ChatGPT WechatBot using OpenAI API via Wechty
1.0.0
ChatGPT-WechatBot é um robô semelhante ao chatGPT implementado usando o modelo de diálogo baseado na API oficial OpenAI e é implantado no WeChat por meio da estrutura Wechaty para realizar o bate-papo do robô.
ChatGPT WechatBot é uma espécie de robô chatGPT baseado na API oficial OpenAI e usando o modelo de diálogo. Ele é implantado no WeChat por meio da estrutura Wechat para obter bate-papo do robô.
Nota : Este projeto é uma implementação local do Win10 e não requer implantação de servidor (se a implantação de servidor for necessária, você pode implantar o docker no servidor)
(1), janelas10
(2), Docker 20.10.21
(3), Python3.9
(4), Wechaty 0.10.7
1. Baixe o Docker
https://www.docker.com/products/docker-desktop/ Baixe o Docker
2. Ative a virtualização Win10
Digite control no cmd para abrir o painel de controle e entrar no programa, conforme mostrado na figura abaixo:
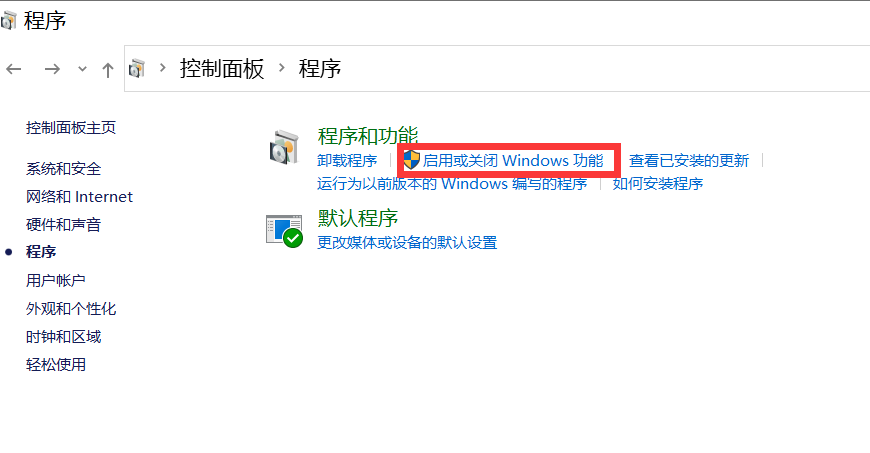
Vá para Ativar ou desativar recursos do Windows e ativar o Hyper-V
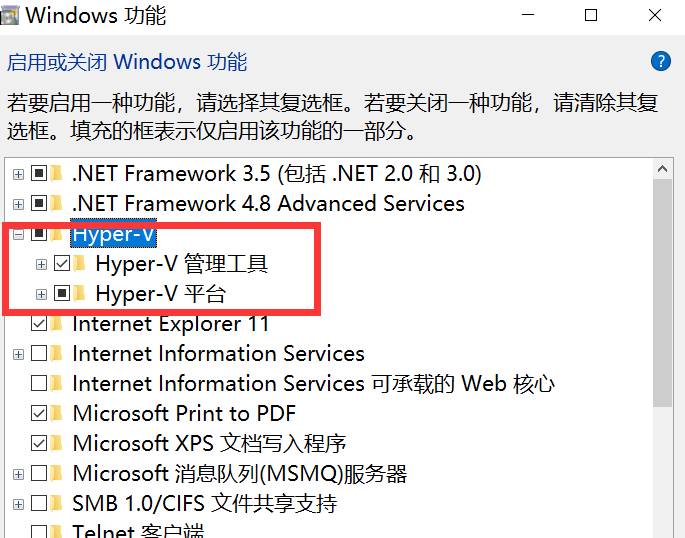
Nota : Se o seu computador não tiver Hyper-V, você precisará realizar as seguintes operações:
Crie um documento de texto, preencha o código a seguir e nomeie-o como Hyper.cmd
pushd " %~dp0 "
dir /b %SystemRoot% s ervicing P ackages * Hyper-V * .mum > hyper-v.txt
for /f %%i in ( ' findstr /i . hyper-v.txt 2^>nul ' ) do dism /online /norestart /add-package: " %SystemRoot%servicingPackages%%i "
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALLEm seguida, execute este arquivo como administrador. Após a conclusão da execução do script, haverá um nó Hyper-V após reiniciar o computador.
3. Execute o Docker
Nota : Se ocorrer o seguinte ao executar o Docker pela primeira vez:
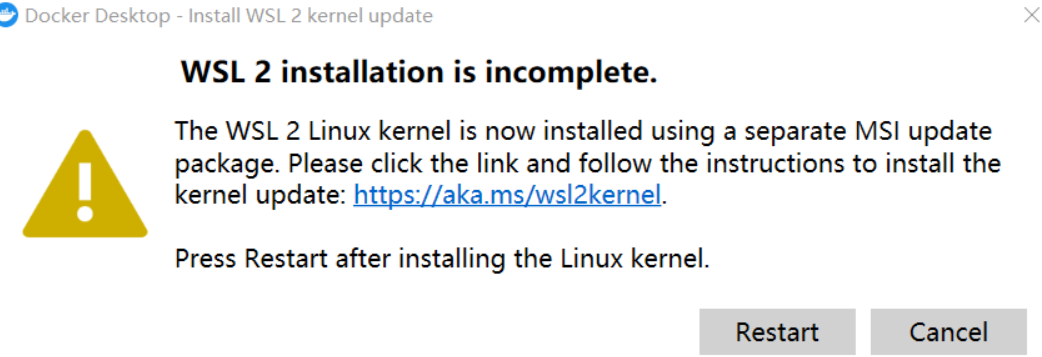
Precisa baixar o pacote WSL 2 mais recente
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
Após a atualização, você pode entrar na página principal, alterar as configurações no mecanismo docker e substituir a imagem pela imagem doméstica do Alibaba Cloud:
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"insecure-registries": [],
"registry-mirrors": [
"https://9cpn8tt6.mirror.aliyuncs.com"
]
}Desta forma, é mais rápido retirar o espelho (para usuários domésticos)
4. Extraia a imagem Wechaty :
docker pull wechaty:0 . 65Porque durante os testes, descobriu-se que a versão 0.65 do wechaty é a mais estável
Depois de puxar a imagem:
Puppet : Se você deseja usar o Wechaty para desenvolver um robô WeChat, você precisa usar um middleware Puppet para controlar a operação do WeChat. A tradução oficial do Puppet é fantoche. Atualmente, existem muitos tipos de Puppet disponíveis. do Puppet são as diferentes funções do robô que podem ser alcançadas. Por exemplo, se você deseja que seu robô expulse os usuários de um bate-papo em grupo, você precisa usar o Puppet no protocolo Pad.
Inscreva-se para conexão: http://pad-local.com/#/login
Nota : Após solicitar uma conta, você receberá um token de 7 dias.
Após solicitar o token, execute o seguinte comando na janela cmd:
docker run - it - d -- name wechaty_test - e WECHATY_LOG="verbose" - e WECHATY_PUPPET="wechaty - puppet - padlocal" - e WECHATY_PUPPET_PADLOCAL_TOKEN="yourtoken" - e WECHATY_PUPPET_SERVER_PORT="8080" - e WECHATY_TOKEN="1fe5f846 - 3cfb - 401d - b20c - sailor==" - p "8080:8080" wechaty/wechaty:0 . 65
Descrição do parâmetro:
WECHATY_PUPPET_PADLOCAL_TOKEN : Inscreva-se para obter um bom token
**WECHATY_TOKEN **: Basta escrever uma string aleatória que seja garantidamente única
WECHATY_PUPPET_SERVER_PORT : porta do servidor docker
wechaty/wechaty:0.65 : versão da imagem wechaty
Nota: - "8080:8080"* é a porta da sua máquina local e do servidor docker. Observe que a porta do servidor docker deve ser consistente com WECHATY_PUPPET_SERVER_PORT.
Após a execução, visualize o contêiner no painel do docker desktop:
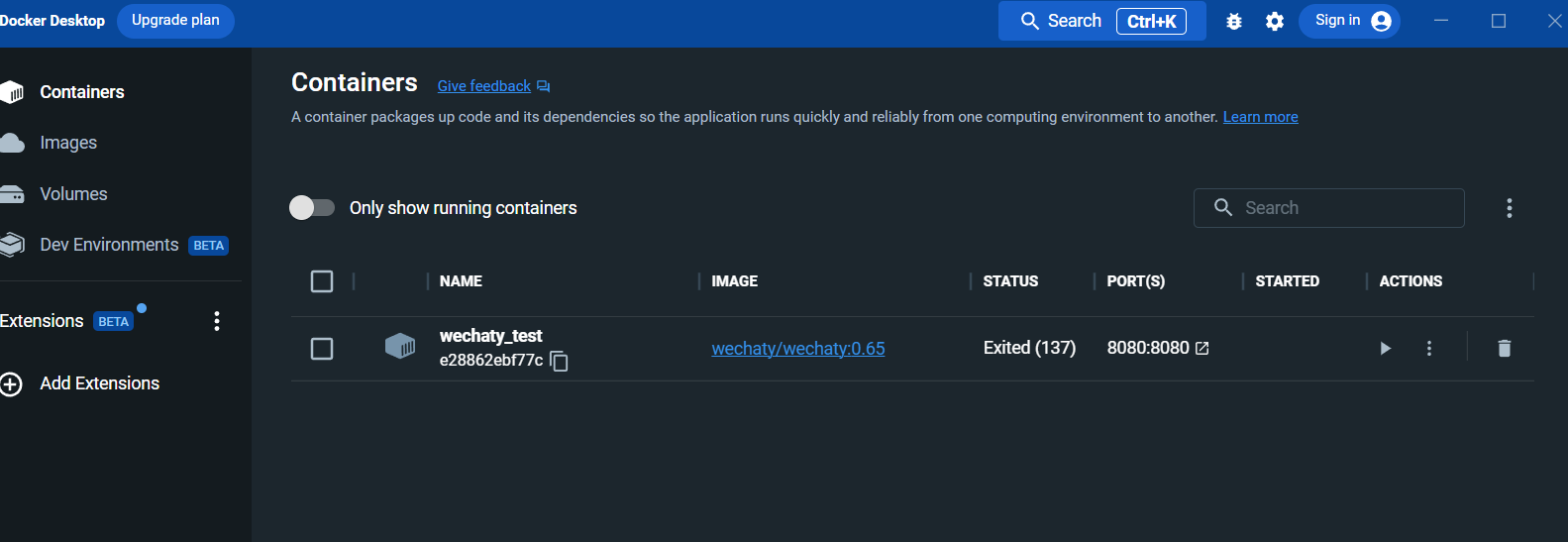
Entre na interface de registro:
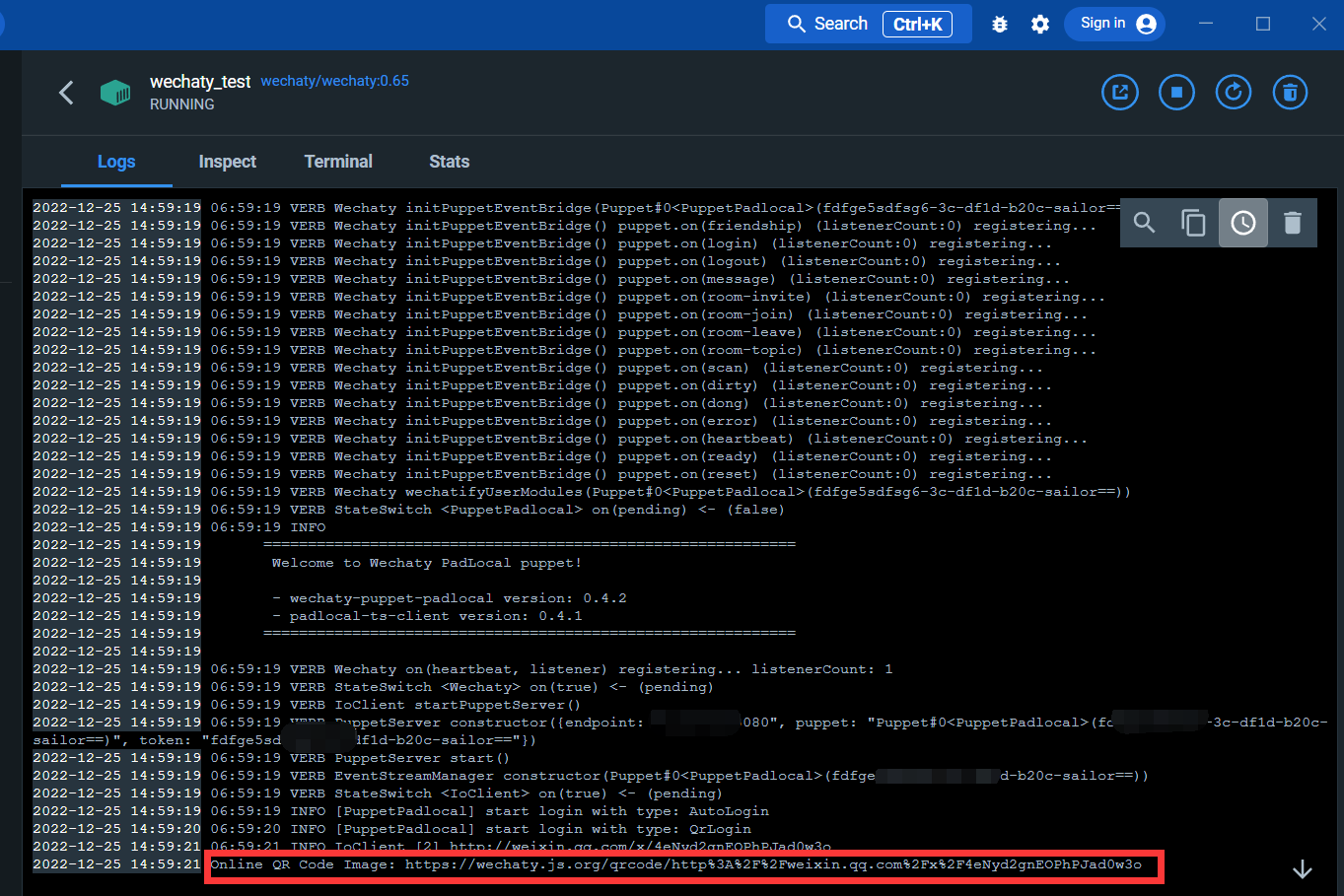
Através do link abaixo, você pode escanear o código QR para fazer login no WeChat
Após o login, o serviço docker é concluído.
Instale bibliotecas wechaty e openai
Abra o cmd e execute o seguinte comando:
pip install wechaty
pip install openaiFaça login no openAI
https://beta.openai.com/
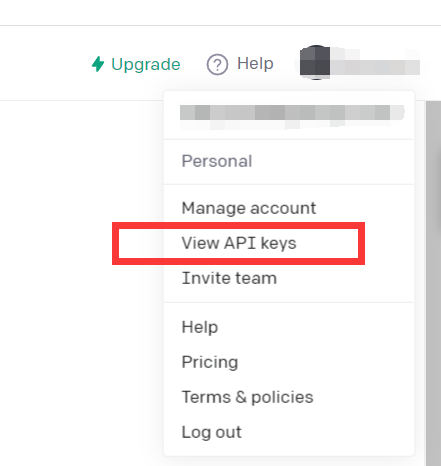
Clique em Exibir chaves de API
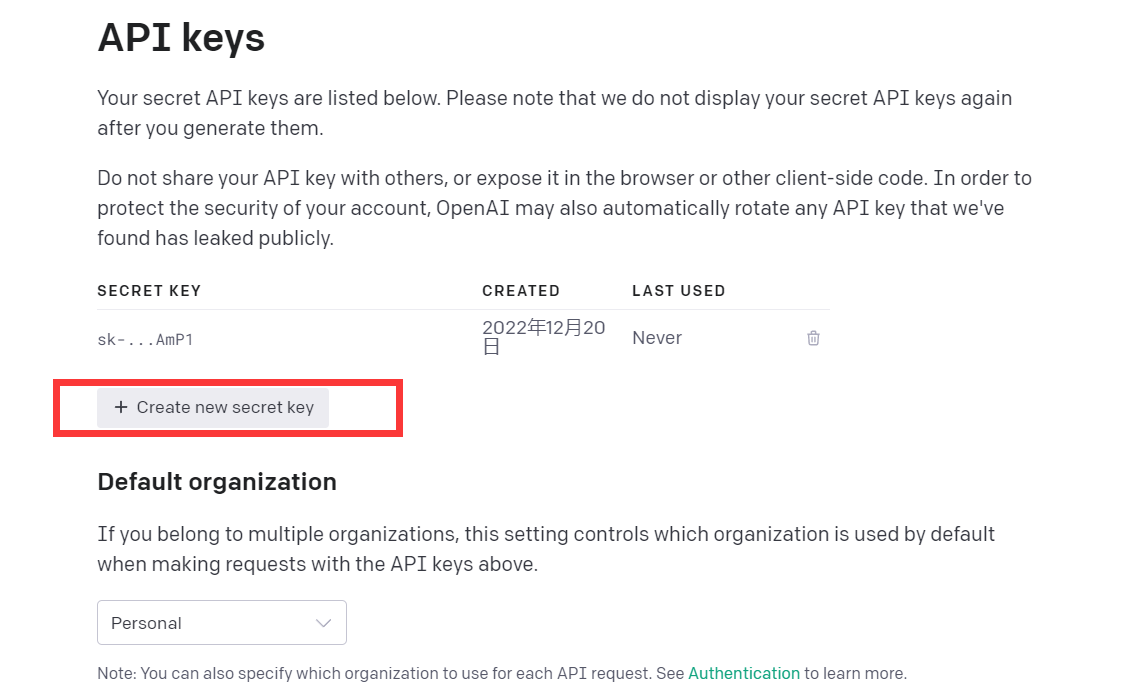
Basta obter API Kyes
Neste ponto, o ambiente está configurado
Você pode tentar ler este código de demonstração
import openai
openai . api_key = "your API-KEY"
start_sequence = "A:"
restart_sequence = "Q: "
while True :
print ( restart_sequence , end = "" )
prompt = input ()
if prompt == 'quit' :
break
else :
try :
response = openai . Completion . create (
model = "text-davinci-003" ,
prompt = prompt ,
temperature = 0.9 ,
max_tokens = 2000 ,
frequency_penalty = 0 ,
presence_penalty = 0
)
print ( start_sequence , response [ "choices" ][ 0 ][ "text" ]. strip ())
except Exception as exc :
print ( exc )
Este código chama o modelo CPT-3, que é o mesmo modelo do chatGPT, e o efeito de resposta também é bom.
O modelo GPT-3 da openAI é apresentado da seguinte forma:
Nossos modelos GPT-3 podem compreender e gerar linguagem natural. Oferecemos quatro modelos principais com diferentes níveis de potência, adequados para diferentes tarefas. Davinci é o modelo mais capaz e Ada é o mais rápido.
| ÚLTIMO MODELO | DESCRIÇÃO | PEDIDO MÁXIMO | DADOS DE TREINAMENTO |
|---|---|---|---|
| texto-davinci-003 | Modelo GPT-3 mais capaz. Pode realizar qualquer tarefa que outros modelos possam realizar, geralmente com maior qualidade, saída mais longa e melhor seguimento de instruções. | 4.000 fichas | Até junho de 2021 |
| texto-curie-001 | Muito capaz, mas mais rápido e de menor custo que o Davinci. | 2.048 fichas | Até outubro de 2019 |
| texto-babbage-001 | Capaz de tarefas simples, muito rápidas e de menor custo. | 2.048 fichas | Até outubro de 2019 |
| texto-ada-001 | Capaz de tarefas muito simples, geralmente o modelo mais rápido da série GPT-3 e de menor custo. | 2.048 fichas | Até outubro de 2019 |
Embora Davinci seja geralmente o mais capaz, os outros modelos podem executar determinadas tarefas extremamente bem com vantagens significativas de velocidade ou custo. Por exemplo, Curie pode executar muitas das mesmas tarefas que Davinci, mas mais rápido e por 1/10 do custo.
Recomendamos usar Davinci durante os testes, pois ele produzirá os melhores resultados. Depois que tudo estiver funcionando, recomendamos tentar os outros modelos para ver se você consegue os mesmos resultados com menor latência. desempenho dos modelos, ajustando-os em uma tarefa específica.
Resumindo, o modelo GPT-3 mais poderoso. Pode fazer qualquer coisa que outros modelos podem fazer, geralmente com maior qualidade, produção mais longa e melhor acompanhamento de instruções. A inserção de conclusões no texto também é suportada.
Embora o uso direto do modelo text-davinci-003 possa alcançar o efeito de diálogo de rodada única do chatGPT, mas para obter melhor o mesmo efeito de diálogo de múltiplas rodadas do chatGPT, um modelo de diálogo pode ser projetado;
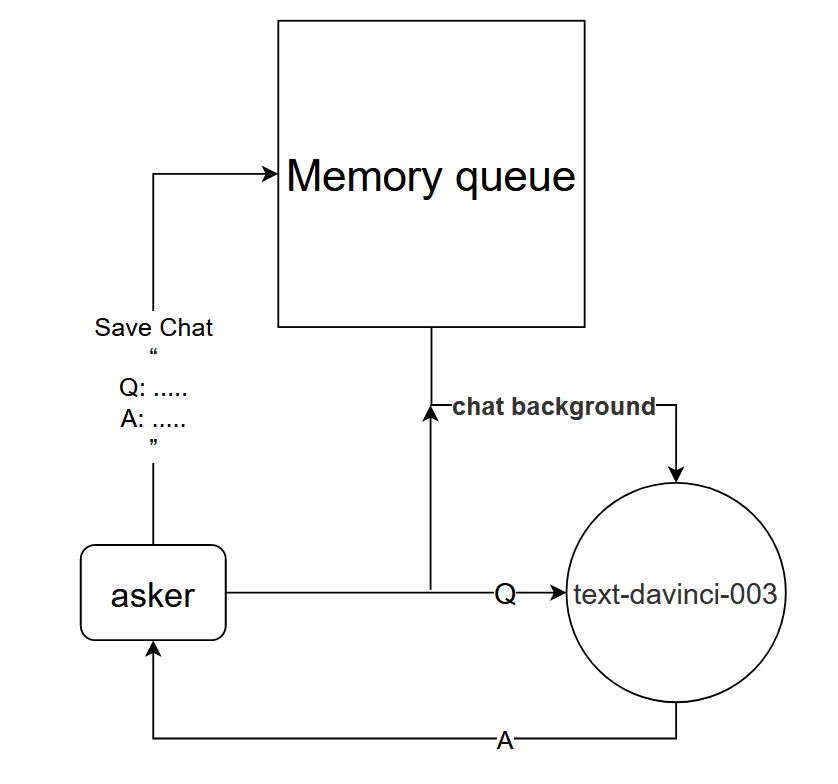
Princípio básico: Informe ao modelo text-davinci-003 o contexto da conversa atual
Método de implementação: projete uma fila de memória de diálogo para salvar as primeiras k rodadas de diálogo do diálogo atual e informe ao modelo text-davinci-003 o conteúdo das primeiras k rodadas de diálogo antes de fazer uma pergunta e, em seguida, obtenha a resposta atual através do conteúdo do modelo text-davinci-003
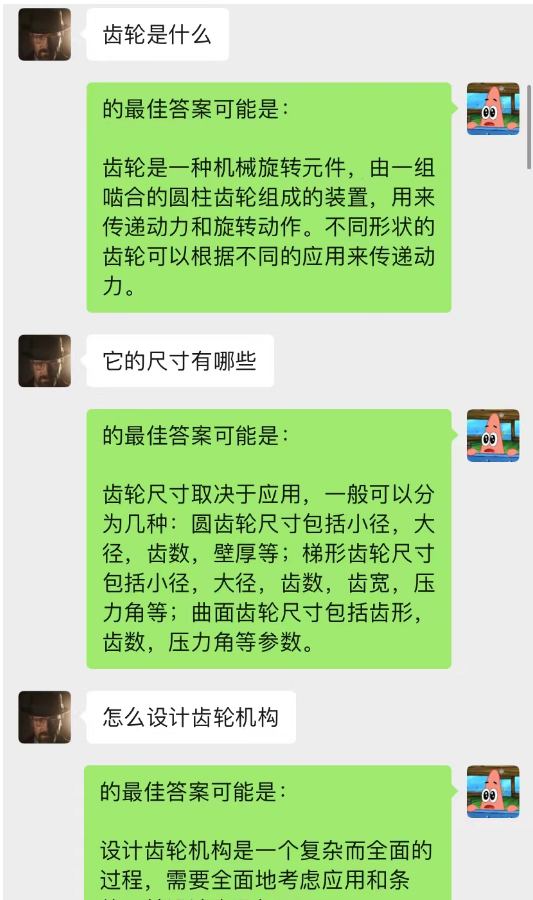
Este método funciona surpreendentemente bem! Dê alguns registros de bate-papo
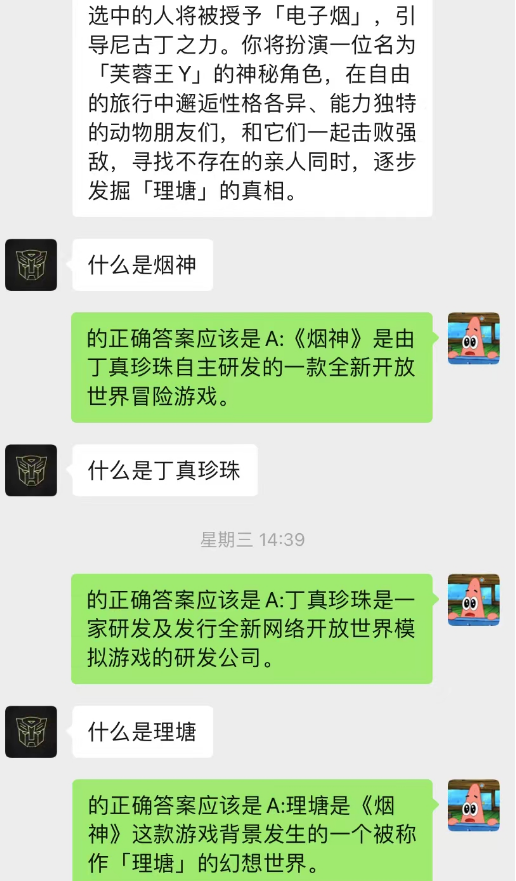
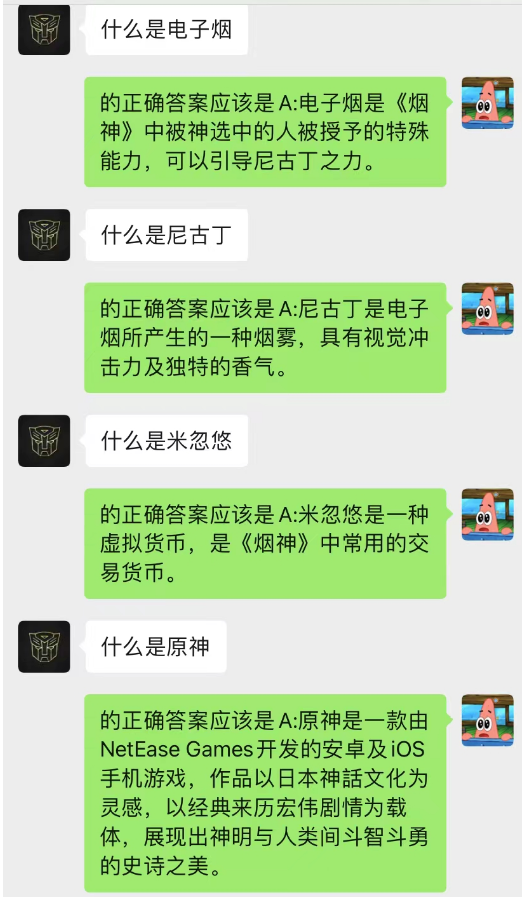
Pode-se observar que a IA também pode completar o aprendizado situacional por meio do chat em segundo plano.
Além disso, você também pode obter a mesma redação guiada de artigos do chatGPT.
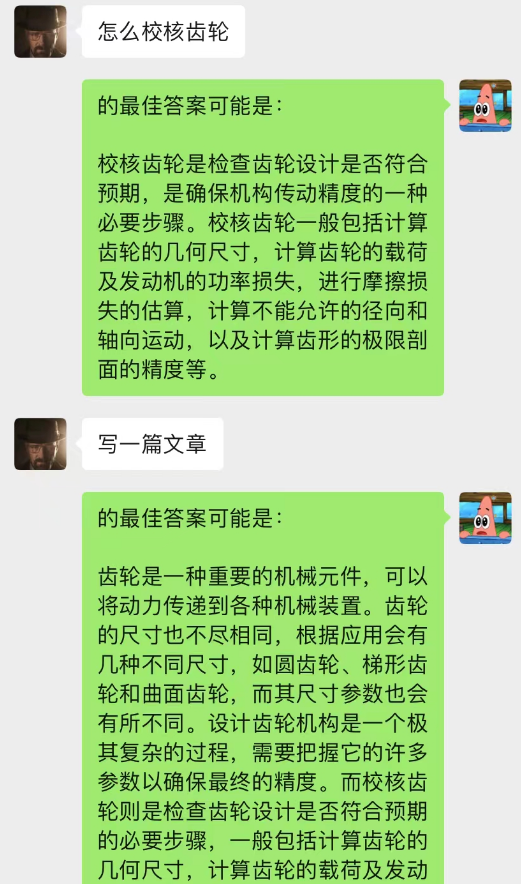
Este modelo é um método que estou concebendo atualmente para otimizar o modelo de diálogo chat-background. Sua lógica básica é a mesma do modelo de linguagem N-gram, exceto que N é alterado dinamicamente e as propriedades de Markov são adicionadas para prever o relacionamento atual. com o contexto, de modo a julgar que a seção do fundo do chat é a mais importante, e então usar o modelo text-davinci-003 para dar uma resposta baseada no conteúdo do diálogo memorizado mais importante combinado com o problema atual (equivalente permitir que a IA faça isso durante o bate-papo, usando o conteúdo anterior do bate-papo)
A implementação deste modelo requer uma grande quantidade de dados para treinamento e o código ainda não foi concluído.
------ Digging : Depois que o código for implementado, atualize esta parte das etapas detalhadas
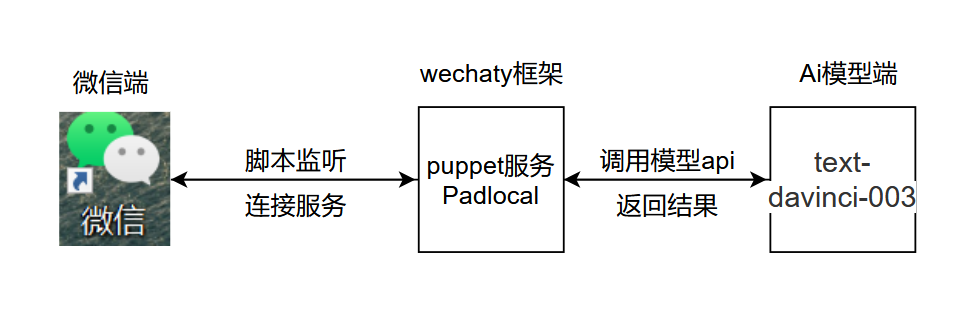
A lógica básica do projeto é mostrada na figura abaixo:
 .py, adicione e abra chatGPT.py no local mostrado, adicione a chave secreta e configure as variáveis de ambiente no local mostrado
.py, adicione e abra chatGPT.py no local mostrado, adicione a chave secreta e configure as variáveis de ambiente no local mostrado

Explicação do código :
os . environ [ "WECHATY_PUPPET_SERVICE_TOKEN" ] = "填入你的Puppet的token" os . environ [ 'WECHATY_PUPPET' ] = 'wechaty-puppet-padlocal' #保证与docker中相同即可 os.environ['WECHATY_PUPPET_SERVICE_ENDPOINT'] = '主机ip:端口号'
Execute com sucesso
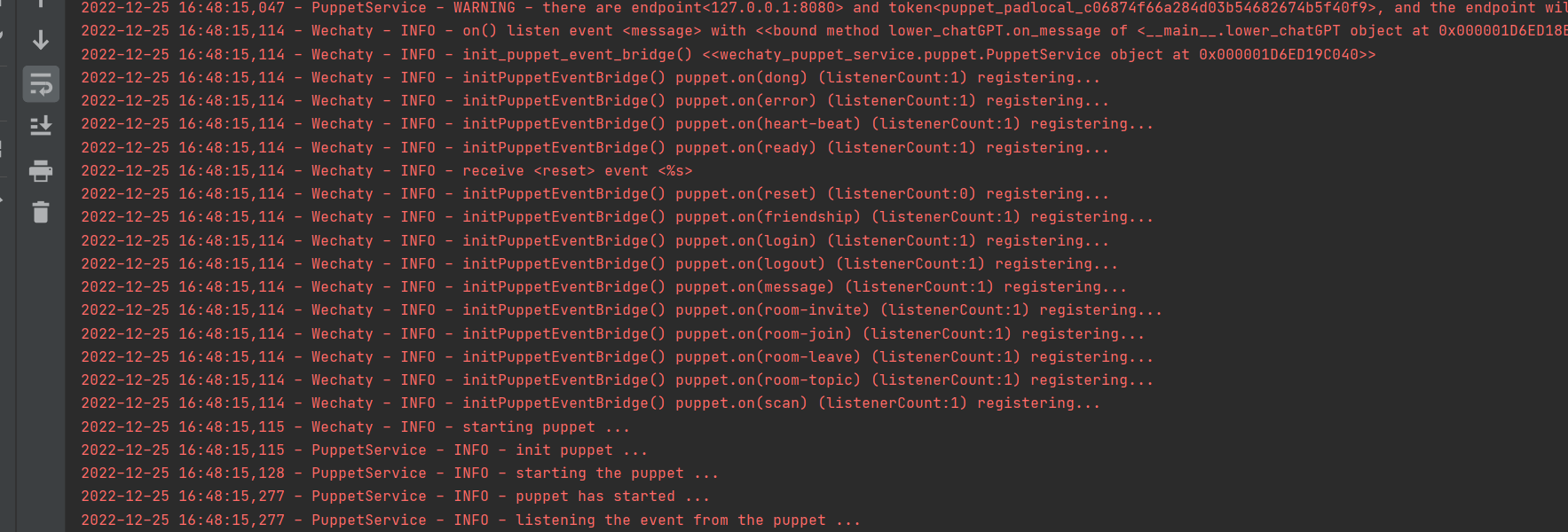
1. Faça login no docker, não use login wechaty em python
2. Defina time.sleep() no código para simular a velocidade com que as pessoas respondem às mensagens.
3. É melhor não usar um tamanho grande durante o teste. Recomenda-se criar um tamanho pequeno dedicado para testes de IA.
O conteúdo deste projeto é apenas para pesquisa técnica e divulgação científica, não servindo como base conclusiva. Não fornece nenhuma autorização de aplicação comercial e não se responsabiliza por qualquer comportamento.
~~e-mail: [email protected]


