liuli
v0.2.0
Apenas explique brevemente:
Coletor : monitora fontes de leitura personalizadas, como contas públicas, livros ou fontes de blogs que eles seguem, e flui para Liuli em um formato padrão unificado como fonte de entrada;
Processador : personalize o conteúdo de destino, como usar aprendizado de máquina para rotular automaticamente um classificador de publicidade com base em dados históricos de publicidade ou introduzir funções de gancho para execução em nós relevantes;
Distribuidor : depende da camada de interface para realizar solicitações e respostas de dados, fornece aos usuários configurações personalizadas e, em seguida, distribui automaticamente de acordo com a configuração, fluindo artigos limpos para clientes WeChat, DingTalk, TG, RSS e até mesmo sites de construção própria;
Backer : Faça backup dos artigos processados, como persisti-los em um banco de dados ou GitHub, etc.
Isso permite a construção de um ambiente de leitura limpo. Há muitas coisas que podem ser feitas com base nos dados obtidos. Você pode querer divulgar suas ideias.
Painel de progresso de desenvolvimento:
v0.2.0: Implementar funções básicas para garantir que soluções para cenários comuns possam ser aplicadas
v0.3.0: Implemente a personalização do coletor, os usuários podem coletar o que veem
Para melhorar a precisão do reconhecimento do modelo, espero que todos possam contribuir com alguns exemplos de publicidade. Consulte o arquivo de exemplo: .files/datasets/ads.csv.
| título | url | é_processo |
|---|---|---|
| Título do artigo publicitário | Link do artigo publicitário | 0 |
Descrição do campo:
título: título do artigo
url: link do artigo Se você quiser usar o artigo do WeChat, verifique primeiro se ele é inválido.
is_process: Indica se deve realizar o processamento de amostra. Preencha 0 por padrão.
Vamos dar um exemplo:
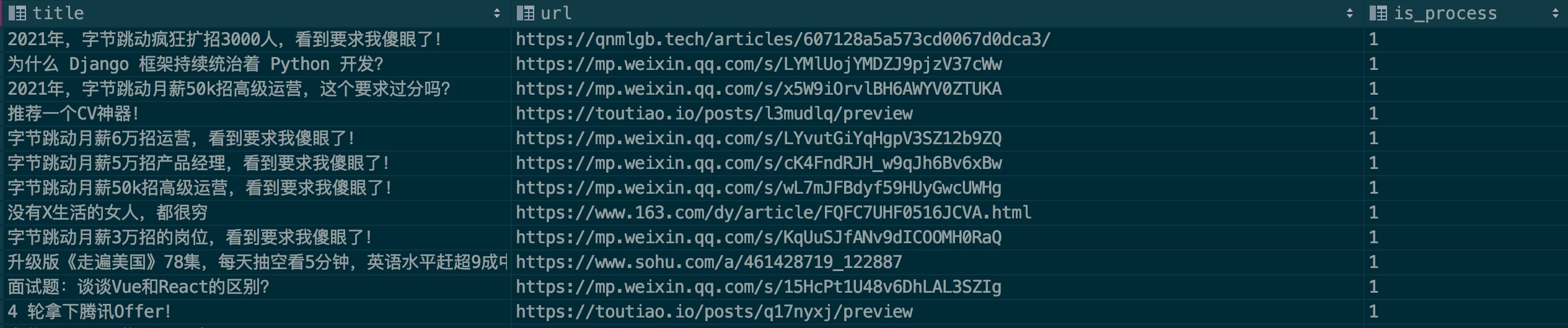
Geralmente, os anúncios serão colocados repetidamente em várias contas públicas. Por favor, verifique se este registro existe ao preenchê-lo. Espero que todos possam trabalhar juntos para contribuir.
Graças aos seguintes projetos de código aberto:
Frasco: estrutura da web
Vue: estrutura JavaScript progressiva
Ruia: estrutura de rastreador assíncrono (desenvolvida e usada)
dramaturgo: Extração de dados usando o navegador
O texto acima lista apenas as principais dependências de código aberto. Para mais dependências de terceiros, consulte o arquivo Pipfile.
Qualquer PR que você receber é um forte apoio ao projeto Liuli . Somos muito gratos aos seguintes desenvolvedores por suas contribuições (sem ordem específica):
Bem-vindo para se comunicarem juntos (siga o grupo):


