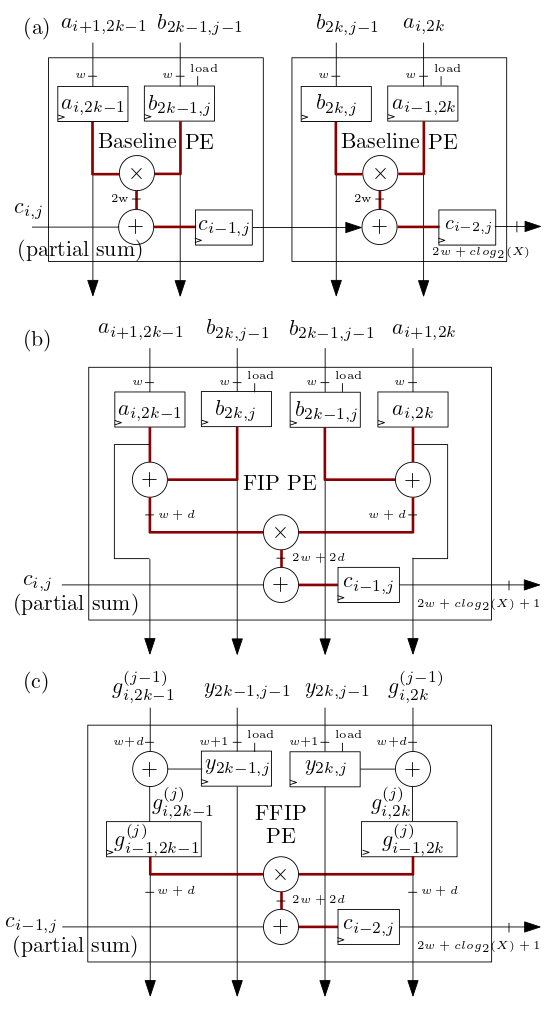
Os elementos de processamento (PE) da matriz sistólica FIP e FFIP (PE) mostrados abaixo em (b) e (c) implementam os algoritmos de produto interno FIP e FFIP e cada um fornece individualmente o mesmo poder computacional efetivo que os dois PEs de linha de base mostrados em ( a) combinados que implementam o produto interno da linha de base como nos aceleradores ML de matriz sistólica anteriores:
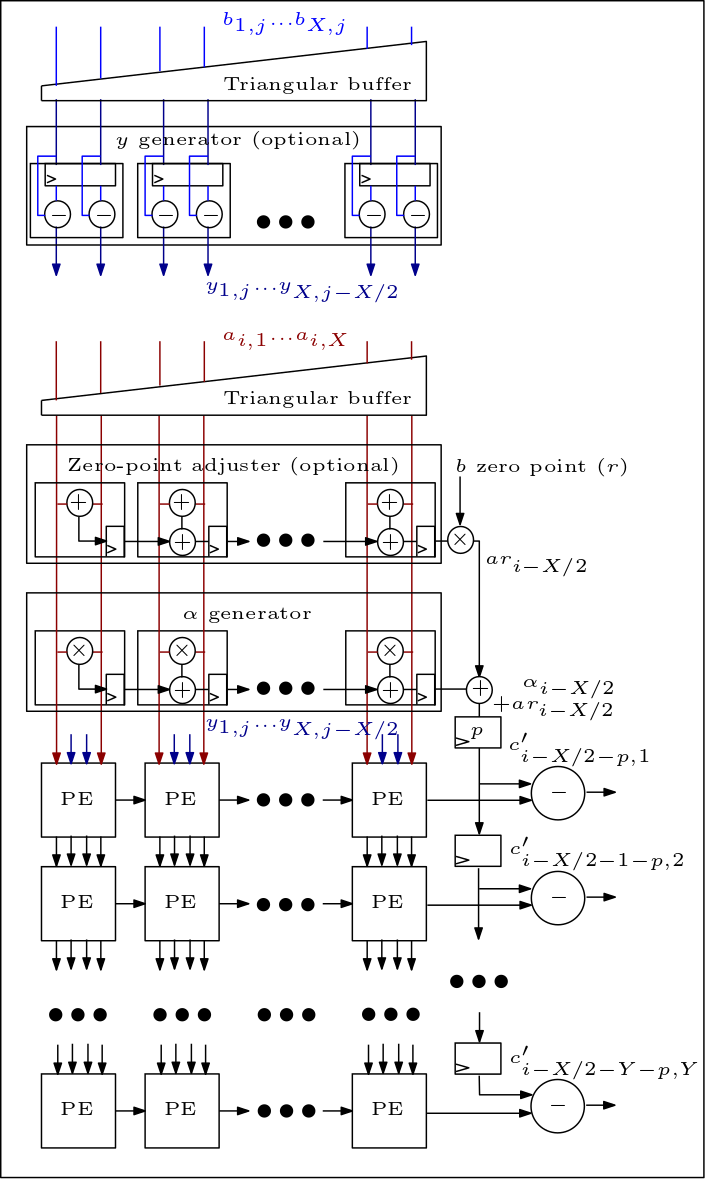
A seguir está um diagrama da matriz MXU/sistólica e mostra como os PEs estão conectados:
A organização do código-fonte é a seguinte:
Os arquivos rtl/top/define.svh e rtl/top/pkg.sv contêm vários parâmetros configuráveis, como FIP_METHOD em define.svh que define o tipo de matriz sistólica (linha de base, FIP ou FFIP), SZI e SZJ que definem a altura/largura da matriz sistólica e LAYERIO_WIDTH/WEIGHT_WIDTH que definem as larguras de bits de entrada.
O diretório rtl/arith inclui mxu.sv e mac_array.sv que contêm o RTL para as arquiteturas de matriz sistólica de linha de base, FIP e FFIP (dependendo do valor do parâmetro FIP_METHOD).


