whisper.cpp
v1.7.2
Estábulo: v1.7.2 / roteiro | Perguntas frequentes
Inferência de alto desempenho do modelo de reconhecimento automático de fala Whisper da OpenAI (ASR):
Plataformas suportadas:
Toda a implementação de alto nível do modelo está contida no sussurro.h e sussurro.cpp. O restante do código faz parte da biblioteca de aprendizado de máquina ggml .
Ter uma implementação tão leve do modelo permite integrá -lo facilmente em diferentes plataformas e aplicativos. Como exemplo, aqui está um vídeo de execução do modelo em um dispositivo iPhone 13 - totalmente offline, no dispositivo: sussurro.objc
Você também pode facilmente fazer seu próprio aplicativo de assistente de voz offline: comando
No Apple Silicon, a inferência é totalmente executada na GPU via metal:
Ou você pode até executá -lo diretamente no navegador: Talk.wasm
Os operadores do tensor são otimizados fortemente para as CPUs de silício da Apple. Dependendo do tamanho da computação, são utilizadas rotinas de estrutura de néon sIMD ou CBLAs aceleram as rotinas da estrutura. Estes últimos são especialmente eficazes para tamanhos maiores, pois a estrutura acelerada utiliza o coprocessador AMX de fins especiais disponíveis nos modernos produtos da Apple.
Primeiro clone o repositório:
git clone https://github.com/ggerganov/whisper.cpp.gitNavegue no diretório:
cd whisper.cpp
Em seguida, faça o download de um dos modelos Whisper convertidos em formato ggml . Por exemplo:
sh ./models/download-ggml-model.sh base.enAgora construa o exemplo principal e transcreva um arquivo de áudio como este:
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav Para uma demonstração rápida, basta executar make base.en :
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
O comando baixar o modelo base.en convertido em formato ggml personalizado e executa a inferência em todas as amostras .wav nas samples de pasta.
Para instruções de uso detalhadas, execute: ./main -h
Observe que o exemplo principal atualmente é executado apenas com arquivos WAV de 16 bits, portanto, converta sua entrada antes de executar a ferramenta. Por exemplo, você pode usar ffmpeg como este:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavSe você deseja algumas amostras de áudio extras para brincar, basta executar:
make -j samples
Isso baixará mais alguns arquivos de áudio da Wikipedia e os converterá em formato WAV de 16 bits via ffmpeg .
Você pode baixar e executar os outros modelos da seguinte forma:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| Modelo | Disco | Mem |
|---|---|---|
| pequeno | 75 MIB | ~ 273 MB |
| base | 142 MIB | ~ 388 MB |
| pequeno | 466 MIB | ~ 852 MB |
| médio | 1.5 Gib | ~ 2,1 GB |
| grande | 2.9 Gib | ~ 3,9 GB |
whisper.cpp suporta quantização inteira dos modelos Whisper ggml . Os modelos quantizados requerem menos espaço de memória e disco e, dependendo do hardware, podem ser processados com mais eficiência.
Aqui estão as etapas para criar e usar um modelo quantizado:
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav Nos dispositivos Apple Silicon, a inferência do codificador pode ser executada no mecanismo neural da Apple (ANE) via Core ML. Isso pode resultar em aceleração significativa-mais do que X3 mais rápido em comparação com a execução somente da CPU. Aqui estão as instruções para gerar um modelo Core ML e usá -lo com whisper.cpp :
Instale as dependências do Python necessárias para a criação do modelo Core ML:
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools opere corretamente, confirme que o Xcode está instalado e execute xcode-select --install para instalar as ferramentas da linha de comando.conda create -n py310-whisper python=3.10 -yconda activate py310-whisper Gere um modelo ML do núcleo. Por exemplo, para gerar um modelo base.en , use:
./models/generate-coreml-model.sh base.en Isso gerará os models/ggml-base.en-encoder.mlmodelc
Build whisper.cpp com suporte principal de ML:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config ReleaseExecute os exemplos como de costume. Por exemplo:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
A primeira execução em um dispositivo é lenta, já que o serviço ANE compila o modelo Core ML para algum formato específico do dispositivo. As próximas corridas são mais rápidas.
Para obter mais informações sobre a implementação principal do ML, consulte o PR #566.
Em plataformas que suportam o OpenVino, a inferência do codificador pode ser executada em dispositivos suportados por Openvino, incluindo X86 CPUs e GPUs Intel (integrado e discreto).
Isso pode resultar em aceleração significativa no desempenho do codificador. Aqui estão as instruções para gerar o modelo Openvino e usá -lo com whisper.cpp :
Primeiro, configure Python Virtual Env. e instalar dependências do Python. Python 3.10 é recomendado.
Windows:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux e MacOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt Gere um modelo de codificador OpenVino. Por exemplo, para gerar um modelo base.en , use:
python convert-whisper-to-openvino.py --model base.en
Isso produzirá GGML-BASE.en-Encoder-penvino.xml/.bin IR Model Arquivos. É recomendável realocá -los para a mesma pasta que os modelos ggml , pois esse é o local padrão que a extensão do Openvino pesquisará em tempo de execução.
Build whisper.cpp com suporte OpenVino:
Faça o download do pacote openvino na página de lançamento. A versão recomendada a ser usada é 2023.0.0.
Depois de baixar e extrair o pacote no seu sistema de desenvolvimento, configure o ambiente necessário, adquirindo o script SetupVars. Por exemplo:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.batE então construa o projeto usando o cmake:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config ReleaseExecute os exemplos como de costume. Por exemplo:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
A primeira vez em um dispositivo OpenVino é lento, pois a estrutura do Openvino compilará o modelo IR (Representação Intermediária) com um 'Blob' específico do dispositivo. Este blob específico do dispositivo será armazenado em cache para a próxima execução.
Para obter mais informações sobre a implementação principal do ML, consulte o PR #1037.
Com os cartões da NVIDIA, o processamento dos modelos é feito com eficiência na GPU via Cublas e Kernels CUDA personalizados. Primeiro, certifique-se de instalar cuda : https://developer.nvidia.com/cuda-wnowloads
Agora construir whisper.cpp com suporte CUDA:
make clean
GGML_CUDA=1 make -j
Solução de fornecedores cruzados que permite acelerar a carga de trabalho na sua GPU. Primeiro, verifique se o driver da placa gráfica fornece suporte para a API Vulkan.
Agora construir whisper.cpp com suporte de vulkan:
make clean
make GGML_VULKAN=1 -j
O processamento do codificador pode ser acelerado na CPU via OpenBlas. Primeiro, verifique se você instalou openblas : https://www.openblas.net/
Agora construir whisper.cpp com suporte OpenBlas:
make clean
GGML_OPENBLAS=1 make -j
O processamento do codificador pode ser acelerado na CPU através da interface compatível com BLAS da biblioteca do kernel de matemática da Intel. Primeiro, certifique-se de instalar os pacotes de tempo de execução e desenvolvimento da Intel: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-do-carl.html
Agora construa whisper.cpp com suporte Intel mkl blas:
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
Ascend NPU fornece aceleração de inferência via CANN e núcleos de IA.
Primeiro, verifique se o seu dispositivo NPU Ascend é suportado:
Dispositivos verificados
| Ascend npu | Status |
|---|---|
| Atlas 300T A2 | Apoiar |
Em seguida, verifique se você instalou CANN toolkit . A versão durada de Cann é recomendada.
Agora construa whisper.cpp com suporte de canis:
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
Execute os exemplos de inferência como de costume, por exemplo:
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
Notas:
Verified devices da tabela. Temos duas imagens do Docker disponíveis para este projeto:
ghcr.io/ggerganov/whisper.cpp:main : Esta imagem inclui o arquivo executável principal, bem como curl e ffmpeg . (Plataformas: linux/amd64 , linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : o mesmo que main , mas compilado com o suporte da CUDA. (Plataformas: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " Você pode instalar binários pré-construídos para sussurrar.cpp ou construí-lo a partir da fonte usando Conan. Use o seguinte comando:
conan install --requires="whisper-cpp/[*]" --build=missing
Para obter instruções detalhadas sobre como usar Conan, consulte a documentação de Conan.
Aqui está outro exemplo de transcrição de um discurso de 3:24 min em cerca de meio minuto em um MacBook M1 Pro, usando o modelo medium.en :
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
Este é um exemplo ingênuo de realizar inferência em tempo real no áudio do seu microfone. A ferramenta de fluxo amostra o áudio a cada meio segundo e executa a transcrição continuamente. Mais informações estão disponíveis na edição nº 10.
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000 Adicionar o argumento --print-colors imprimirá o texto transcrito usando uma estratégia experimental de codificação de cores para destacar palavras com alta ou baixa confiança:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors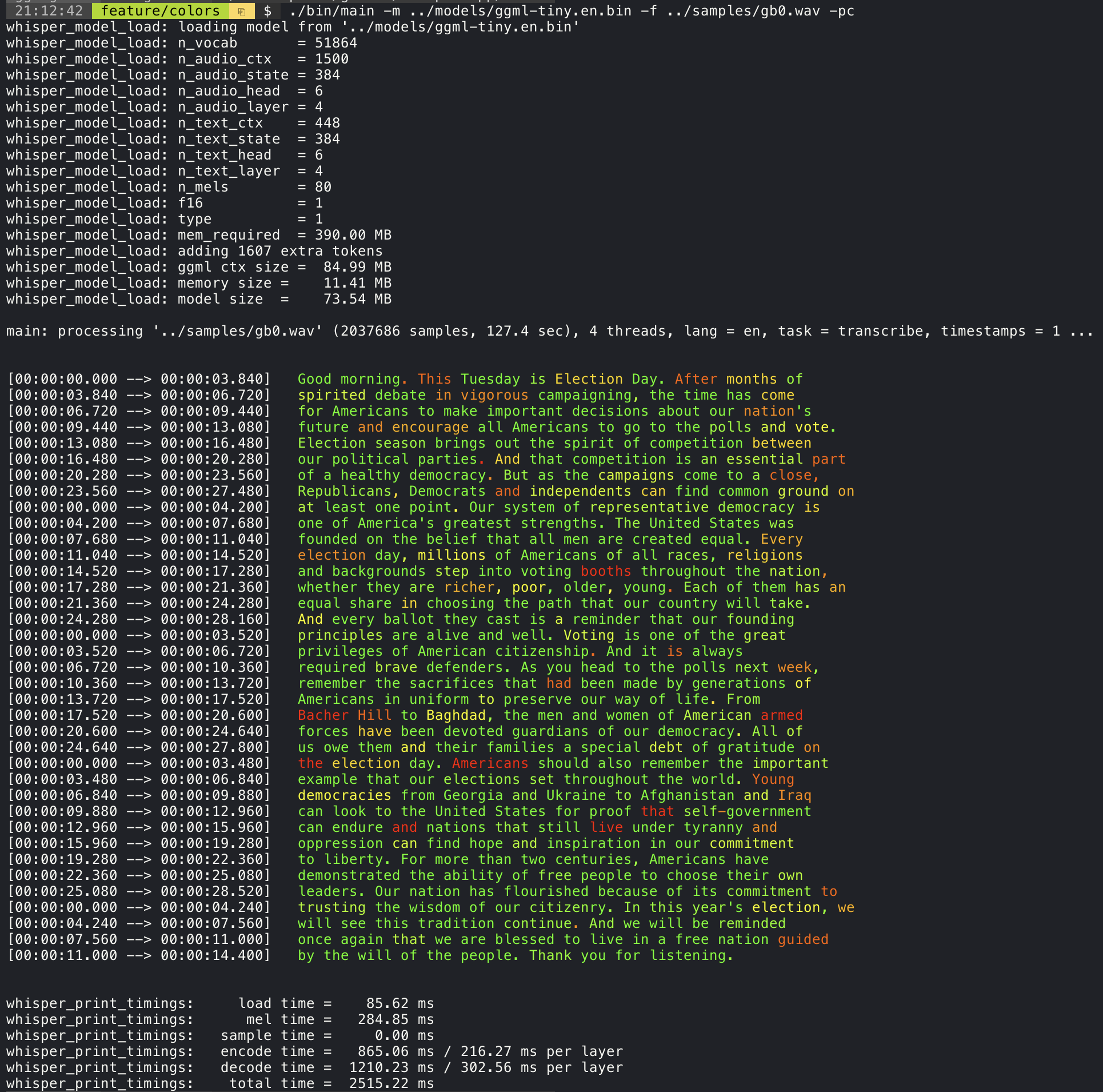
Por exemplo, para limitar o comprimento da linha a um máximo de 16 caracteres, basta adicionar -ml 16 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
O argumento --max-len pode ser usado para obter registros de data e hora no nível da palavra. Basta usar -ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
Mais informações sobre esta abordagem estão disponíveis aqui: #1058
Uso de amostra:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so . O exemplo principal fornece suporte para a saída de filmes em estilo de karaokê, onde a palavra atualmente pronunciada é destacada. Use o argumento -wts e execute o script de bash gerado. Isso requer instalar ffmpeg .
Aqui estão alguns exemplos "típicos" :
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4Use o script Scripts/Bench-wts.sh para gerar um vídeo no seguinte formato:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4Para ter uma comparação objetiva do desempenho da inferência em diferentes configurações do sistema, use a ferramenta de bench. A ferramenta simplesmente executa a parte do codificador do modelo e imprime quanto tempo levou para executá -lo. Os resultados estão resumidos no seguinte problema do GitHub:
Resultados de referência
Além disso, um script para executar o Whisper.cpp com diferentes modelos e arquivos de áudio é fornecido Bench.py.
Você pode executá -lo com o seguinte comando, por padrão, ele será executado contra qualquer modelo padrão na pasta Modelos.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2Está escrito em Python com a intenção de ser fácil de modificar e estender para o seu caso de uso de benchmarking.
Ele gera um arquivo CSV com os resultados do benchmarking.
ggmlOs modelos originais são convertidos em um formato binário personalizado. Isso permite empacotar tudo o que é necessário em um único arquivo:
Você pode baixar os modelos convertidos usando o script modelos/download-ggml-model.sh ou manualmente a partir daqui:
Para mais detalhes, consulte os modelos de script de conversão/convert-pt para-ggml.py ou modelos/readme.md.
Existem vários exemplos de uso da biblioteca para diferentes projetos na pasta Exemplos. Alguns dos exemplos são até portados para executar no navegador usando o WebAssembly. Confira!
| Exemplo | Web | Descrição |
|---|---|---|
| principal | sussurro.WASM | Ferramenta para traduzir e transcrever áudio usando sussurro |
| banco | BENCH.WASM | Compare o desempenho do sussurro em sua máquina |
| fluxo | Stream.WASM | Transcrição em tempo real da captura de microfone bruto |
| comando | Command.wasm | Exemplo básico de assistente de voz para receber comandos de voz do microfone |
| wchess | WCHESS.WASM | Xadrez controlado por voz |
| falar | talk.wasm | Fale com um bot GPT-2 |
| conversa-lama | Fale com um bot de lhama | |
| sussurro.objc | aplicativo móvel iOS usando sussurro.cpp | |
| sussurro.swifttui | Aplicativo Swiftui iOS / MacOS usando sussurro.cpp | |
| sussurro.android | Aplicativo móvel Android usando sussurro.cpp | |
| sussurro.nvim | Plugin de fala para texto para neovim | |
| gerar-karaoke.sh | Script auxiliar para gerar facilmente um vídeo de karaokê de captura de áudio bruta | |
| LiveStream.sh | Transcrição de áudio ao vivo | |
| yt-wsp.sh | Baixar + Transcrever e/ou traduzir qualquer vod (original) | |
| servidor | Servidor de transcrição HTTP com API do tipo OAI |
Se você tiver algum tipo de feedback sobre este projeto, fique à vontade para usar a seção de discussões e abrir um novo tópico. Você pode usar a categoria Show e Tell para compartilhar seus próprios projetos que usam whisper.cpp . Se você tiver uma pergunta, verifique as perguntas frequentes (#126) discussões.


