toyCarIRL
1.0.0
A aprendizagem por reforço (RL) é a forma mais básica e intuitiva de aprendizagem por tentativa e erro, é a maneira pela qual a maioria dos organismos vivos com alguma forma de capacidade de pensamento aprende. Muitas vezes referida como aprendizagem por exploração, é a forma pela qual um bebé humano recém-nascido aprende a dar os primeiros passos, ou seja, realizando inicialmente ações aleatórias e depois lentamente descobrindo as ações que levam ao movimento de caminhar para a frente.
Observe que esta postagem pressupõe um bom entendimento da estrutura de aprendizagem por reforço. Familiarize-se com RL durante as semanas 5 e 6 deste incrível curso online AI_Berkeley.
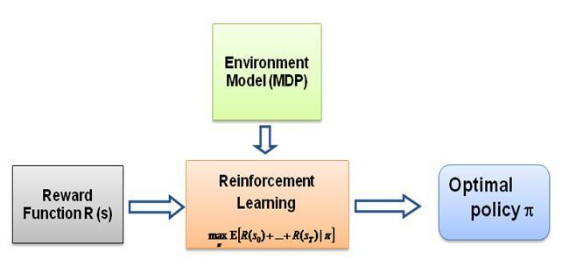
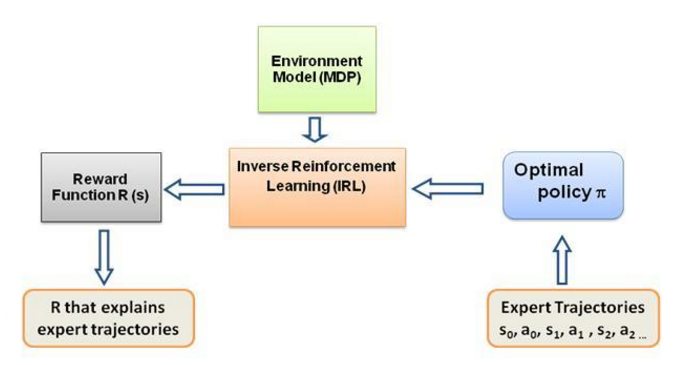
Agora, a questão que sempre me pergunto é: qual é a força motriz deste tipo de aprendizagem, o que obriga o agente a aprender um determinado comportamento da forma como o faz. Ao aprender mais sobre RL me deparei com a ideia de recompensas , basicamente o agente tenta escolher suas ações de forma que as recompensas obtidas por aquele determinado comportamento sejam maximizadas. Agora, para fazer com que o agente execute comportamentos diferentes, é a estrutura de recompensa que se deve modificar/explorar. Mas suponha que tenhamos apenas o conhecimento do comportamento do especialista que está conosco, então como estimamos a estrutura de recompensa dado um comportamento específico no ambiente? Bem, este é o próprio problema da Aprendizagem por Reforço Inverso (IRL) , onde dada a política especializada ideal (na verdade assumida como ótima), desejamos determinar a estrutura de recompensa subjacente.
Novamente, esta não é uma postagem de introdução ao aprendizado por reforço inverso, mas sim um tutorial sobre como usar/codificar a estrutura de aprendizado por reforço inverso para o seu próprio problema, mas IRL está no centro dele, e é essencial saber sobre primeiro. A IRL foi extensivamente estudada no passado e algoritmos foram desenvolvidos para isso. Consulte os artigos Ng e Russell, 2000, e Abbeel e Ng, 2004 para obter mais informações.
Este post adapta o algoritmo de Abbeel e Ng, 2004 para resolver o problema IRL.
A ideia aqui é programar um agente simples em um mundo 2D cheio de obstáculos para copiar/clonar diferentes comportamentos no ambiente, os comportamentos são inseridos com a ajuda de trajetórias especializadas fornecidas manualmente por um especialista humano/computador. Esta forma de aprendizagem a partir de demonstrações de especialistas é chamada de Aprendizagem por Aprendizagem na literatura científica, no centro dela está a Aprendizagem por Reforço inversa, e estamos apenas tentando descobrir as diferentes funções de recompensa para esses diferentes comportamentos.
Em geral sim, são a mesma coisa, o que significa aprender com a demonstração (LfD). Ambos os métodos aprendem com a demonstração, mas aprendem coisas diferentes:
A aprendizagem por aprendizagem por meio da aprendizagem por reforço inverso tentará inferir o objetivo do professor . Em outras palavras, ele aprenderá uma função de recompensa a partir da observação, que poderá então ser usada no aprendizado por reforço. Se descobrir que o objetivo é acertar um prego com um martelo, ignorará piscadas e arranhões do professor, pois são irrelevantes para o objetivo.
A aprendizagem por imitação (também conhecida como clonagem comportamental) tentará copiar diretamente o professor . Isto pode ser conseguido apenas através da aprendizagem supervisionada. A IA tentará copiar todas as ações, mesmo ações irrelevantes como piscar ou coçar, por exemplo, ou mesmo erros. Você também poderia usar RL aqui, mas apenas se tiver uma função de recompensa.
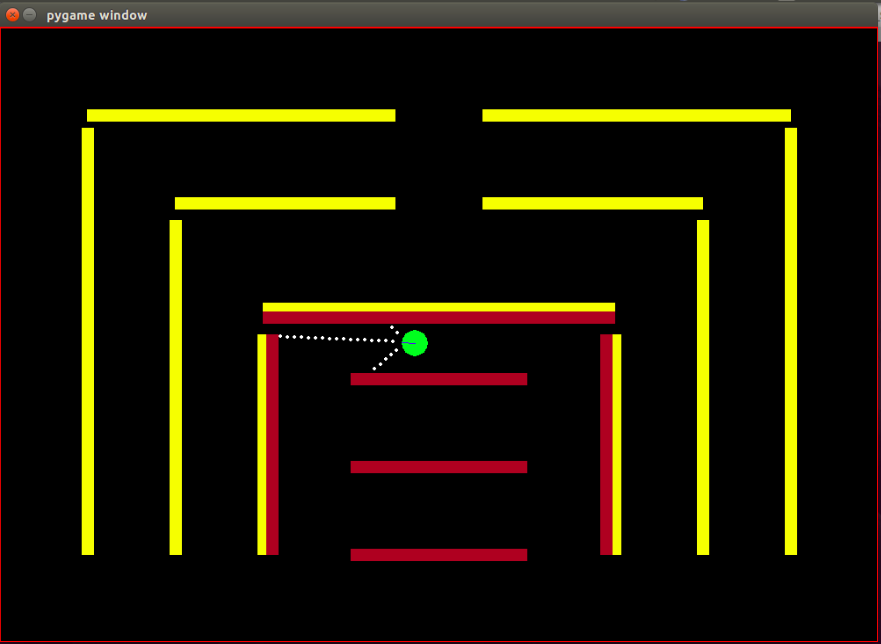
Agente: o agente é um pequeno círculo verde com sua direção indicada por uma linha azul.
Sensores: o agente é equipado com 3 sensores de distância e cor, sendo esta a única informação que o agente possui sobre o ambiente.
Espaço de estados: o estado do agente consiste em 8 características observáveis-
Observe que a normalização é feita para garantir que cada valor de recurso observável esteja no intervalo [0,1], que é uma condição necessária para as recompensas para a convergência do algoritmo IRL.
Recompensas: a recompensa após cada quadro é calculada como uma combinação linear ponderada dos valores dos recursos observados naquele respectivo quadro. Aqui, a recompensa r_t no t-ésimo quadro é calculada pelo produto escalar do vetor de peso w com o vetor de valores de recursos no t-ésimo quadro, que é o vetor de estado phi_t. Tal que r_t = w^T x phi_t.
Ações disponíveis: a cada novo quadro, o agente automaticamente dá um passo para frente , as ações disponíveis podem virar o agente para a esquerda , para a direita ou não fazer nada que seja um simples passo para frente, observe que as ações de giro também incluem o movimento para frente, é não é uma rotação no local.
Obstáculos: o ambiente é composto por paredes rígidas, coloridas deliberadamente em cores diferentes. O agente possui capacidades de detecção de cores que o ajudam a distinguir entre os tipos de obstáculos. O ambiente é projetado desta forma para facilitar o teste do algoritmo IRL.
A posição inicial (estado) do bot é fixa, pois de acordo com o algoritmo IRL é necessário que o estado inicial seja o mesmo para todas as iterações.
Observe que o algoritmo RL foi totalmente adotado neste post de Matt Harvey com pequenas alterações, portanto, faz todo o sentido falar sobre as alterações que fiz, mesmo que o leitor esteja confortável com RL, recomendo fortemente uma olhada. essa postagem para entender como o aprendizado por reforço está ocorrendo.
O ambiente é significativamente alterado, com o agente adquirindo a capacidade não só de sentir a distância dos 3 sensores, mas também de sentir a cor dos obstáculos, permitindo-lhe distinguir entre os obstáculos. Além disso, o agente agora é menor em tamanho e seus pontos de detecção estão mais próximos para obter mais resolução e melhor desempenho. Os obstáculos tiveram que ser tornados estáticos por enquanto, a fim de simplificar o processo de teste do algoritmo IRL, isso pode muito bem levar ao overfitting dos dados, mas não estou preocupado com isso no momento. Conforme discutido acima, o conjunto de observações ou o estado do agente foi aumentado de 3 para 8, com a inclusão do recurso de travamento no estado do agente. A estrutura de recompensa foi completamente alterada, a recompensa agora é uma combinação linear ponderada desses 8 recursos, o agente não recebe mais uma recompensa de -500 ao esbarrar em obstáculos, em vez disso, o valor do recurso para esbarrar é +1 e não esbarrar é 0 e cabe ao algoritmo decidir qual peso deve ser atribuído a esse recurso com base no comportamento do especialista.
Conforme declarado no blog de Matt, o objetivo aqui não é apenas ensinar o agente RL a evitar obstáculos, quero dizer, por que assumir qualquer coisa sobre a estrutura de recompensa, deixar a estrutura de recompensa ser completamente decidida pelo algoritmo das demonstrações de especialistas e ver qual comportamento uma configuração específica de recompensas é alcançada!
Os recursos ou funções básicas phi_i que são basicamente observáveis no estado. Os recursos do problema atual são discutidos acima na seção de espaço de estados. Definimos phi(s_t) como a soma de todas as expectativas de recursos phi_i tais que:
Recompensas r_t - combinação linear desses valores de recursos observados em cada estado s_t.
Expectativas de recursos mu(pi) de uma política pi é a soma dos valores de recursos descontados phi(s_t).
As expectativas de características de uma política são independentes dos pesos, dependem apenas dos estados visitados durante a execução (de acordo com a política) e do fator de desconto gama, um número entre 0 e 1 (por exemplo, 0,9 no nosso caso). Para obter as expectativas das características de uma política temos que executar a política em tempo real com o agente e registrar os estados visitados e os valores das características obtidos.
As expectativas de características da política do especialista ou as expectativas das características do especialista mu(pi_E) são obtidas pelas ações que são tomadas de acordo com o comportamento do especialista. Basicamente, executamos esta política e obtemos as expectativas dos recursos como fazemos com qualquer outra política. As expectativas de recursos do especialista são fornecidas ao algoritmo IRL para encontrar os pesos de modo que a função de recompensa correspondente aos pesos se assemelhe à função de recompensa subjacente que o especialista está tentando maximizar (na linguagem RL usual).
Expectativas de recursos de política aleatória - execute uma política aleatória e use as expectativas de recursos obtidas para inicializar o IRL.
Mantenha uma lista das expectativas de recursos de política que obtemos após cada iteração.
No início, temos apenas pi^1 -> as expectativas do recurso de política aleatória.
Encontre o primeiro conjunto de pesos de w ^ 1 por otimização convexa, o problema é semelhante a um classificador SVM que tenta dar um rótulo +1 ao recurso especialista esperado. e -1 rótulo para todas as outras expectativas de recursos de política.-
tal que,
Condição de rescisão:
Agora, uma vez obtidos os pesos após uma iteração de otimização, ou seja, uma vez obtida uma nova função de recompensa, temos que aprender a política que esta função de recompensa dá origem. Isto é o mesmo que dizer: encontre uma política que tente maximizar esta função de recompensa obtida. Para encontrar esta nova política, temos que treinar o algoritmo de Aprendizagem por Reforço com esta nova função de recompensa e treiná-lo até que os valores Q convirjam, para obter uma estimativa adequada da política.
Depois de aprendermos uma nova política, temos que testá-la online, a fim de obter as expectativas de recursos correspondentes a esta nova política. Em seguida, adicionamos essas novas expectativas de recursos à nossa lista de expectativas de recursos e continuamos com a próxima iteração do algoritmo IRL até a convergência.
Vamos agora tentar entender o código. Encontre o código completo neste repositório git. Existem principalmente três arquivos com os quais você precisa se preocupar -
manualControl.py - para obter as expectativas de recursos do especialista movendo manualmente o agente. Execute "python3 manualControl.py", espere a interface gráfica carregar e use as teclas de seta para começar a se mover. Dê a ele o comportamento que você deseja copiar (observe que o comportamento que você espera que ele copie deve ser razoável com o espaço de estados fornecido). Um bom truque seria assumir-se no lugar do agente e pensar se você será capaz de distinguir o comportamento dado apenas no espaço de estados atual. Veja o arquivo de origem para mais detalhes.
toy_car_IRL.py - o arquivo principal, é onde fica o código IRL. Vamos dar uma olhada no código passo a passo-
{% essência 51542f27e97eac1559a00f06b757df1a %}
Importe dependências e defina os parâmetros importantes, altere o BEHAVIOR conforme necessário. FRAMES são o número de quadros que você deseja que o algoritmo RL execute. 100K está bom e leva cerca de 2 horas.
{% essência 49b602b9a3090773d492310175bb2e3f %}
Crie a classe irlAgent fácil de usar, que considera os comportamentos aleatórios e especializados e outros parâmetros importantes, conforme mostrado.
{% essência bc17c06a07ea3b915827e89f3c13a2ae %}
A função getRLAgentFE usa o IRL_helper do aluno de reforço para treinar um novo modelo e obter expectativas de recursos reproduzindo esse modelo por 2.000 iterações. Basicamente, ele retorna as expectativas de recursos para cada conjunto de pesos (W) obtido.
{% essência ce0ef99adc652c7469f1bc4303a3af41 %}
Atualizar o dicionário no qual guardamos as políticas obtidas e seus respectivos valores t. Onde t = (pesos.tanspose)x(expert-newPolicy).
{% essência be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
A implementação do algoritmo IRL principal, discutido acima. {% essência 9faee18596467ee33ac5d91fd0cb675f %}
A otimização convexa para atualizar os pesos ao receber uma nova política, basicamente atribui rótulo +1 à política especializada e rótulo -1 a todas as outras políticas e otimiza para os pesos sob as restrições mencionadas. Para saber mais sobre esta otimização visite o site
{% essência 30cf6c59b9915054f3cf6d278f8f8a11 %}
Crie um irlAgent e passe os parâmetros desejados, selecione o tipo de comportamento especialista para o qual deseja aprender os pesos e, em seguida, execute a função optimWeightFinder(). Observe que já obtive as expectativas de recursos para comportamentos vermelhos, amarelos e marrons. Após o término do algoritmo, você obterá uma lista de pesos em 'weights-red/yellow/brown.txt', com o respectivo BEHAVIOR selecionado. Agora, para selecionar o melhor comportamento possível de todos os pesos obtidos, reproduza os modelos salvos no diretório save-models_BEHAVIOR/evaluatedPolicies/, os modelos são salvos no seguinte formato 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+ número de iteração+ '-164-150-100-50000-100000' + '.h5' . Basicamente você obterá pesos diferentes para diferentes iterações, primeiro jogue os modelos para descobrir o modelo com melhor desempenho, depois anote o número da iteração desse modelo, os pesos obtidos correspondentes a esse número de iteração são os pesos que o aproximam mais do especialista comportamento.
E há arquivos que você provavelmente não precisa atualizar/modificar, pelo menos para o conteúdo deste post -
Após cerca de 10 a 15 iterações, o algoritmo converge em todos os 4 comportamentos diferentes escolhidos, obtive os seguintes resultados:
| Pesos | eu amo amarelo | Eu amo marrom | Eu amo vermelho | Eu adoro bater |
|---|---|---|---|---|
| w1 (Distância do sensor esquerdo) | -0,0880 | -0,2627 | 0,2816 | -0,5892 |
| w2 (distância do sensor intermediário) | -0,0624 | 0,0363 | -0,5547 | -0,3672 |
| w3 (distância do sensor direito) | 0,0914 | 0,0931 | -0,2297 | -0,4660 |
| w4 (cor preta) | -0,0114 | 0,0046 | 0,6824 | -0,0299 |
| w5 (cor amarela) | 0,6690 | -0,1829 | -0,3025 | -0,1528 |
| w6 (cor marrom) | -0,0771 | 0,6987 | 0,0004 | -0,0368 |
| w7 (cor vermelha) | -0,6650 | -0,5922 | 0,0525 | -0,5239 |
| w8 (falha) | -0,2897 | -0,2201 | -0,0075 | 0,0256 |
Um valor negativo alto é atribuído ao peso pertencente ao recurso de colisão nos três primeiros comportamentos, pois esses 3 comportamentos especialistas não querem que o agente esbarre em obstáculos. Já o peso para o mesmo recurso no último comportamento, ou seja, o bot Nasty, é positivo, pois o comportamento especialista defende o bumping.
Aparentemente, os pesos para os recursos de cor são relativos ao comportamento do especialista, altos quando essa cor é desejada, caso contrário, um valor bastante baixo/negativo para obter um comportamento distinto.
Os pesos do recurso de distância são muito ambíguos (contra-intuitivos) e é muito difícil descobrir algum padrão significativo nos pesos. A única coisa que quero ressaltar é que é até possível distinguir comportamentos no sentido horário e anti-horário na configuração atual, os recursos de distância carregarão essa informação.
Observe que é muito importante pensar primeiro se você, como ser humano, será capaz de distinguir entre os comportamentos determinados e a disponibilidade do conjunto de estado atual (as observações) ao projetar a estrutura do problema. Caso contrário, você pode estar apenas forçando o algoritmo a encontrar pesos diferentes, sem fornecer todas as informações necessárias.
Se você realmente deseja entrar na IRL, eu recomendaria que você realmente tentasse ensinar ao agente um novo comportamento (talvez seja necessário modificar o ambiente para isso, pois os possíveis comportamentos distintos para o conjunto de estado atual já foram explorados, bem pelo menos de acordo comigo).
Instale as dependências do Pygame com:
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
Em seguida, instale o próprio Pygame:
pip3 install hg+http://bitbucket.org/pygame/pygame
Este é o mecanismo de física usado pela simulação. Ele acabou de passar por uma reescrita bastante significativa (v5), então você precisa pegar a versão v4 mais antiga. v4 foi escrito para Python 2, portanto, há algumas etapas extras.
Volte para sua casa ou faça download e obtenha o Pymunk 4:
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
Descompacte:
tar zxvf pymunk-4.0.0.tar.gz
Atualização do Python 2 para 3:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
Instale-o:
cd .. python3 setup.py install
Agora volte para onde você clonou reinforcement-learning-car e certifique-se de que tudo funcionou com um rápido python3 learning.py . Se você vir uma tela com um pequeno ponto voando ao redor da tela, você está pronto para começar!
Primeiro, você precisa treinar um modelo. Isso salvará os pesos na pasta saved-models . Pode ser necessário criar esta pasta antes de executar o . Você pode treinar o modelo executando:
python3 learning.py
O treinamento de um modelo pode levar de uma hora a 36 horas, dependendo da complexidade da rede e do tamanho da sua amostra. No entanto, ele cuspirá pesos a cada 25.000 quadros, para que você possa passar para a próxima etapa em muito menos tempo.
Edite o arquivo playing.py para alterar o nome do caminho do modelo que deseja carregar. Desculpe por isso, sei que deveria ser um argumento de linha de comando.
Depois, observe o carro contornar os obstáculos!
python3 playing.py
Isso é tudo que há para fazer.


