WeClone
1.0.0
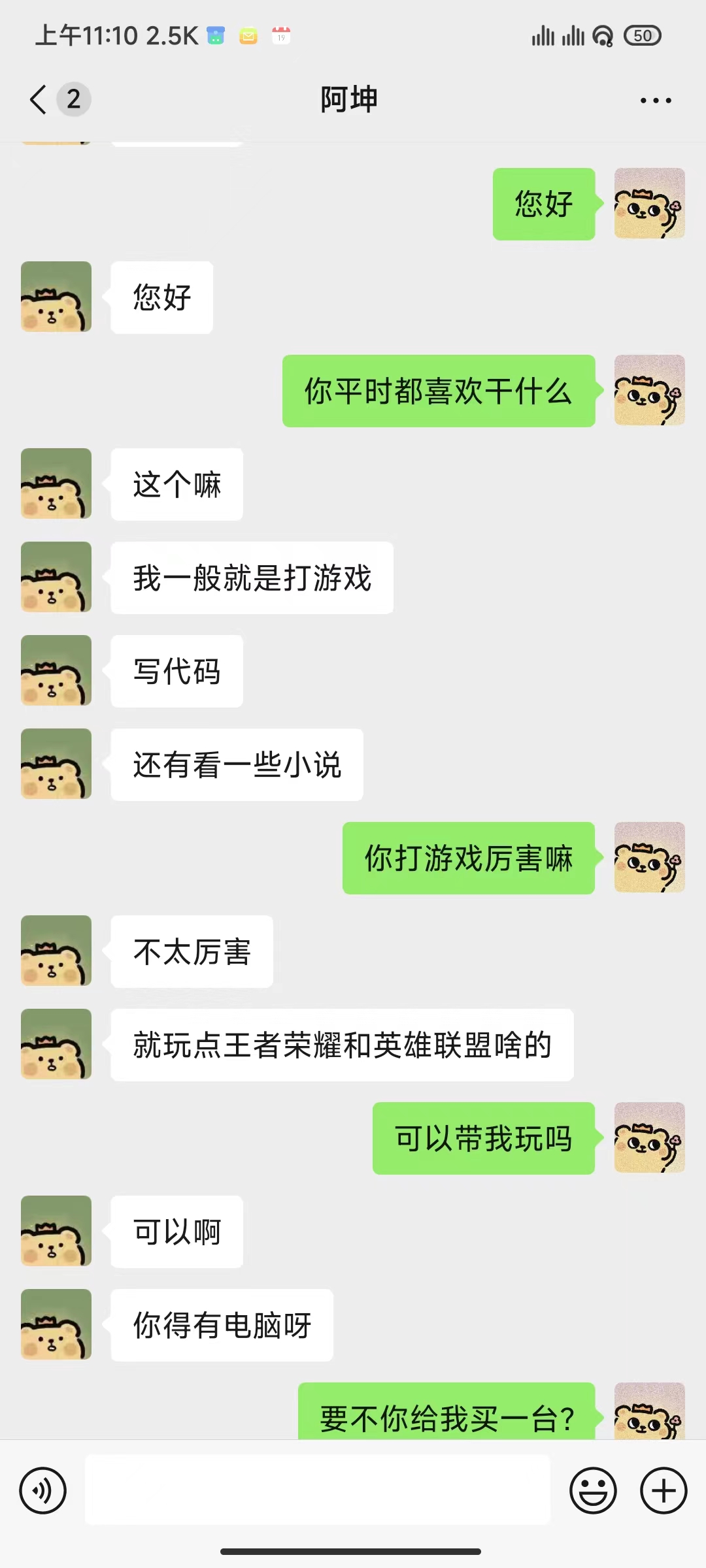
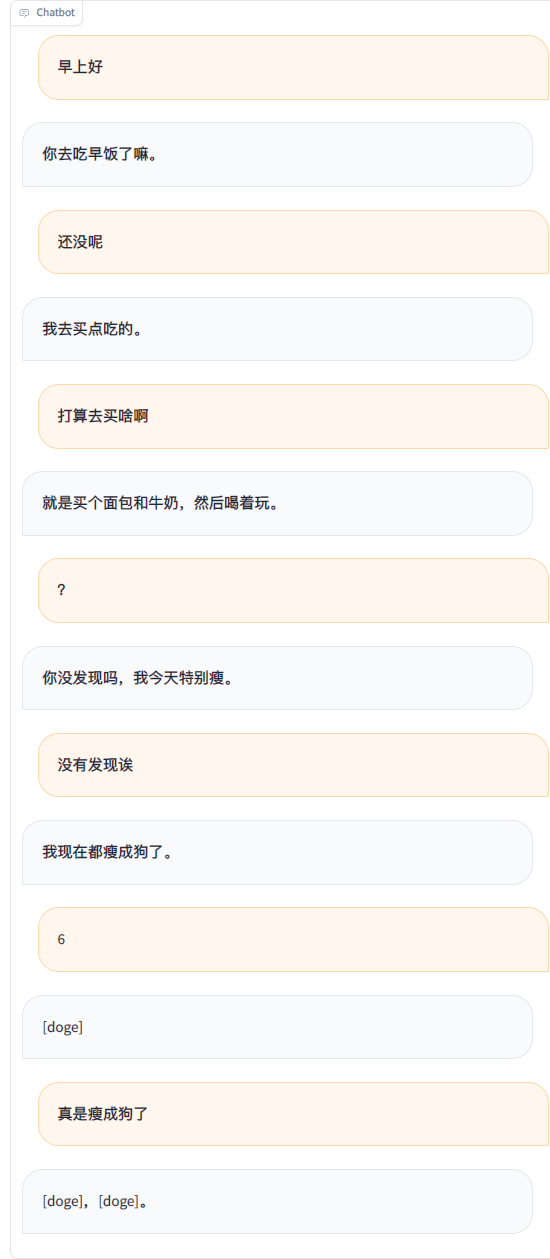
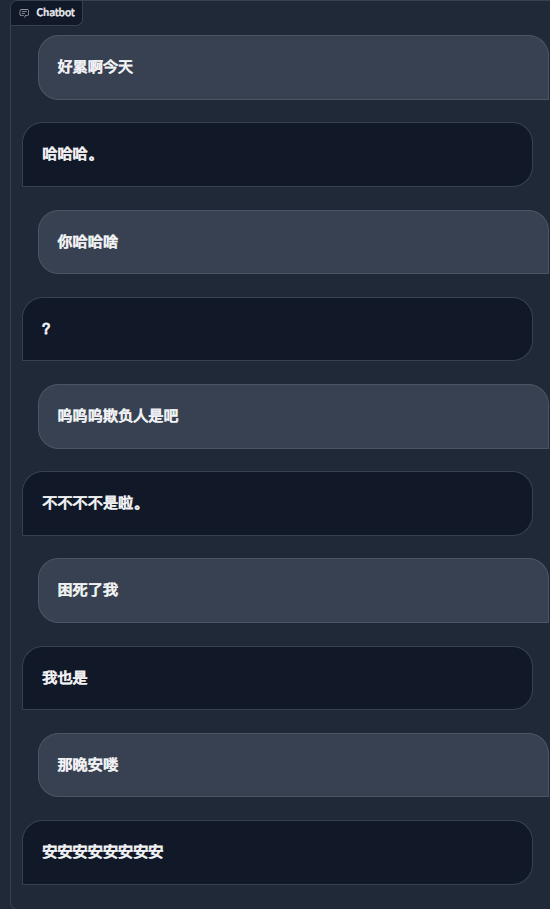
Usando registros de bate-papo do WeChat para ajustar um grande modelo de linguagem, usei cerca de 20.000 dados integrados e eficazes. O resultado final só pode ser considerado insatisfatório, mas às vezes é muito engraçado.
Importante
Atualmente, o projeto usa o modelo chatglm3-6b por padrão, e o método LoRA é usado para ajustar o estágio sft, que requer aproximadamente 16 GB de memória de vídeo. Você também pode usar outros modelos e métodos suportados pelo LLaMA Factory, que ocupam menos memória de vídeo. Você mesmo precisa modificar as palavras de prompt do sistema do modelo e outras configurações relacionadas.
Requisitos estimados de memória de vídeo:
| método de treinamento | Precisão | 7B | 13B | 30B | 65B | 8x7B |
|---|---|---|---|---|---|---|
| Parâmetros completos | 16 | 160 GB | 320 GB | 600 GB | 1200 GB | 900 GB |
| Alguns parâmetros | 16 | 20 GB | 40 GB | 120 GB | 240 GB | 200 GB |
| LoRa | 16 | 16 GB | 32 GB | 80 GB | 160 GB | 120 GB |
| QLoRA | 8 | 10 GB | 16 GB | 40 GB | 80 GB | 80 GB |
| QLoRA | 4 | 6 GB | 12 GB | 24 GB | 48 GB | 32 GB |
| Obrigatório | Pelo menos | recomendar |
|---|---|---|
| píton | 3.8 | 3.10 |
| tocha | 1.13.1 | 2.2.1 |
| transformadores | 4.37.2 | 4.38.1 |
| conjuntos de dados | 2.14.3 | 2.17.1 |
| acelerar | 0.27.2 | 0.27.2 |
| peft | 0.9.0 | 0.9.0 |
| trl | 0.7.11 | 0.7.11 |
| Opcional | Pelo menos | recomendar |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| velocidade profunda | 0.10.0 | 0.13.4 |
| bits e bytes | 0,39,0 | 0.41.3 |
| flash-attn | 2.3.0 | 2.5.5 |
git clone https://github.com/xming521/WeClone.git
conda create -n weclone python=3.10
conda activate weclone
cd WeClone
pip install -r requirements.txtAs configurações relacionadas ao treinamento e à inferência são unificadas no arquivo settings.json
Use PyWxDump para extrair registros de bate-papo do WeChat. Depois de baixar o software e descriptografar o banco de dados, clique em Backup de bate-papo. O tipo de exportação é CSV. Você pode exportar vários contatos ou bate-papos em grupo. Em seguida, coloque a pasta csv exportada localizada em wxdump_tmp/export no diretório ./data . As pastas de registros de bate-papo das pessoas são colocadas juntas em ./data/csv . Os dados de exemplo estão localizados em data/example_chat.csv.
Por padrão, o projeto remove dos dados números de telefone celular, números de identificação, endereços de e-mail e endereços de sites. Ele também fornece um banco de dados de palavras proibidas, Block_words, onde você pode adicionar palavras e frases que precisam ser filtradas (a frase inteira, incluindo as palavras banidas, será removida por padrão). Execute o script ./make_dataset/csv_to_json.py para processar os dados.
Quando a mesma pessoa responde várias frases seguidas, há três maneiras de lidar com isso:
| documento | Método de processamento |
|---|---|
| csv_to_json.py | Conecte-se com vírgulas |
| csv_to_json-frase única answer.py (obsoleto) | Apenas as respostas mais longas são selecionadas como dados finais |
| csv_to_json-frase única múltiplas rodadas.py | Colocado no 'histórico' da palavra prompt |
A primeira opção é baixar o modelo ChatGLM3 do Hugging Face. Se você encontrar problemas para baixar o modelo Hugging Face, poderá usar a comunidade MoDELSCOPE por meio dos métodos a seguir. Para treinamento e inferência subsequentes, você precisará executar export USE_MODELSCOPE_HUB=1 primeiro para usar o modelo da comunidade MoDELSCOPE.
Devido ao grande tamanho do modelo, o processo de download demorará muito, por favor, seja paciente.
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git(Opcional) Modifique settings.json para selecionar outros modelos baixados localmente.
Modifique per_device_train_batch_size e gradient_accumulation_steps para ajustar o uso da memória de vídeo.
Você pode modificar parâmetros como num_train_epochs , lora_rank , lora_dropout de acordo com a quantidade e qualidade do seu próprio conjunto de dados.
Execute src/train_sft.py para ajustar o estágio sft. Minha perda caiu apenas para cerca de 3,5. Se for muito reduzida, pode causar ajuste excessivo.
python src/train_sft.pypip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.pyObservação
Você também pode ajustar o estágio pt primeiro. Parece que o efeito de melhoria não é óbvio. O armazém também fornece o código para pré-processamento e treinamento do conjunto de dados do estágio pt.
python ./src/web_demo.py python ./src/api_service.pypython ./src/api_service.py
python ./src/test_model.pyImportante
Existe o risco de encerramento da conta no WeChat. Recomenda-se o uso de uma conta pequena e é necessário vincular um cartão bancário para utilizá-la.
python ./src/api_service.py # 先启动api服务
python ./src/wechat_bot/main.py Por padrão, o código QR é exibido no terminal, basta escanear o código para fazer login. Pode ser usado em chat privado ou em chat em grupo @bot.

Pendência
Pendência


