Extendible Hashing for DBMS
1.0.0
Uma implementação de baixo nível de hashing extensível para sistemas de banco de dados.
Este método usa diretórios e buckets para fazer hash de dados e é amplamente conhecido por sua flexibilidade e eficiência no tempo de computação.
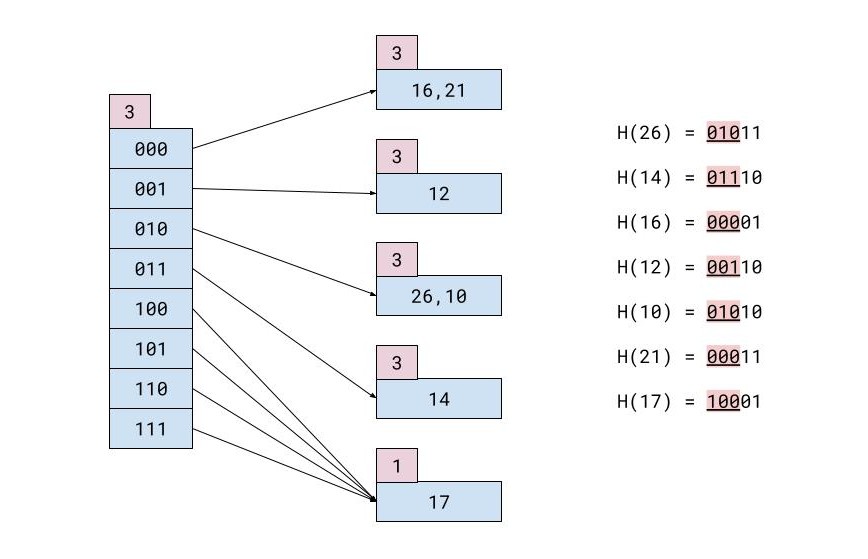
Por exemplo, você tem esta tabela de registros:
| EU IA | NOME | SOBRENOME | CIDADE |
|---|---|---|---|
| 26 | Maria | Koronis | Hong Kong |
| 14 | Cristoforos | Gaitanis | Tóquio |
| 16 | Mariana | Karvounari | Miami |
| 12 | Teófilo | Nikolopoulos | Londres |
| 10 | Iosif | Svingos | Tóquio |
| 21 | Teófilo | Michas | Atenas |
| 17 | Giorgos | Halatsis | Munique |
Se cada bloco de memória puder ter apenas 2 registros o arquivo hash após todas as inserções ficará assim:
O programa pode ser executado por duas funções principais diferentes. Este primeiro insere um grande número de registros em um arquivo e o segundo cria e insere registros em três arquivos diferentes simultaneamente.
teste_main1:
make main1
./build/runner
teste_main2:
make main2
./build/runner