lumiere pytorch
0.0.24
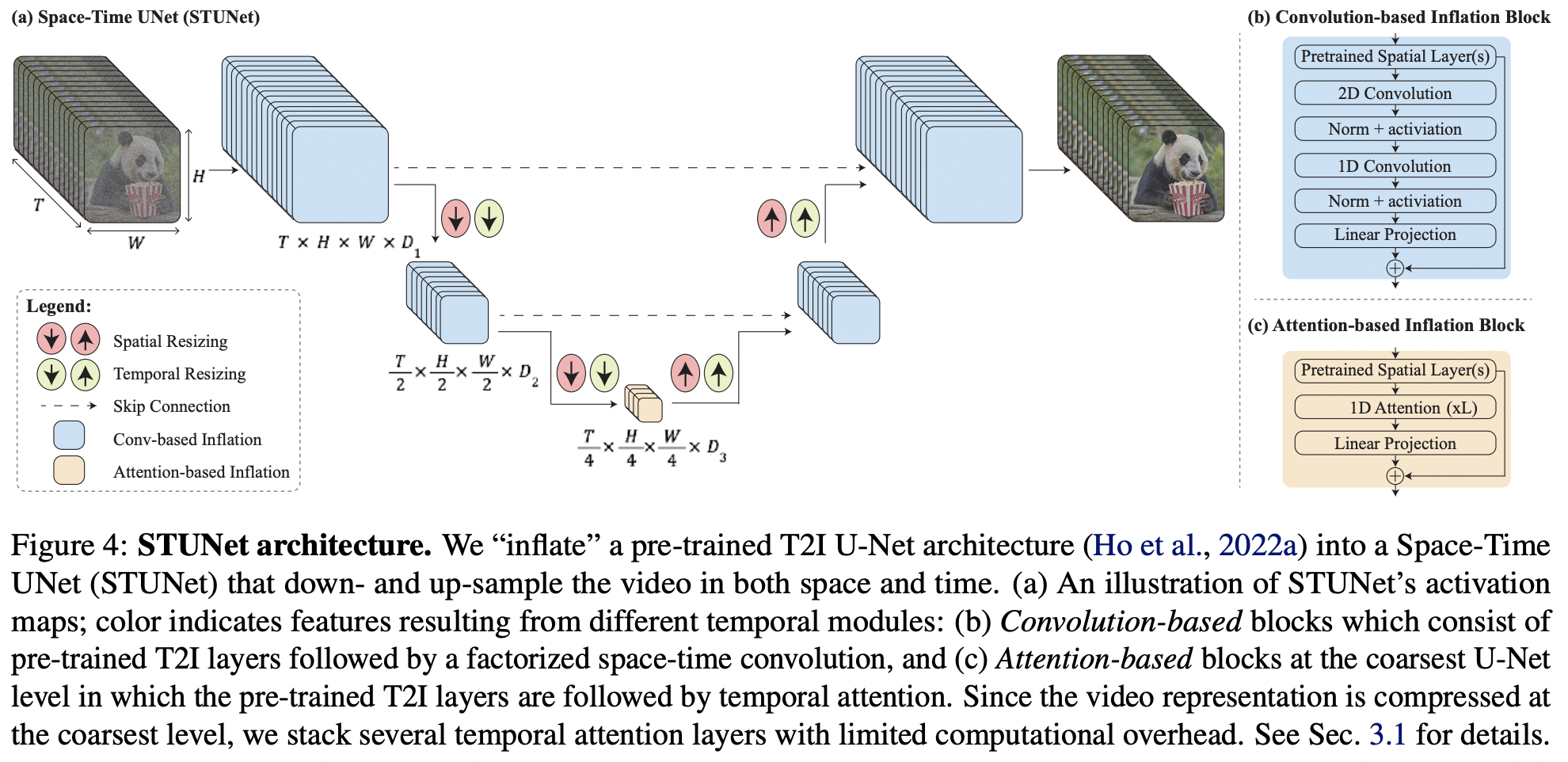
Implementação do Lumiere, geração de texto para vídeo SOTA do Google Deepmind, em Pytorch
Revisão do artigo de Yannic
Como este artigo contém apenas algumas ideias-chave sobre o modelo de texto para imagem, daremos um passo adiante e estenderemos a nova Karras U-net para vídeo neste repositório.
$ pip install lumiere-pytorch import torch
from lumiere_pytorch import MPLumiere
from denoising_diffusion_pytorch import KarrasUnet
karras_unet = KarrasUnet (
image_size = 256 ,
dim = 8 ,
channels = 3 ,
dim_max = 768 ,
)
lumiere = MPLumiere (
karras_unet ,
image_size = 256 ,
unet_time_kwarg = 'time' ,
conv_module_names = [
'downs.1' ,
'ups.1' ,
'downs.2' ,
'ups.2' ,
],
attn_module_names = [
'mids.0'
],
upsample_module_names = [
'ups.2' ,
'ups.1' ,
],
downsample_module_names = [
'downs.1' ,
'downs.2'
]
)
noised_video = torch . randn ( 2 , 3 , 8 , 256 , 256 )
time = torch . ones ( 2 ,)
denoised_video = lumiere ( noised_video , time = time )
assert noised_video . shape == denoised_video . shape adicione todas as camadas temporais
expor apenas parâmetros temporais para aprendizagem, congelar todo o resto
descubra a melhor maneira de lidar com o condicionamento de tempo após a redução da amostragem temporal - em vez da transformação pytree no início, provavelmente será necessário conectar-se a todos os módulos e inspecionar os tamanhos dos lotes
lidar com módulos intermediários que podem ter formato de saída como (batch, seq, dim)
seguindo as conclusões de Tero Karras, improvisar uma variante dos 4 módulos com preservação de magnitude
teste no imagen-pytorch
observe a multidifusão e veja se ela pode se transformar em algum invólucro simples
@inproceedings { BarTal2024LumiereAS ,
title = { Lumiere: A Space-Time Diffusion Model for Video Generation } ,
author = { Omer Bar-Tal and Hila Chefer and Omer Tov and Charles Herrmann and Roni Paiss and Shiran Zada and Ariel Ephrat and Junhwa Hur and Yuanzhen Li and Tomer Michaeli and Oliver Wang and Deqing Sun and Tali Dekel and Inbar Mosseri } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267095113 }
} @article { Karras2023AnalyzingAI ,
title = { Analyzing and Improving the Training Dynamics of Diffusion Models } ,
author = { Tero Karras and Miika Aittala and Jaakko Lehtinen and Janne Hellsten and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2312.02696 } ,
url = { https://api.semanticscholar.org/CorpusID:265659032 }
}

