glory admin
1.0.0
GloryAdmin é uma estrutura de segundo plano baseada em springboot2.1.9.RELEASE e vue-admin-template;
GloryAdmin usa gerenciamento de permissões baseado em funções. A árvore de funções é uma árvore com "Administrador do Sistema" como nó raiz, e a árvore de permissões é composta por várias árvores de subpermissões. "Administrador do sistema" tem todas as permissões que não são de administrador do sistema e pode visualizar as informações da função atual e das funções diretamente subordinadas, mas só pode adicionar, excluir e modificar as informações das funções diretamente subordinadas (subordinados diretos: A é o direto; subordinado de B, então A deve ser o nó filho de B).
Glória-Admin
| projeto | tecnologia |
|---|---|
| Projeto de back-end | bota de mola |
| Projeto front-end | UI do elemento e Vue.js |
| banco de dados | MySQL |
| esconderijo | Redis |

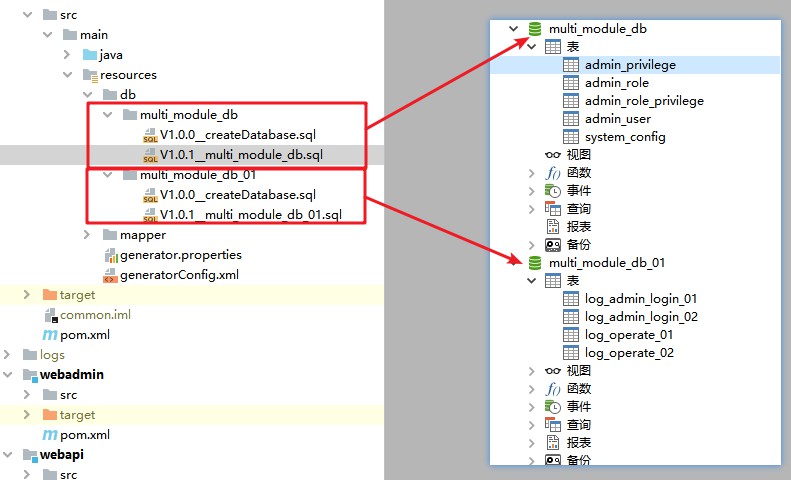
Este projeto usa banco de dados mysql, você pode usar o script de banco de dados para criar 2 bancos de dados multi_module_db multi_module_db_01
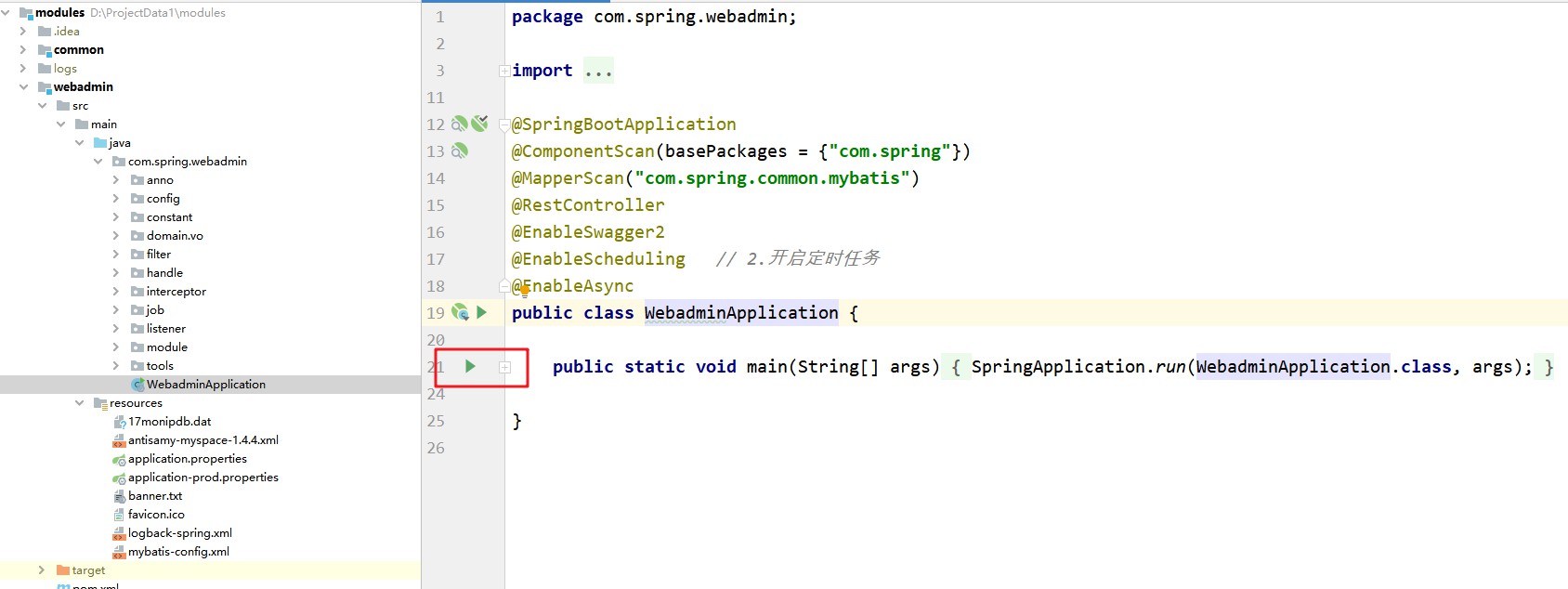
Comece em segundo plano e use a porta 28081
Inicie o front-end e use a porta 9523
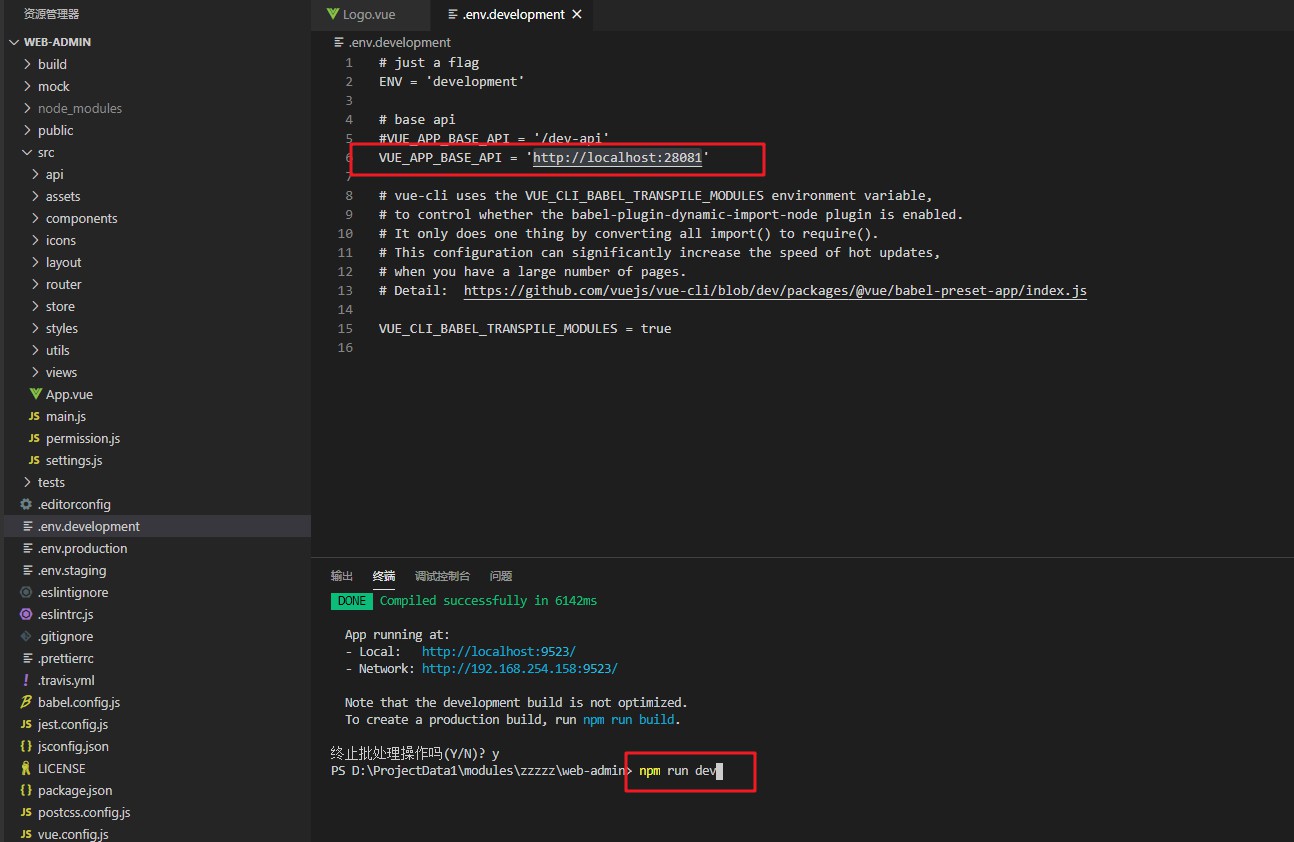
Abra o navegador e visite http://localhost:9523 admin a123456
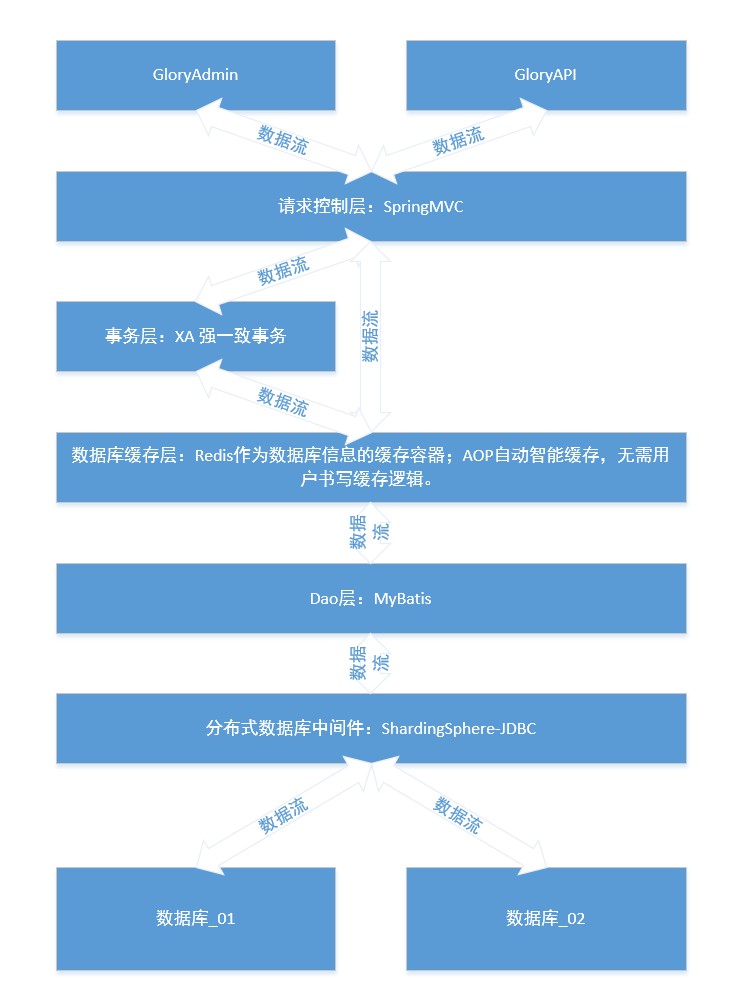
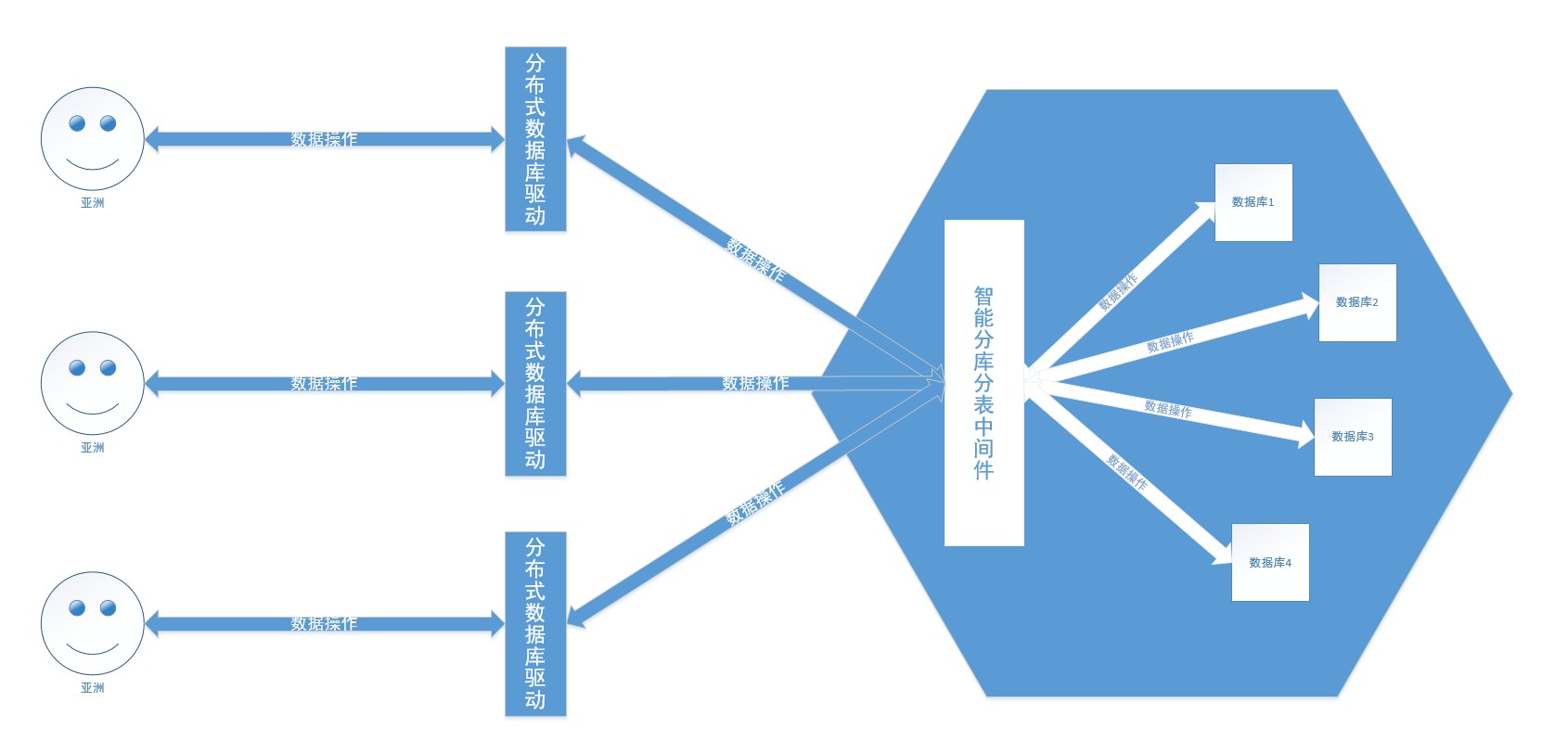
A essência do sharding ou sharding é o fracasso da Lei de Moore. A solução de armazenamento centralizado de dados em um único nó de dados tem sido difícil de atender aos cenários massivos de dados da Internet em termos de desempenho, disponibilidade e custos de operação e manutenção.
Um único banco de dados não pode suportar negócios existentes, então surgiram sub-bancos de dados e tabelas, e vários bancos de dados são usados para armazenamento de dados. O simples entendimento do subbanco de dados e da subtabela é que o conteúdo de uma cesta é limitado, o que afeta a eficiência e a capacidade da pesquisa. O conteúdo da cesta é dividido em N partes e colocado em cestas diferentes. Isso quebra as restrições de capacidade e melhora a eficiência da consulta.
Então vamos falar sobre bancos de dados distribuídos. Os mais populares na China incluem TDSQL da Tencent, OceanBase do Alibaba, PolarDB, GaussDB da Huawei, etc. Basicamente, eles são desenvolvidos de forma independente, com forte consistência e alta disponibilidade, arquitetura de implantação global, expansão horizontal ilimitada distribuída, alto desempenho, centenas de bilhões de registros e transações entre linhas e tabelas em centenas de TB de dados (como para a pátria) . O banco de dados distribuído esconde a estratégia de fragmentação de banco de dados e de tabela, fragmenta dados de forma inteligente em bancos de dados e tabelas e os utiliza como se fosse operar um banco de dados.
Como as operações de memória e as operações de disco não são da mesma ordem de magnitude, grandes projetos exigem uma camada de buffer do tipo memória para que os bancos de dados do tipo disco armazenem em cache os dados do disco na memória. A camada de cache de dados é usada para armazenar em cache os dados de toda a camada de dados para acelerar o acesso ao site. Este projeto usa tecnologia AOP e banco de dados em memória Redis como camada de cache de dados. Verifique o código com/spring/common/aop/CacheDaoAspect.java para obter detalhes.
Este projeto usa sharding JDBC para processar o banco de dados e as tabelas do banco de dados. Divida você mesmo os dados de acordo com os cenários de negócios.
Normalmente, os projetos têm apenas um banco de dados, e o druida do Alibaba Cloud é usado com mais frequência na China como pool de conexão de banco de dados. Este projeto usa mysql, druid e sharding JDBC. O princípio da fragmentação de dados é manter vários conjuntos de conexões de banco de dados no programa, e cada conjunto de conexões de banco de dados corresponde a um banco de dados. O banco de dados fragmentado e as tabelas fragmentadas usam processamento de transações em duas fases baseado no protocolo XA . Caminho de configuração com.spring.common.config.shardingJDBC
Divisão vertical: O método de divisão de negócios é chamado de fragmentação vertical, também conhecido como divisão vertical. Distribua tabelas para diferentes bancos de dados de acordo com o negócio, distribuindo assim a pressão para diferentes bancos de dados.
Divisão horizontal: não se preocupa com a classificação da lógica de negócios, mas dispersa os dados em múltiplas bibliotecas ou tabelas de acordo com certas regras através de um determinado campo (ou vários campos) de uma determinada tabela. As regras aqui e o algoritmo envolvido são chamados de algoritmos de fragmentação .
( O conteúdo a seguir foi retirado da documentação do shardingJDBC )
Corresponde ao PreciseShardingAlgorithm, usado para lidar com o cenário de fragmentação = e IN usando uma única chave como chave de fragmentação. Precisa ser usado com StandardShardingStrategy.
Corresponde ao RangeShardingAlgorithm, que é usado para lidar com cenários de fragmentação usando BETWEEN AND , > , < , >= e <= usando uma única chave como chave de fragmentação. Precisa ser usado com StandardShardingStrategy.
Corresponde ao ComplexKeysShardingAlgorithm, que é usado para lidar com cenários em que várias chaves são usadas como chaves de fragmentação para fragmentação. A lógica que contém várias chaves de fragmentação é complexa e os desenvolvedores de aplicativos precisam lidar com a complexidade por conta própria. Precisa ser usado com ComplexShardingStrategy.
Corresponde ao HintShardingAlgorithm, usado para lidar com cenários em que a fragmentação de linha Hint é usada. Precisa ser usado com HintShardingStrategy.
O usuário faz login para obter o token e armazená-lo localmente (adminLogin)
O usuário envia um token para obter informações do usuário e de permissão e os armazena na loja. Como F5 causará a perda do armazenamento, um interceptador será adicionado à solicitação de front-end. Se não houver informações do usuário e informações de permissão, as informações e permissões do usuário serão obtidas novamente (getAdminInfo).
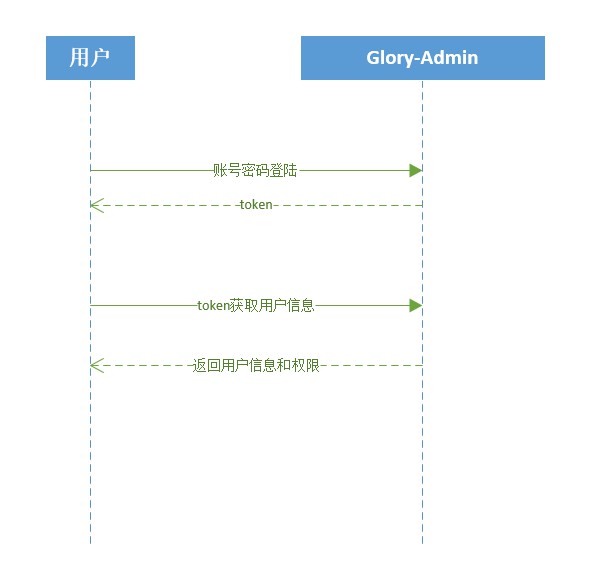
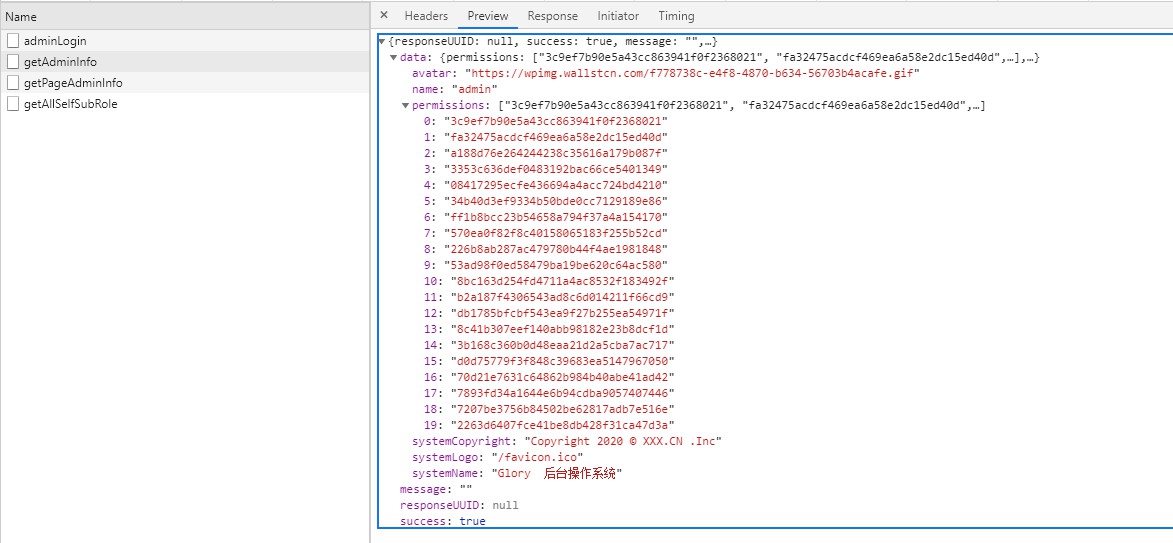
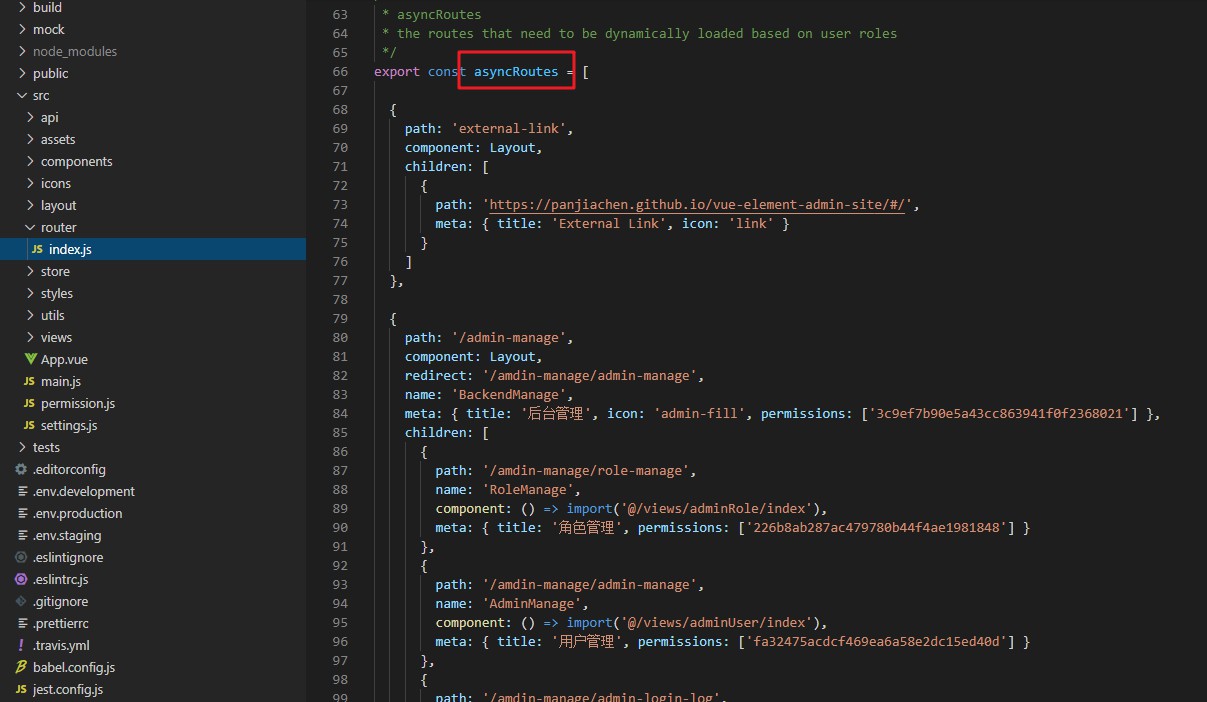
O que é retornado aqui são todas as permissões do usuário em vez da função. O usuário gera rotas de front-end dinamicamente.
asyncRoutes é uma permissão gerada dinamicamente. Se a permissão do usuário corresponder à permissão da rota, ela será exibida;
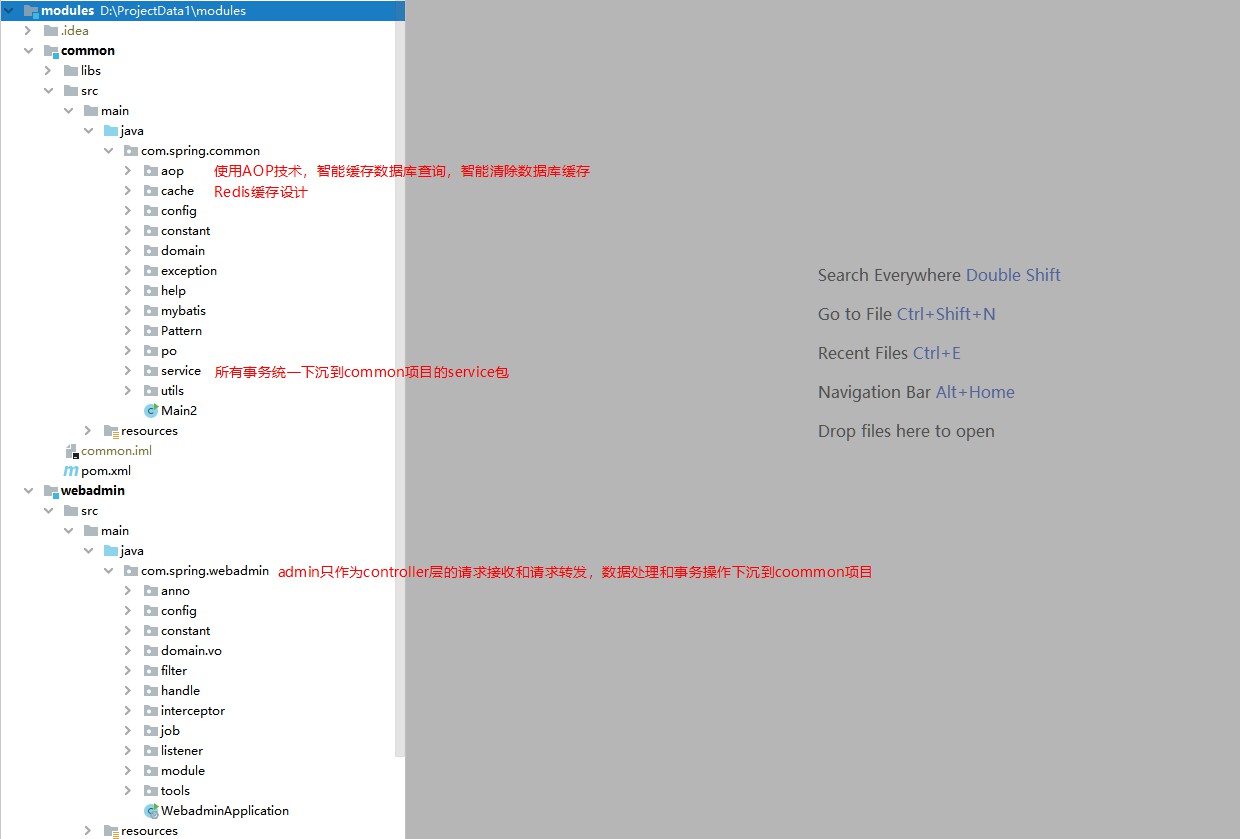
comum: operações de dados, cache de dados, operações de transação
O administrador serve apenas como controlador, que é usado para lidar com o encaminhamento entre solicitações de usuários e negócios de back-end. (Por que foi projetado assim?) Porque alguns sistemas de middleware precisam usar a estrutura RPC para encaminhamento de solicitações e porque alguns sistemas confidenciais desdenham o uso do springMVC e escolhem o vertx para desenvolver a camada de solicitação de forma independente.
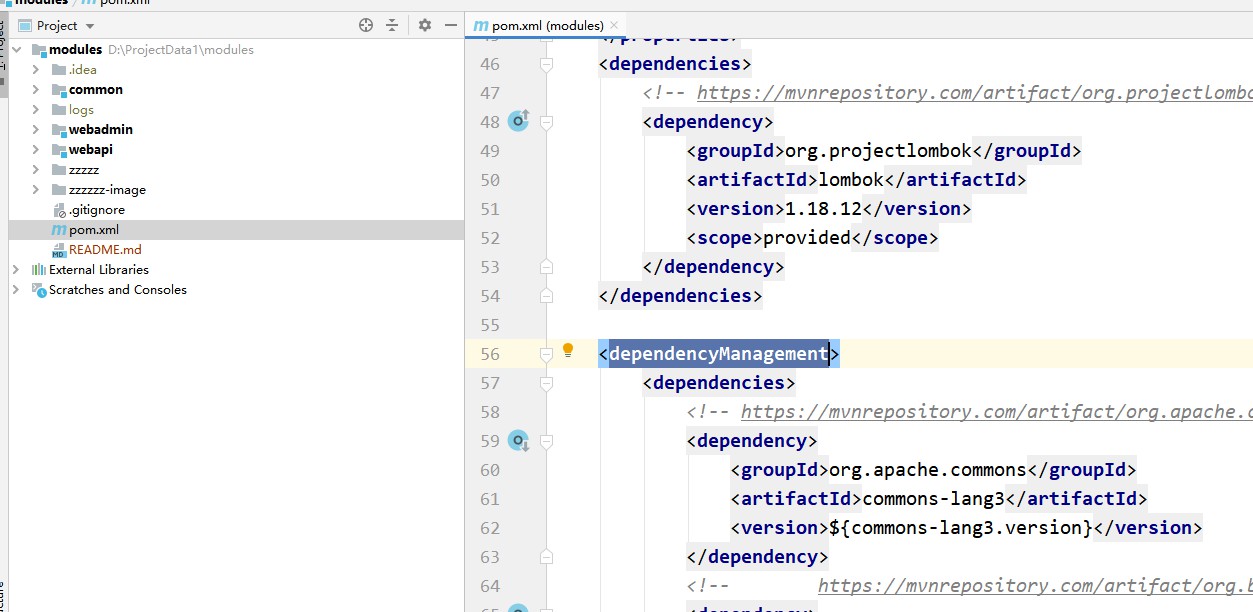
Use a herança Maven para gerenciar dependências do projeto. Em Módulos, as dependências são introduzidas por meio de dependencyManagement e as versões são especificadas. Os subprojetos herdam os Módulos e não há necessidade de especificar versões ao introduzir dependências.
Processamento de log global
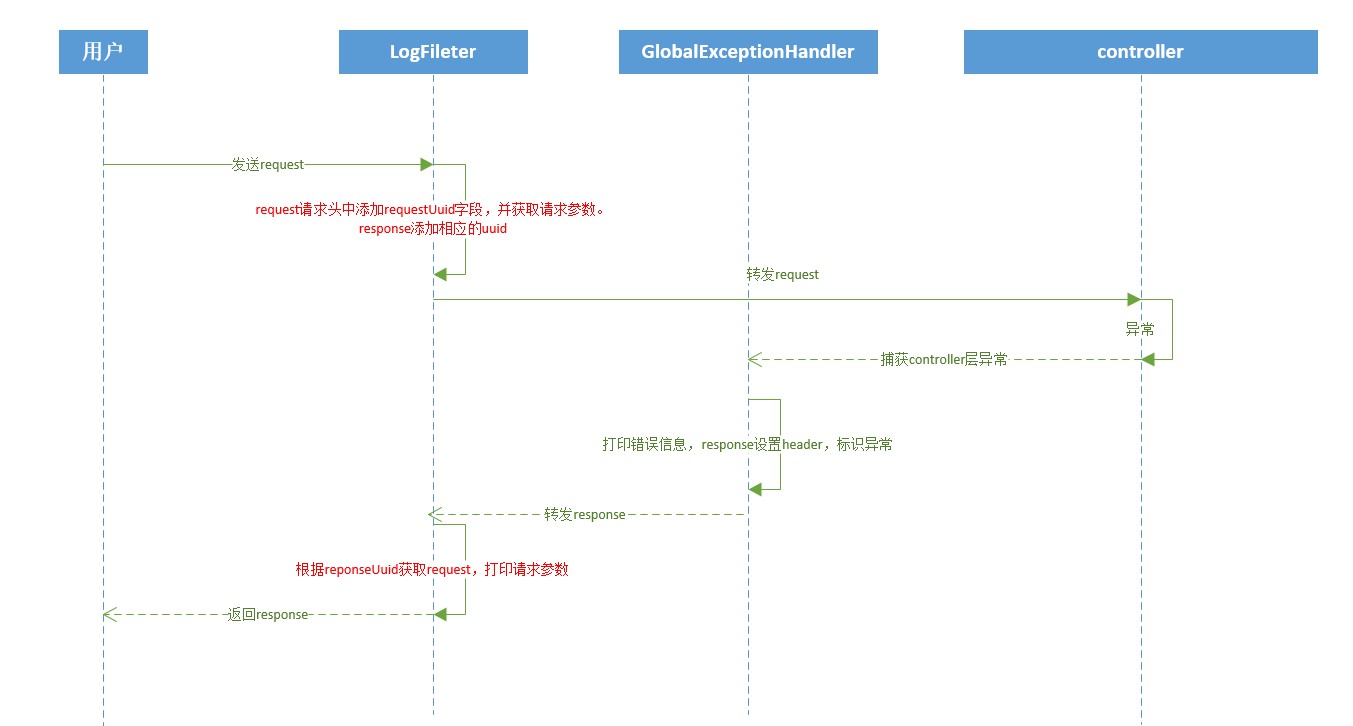
Os logs de operação do usuário usam métodos de anotação. Se este método precisar registrar logs de operação, basta adicionar a anotação **@OperateLog** acima do nome do método.
@ OperateLog
@ ApiOperation ( value = "登出" , notes = "登出" )
@ GetMapping ( Route . Admin . adminLogout )
public ResponseDate adminLogout ( HttpServletRequest httpServletRequest ) {
AdminInfoDTO adminInfoDTO = AdminTool . getAdminUser ( httpServletRequest );
AdminUser adminUser = adminUserMapper . selectByPrimaryKey ( adminInfoDTO . getAdminUk ());
adminUser . setNowToken ( "log-out" );
int result = adminUserService . updateAdminToken ( adminUser );
return ResponseDate . builder ()
. success ( result == 1 )
. build ();
}

