O repositório consiste em um VQ-VAE implementado em Pytorch e treinado no conjunto de dados MNIST.
O VQ-VAE segue o mesmo conceito básico que por trás dos codificadores automáticos variacionais (VAE). O VQ-VAE usa incorporações latentes discretas para codificadores automáticos variacionais , ou seja, cada dimensão do z (vetor latente) é um número inteiro discreto, em vez da distribuição normal contínua geralmente usada durante a codificação das entradas.
Vaes consistem em 3 partes:
Bem, você pode perguntar sobre as diferenças que o VQ-VAES traz para a mesa. Vamos listá -los:
Muitos objetos importantes do mundo real são discretos. Por exemplo, em imagens, podemos ter categorias como "gato", "carro" etc. e pode não fazer sentido interpolar entre essas categorias. Representações discretas também são mais fáceis de modelar.
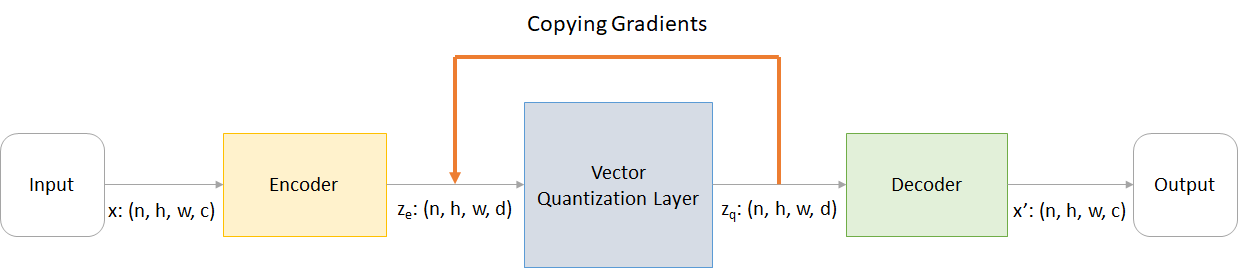
onde:
n : tamanho do loteh : Altura da imagemw : largura da imagemc : Número de canais na imagem de entradad : Número de canais no estado oculto Aqui está uma breve visão geral do funcionamento de uma rede VQ-VAE:
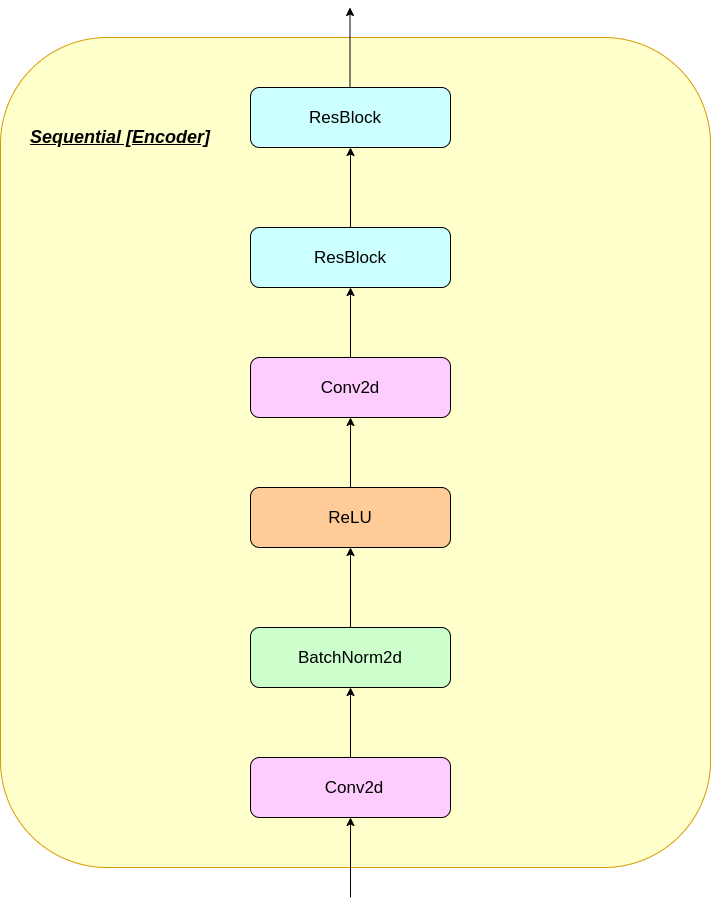
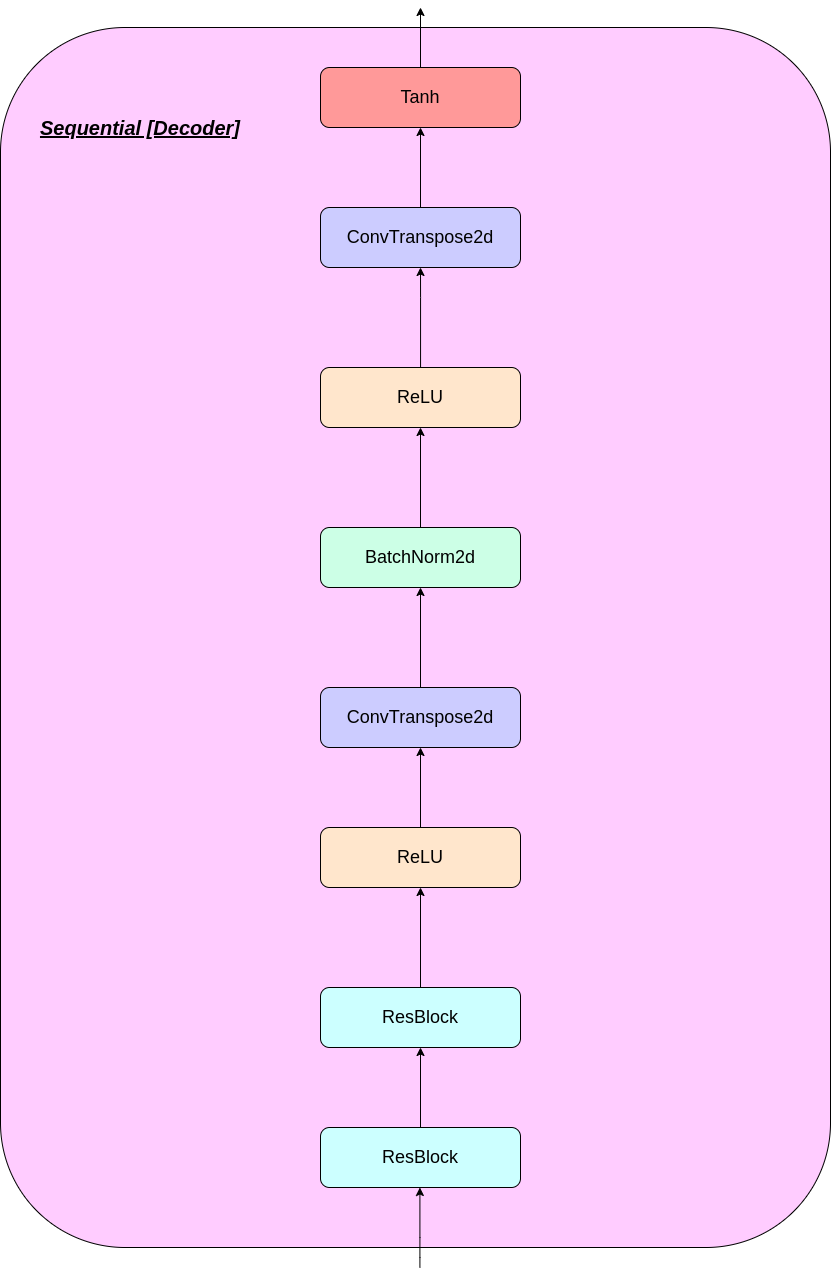
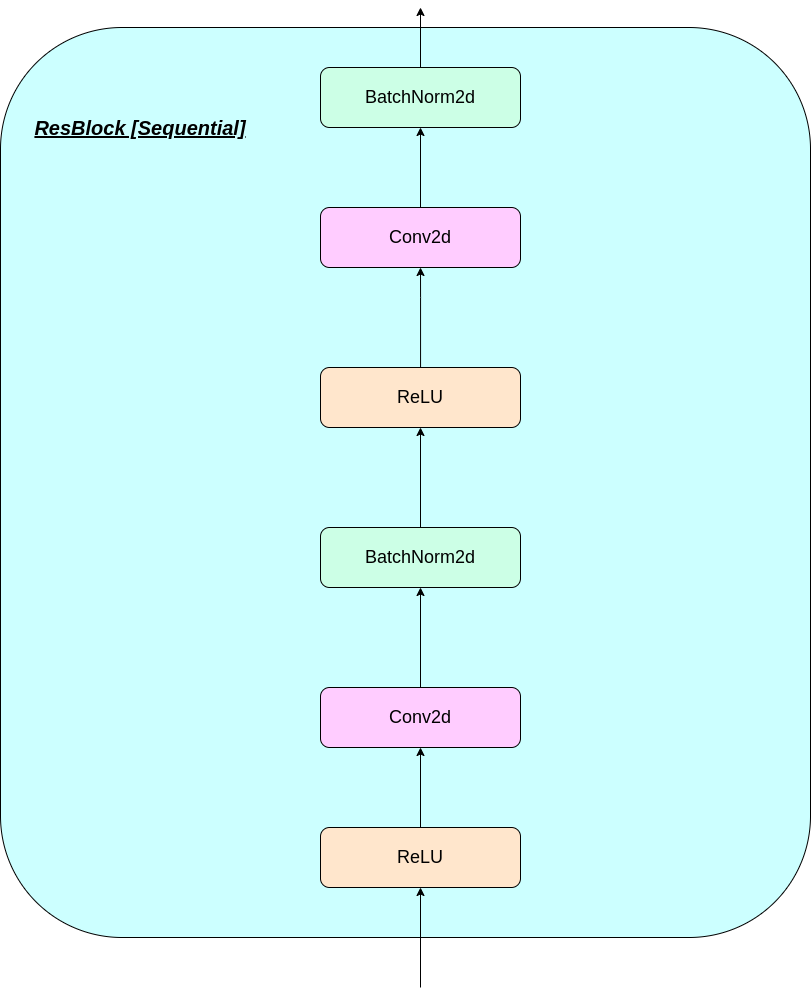
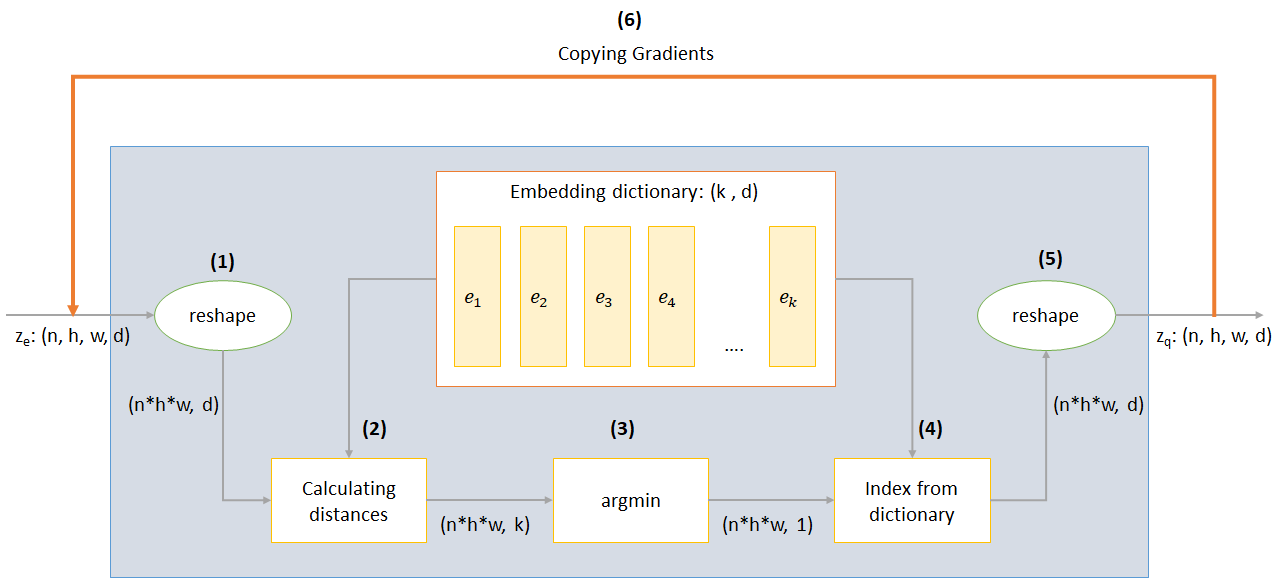
O funcionamento da camada VQ pode ser explicado em seis etapas, conforme numerado na figura:
O VQ-VAE usa 3 perdas para calcular a perda total durante o treinamento:
Perda de reconstrução: otimiza o decodificador e o codificador como VAE, ou seja, a diferença entre a imagem de entrada e a reconstrução:
reconstruction_loss = -log( p(x|z_q) )
Perda do livro de código: devido ao fato de os gradientes ignorarem a incorporação, um algoritmo de aprendizado de dicionário que usa um erro L2 para mover os vetores de incorporação E_I para a saída do codificador é usada.
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG representa o operador de gradiente de parada significa que nenhum gradiente flui através do que quer que seja aplicado)
Perda de compromisso: Como o volume do espaço de incorporação é adimensional, ele pode crescer arbitrariamente se as incorporações E_I não treinarem tão rápido quanto os parâmetros do codificador e, portanto, uma perda de compromisso é adicionada para garantir que o codificador se comprometa a uma incorporação.
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β é um hiperparâmetro que controla o quanto queremos pesar a perda de compromisso em comparação com outros componentes)
Você pode baixar o repo ou cloná -lo executando o seguinte no prompt de cmd
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
Você pode treinar o modelo do zero pelo seguinte comando (no Google Colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - Nome da pasta de dadosdata-folder - Nome da pasta de dadosdevice - Defina o dispositivo (CPU ou CUDA, padrão: CPU)hidden-size - tamanho dos vetores latentes (padrão: 40)k - Número de vetores latentes (Padrão: 512)batch-size - tamanho do lote (padrão: 128)num-epochs - Número de épocas (Padrão: 10)lr - Taxa de aprendizado para Adam Optimizer (Padrão: 2E -4)beta - Contribuição da perda de compromisso, entre 0,1 e 2,0 (padrão: 1,0)num-workers - Número de trabalhadores para trajetórias amostragem (Padrão: CPU_COUNT () - 1) O programa baixa automaticamente o conjunto de dados MNIST e o salva na pasta PATH_TO_MNIST_dataset (você precisa criar esta pasta). Isso só acontece uma vez.
Ele também cria uma pasta logs e pasta models e dentro deles cria uma pasta com o nome passado por você para salvar logs e modelar pontos de verificação dentro dele, respectivamente.
Para gerar novas imagens de Z amostradas aleatoriamente a partir de uma unidade Gaussian Run o seguinte comando (no Google Colab):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - nome do arquivo contendo o modeloinput - mnist ou aleatóriodevice - Defina o dispositivo (CPU ou CUDA, padrão: CPU)hidden-size - tamanho dos vetores latentes (padrão: 40)k - Número de vetores latentes (Padrão: 512)filename - nome com qual arquivo deve ser salvo Ele gera uma grade de 10*10 de imagens que são salvas em uma pasta chamada generatedImages .
Você pode usar um modelo pré-treinado baixando-o no link no model.txt .
O repositório contém os seguintes arquivos
modules.py - contém os diferentes módulos usados para fazer nosso modeloVQ-VAE.py -contém as funções e o código para treinar nosso modelo VQ-VAEvector_quantizer.py - As classes de quantização do vetor são definidas neste arquivogenerate-py -gera novas imagens de um modelo pré-treinadomodel.txt - contém um link para um modelo pré -treinadoREADME.md - Readme dando uma visão geral do repositórioreferences.txt - Referências usadas ao criar este repositórioreadme_images - tem várias imagens para o ReadMeMNIST - contém o conjunto de dados MNIST com zíper (embora ele seja baixado automaticamente, se necessário)Training track for VQ-VAE.txt -Contém os valores de perda durante o treinamento do nosso modelo VQ-VAElogs_VQ-VAE -contém os logs de tensorboard zipped para o nosso modelo VQ-VAE (criado automaticamente pelo programa)testers.py - contém algumas funções para testar nossos módulos definidosComando para executar o Tensorboard (no Google Colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
Imagem de treinamento
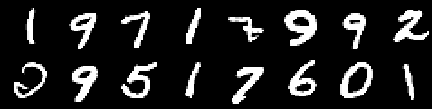
Imagem de 0th época

Imagem da 2ª época
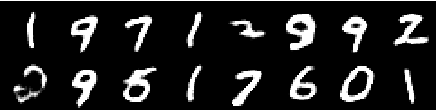
Imagem da 4ª época
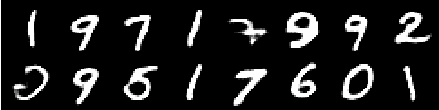
Imagem da 6ª época
Imagem da 8ª época
Imagem da 10ª época
As reconstruções continuam melhorando e, no final, quase se assemelham às imagens do treinamento_set que se reflete nos valores de perda (verifique a Training track for VQ-VAE.txt ).
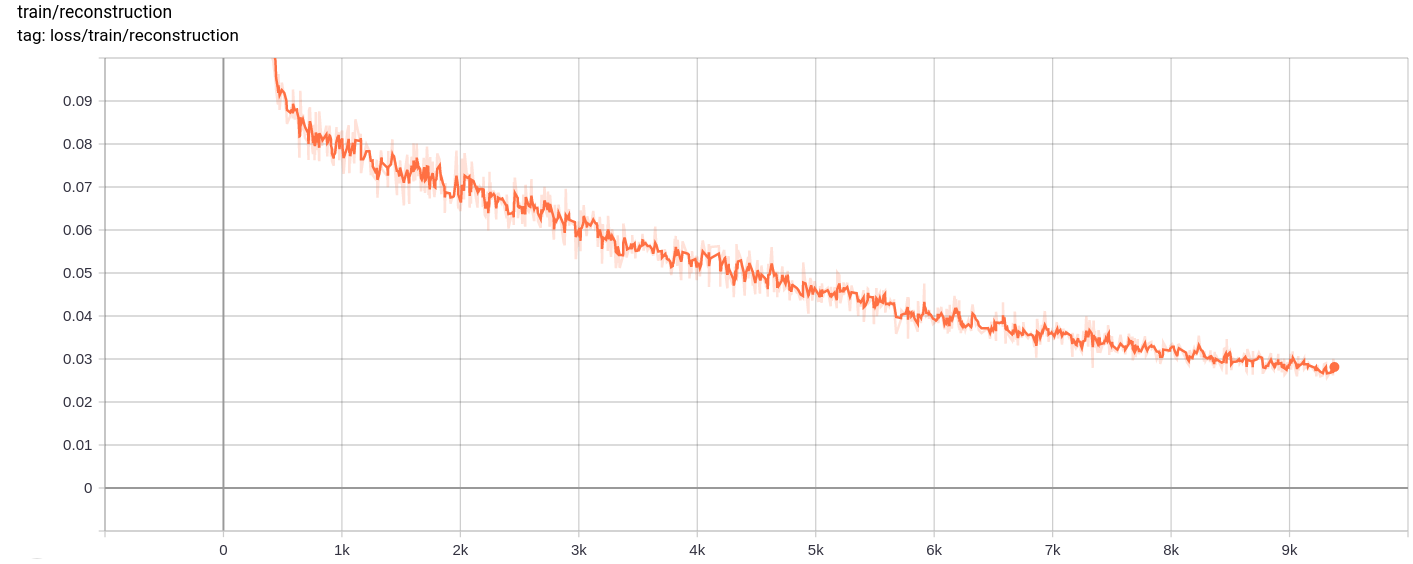
Perda de reconstrução
Perda de quantização
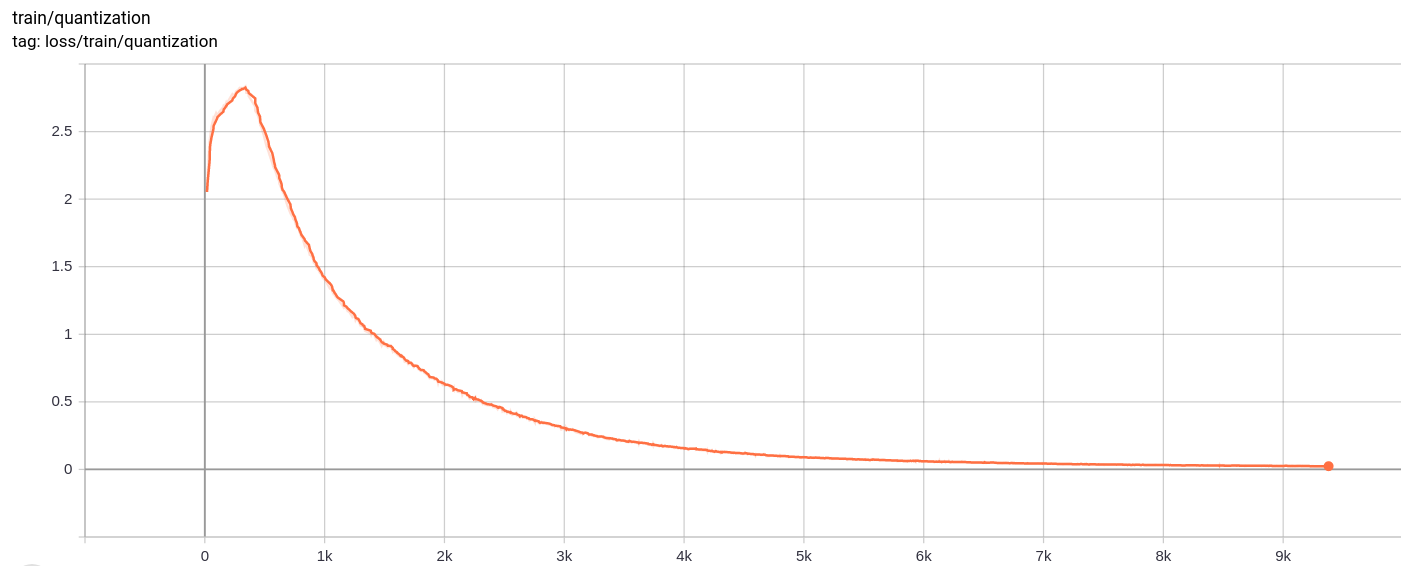
Total_loss
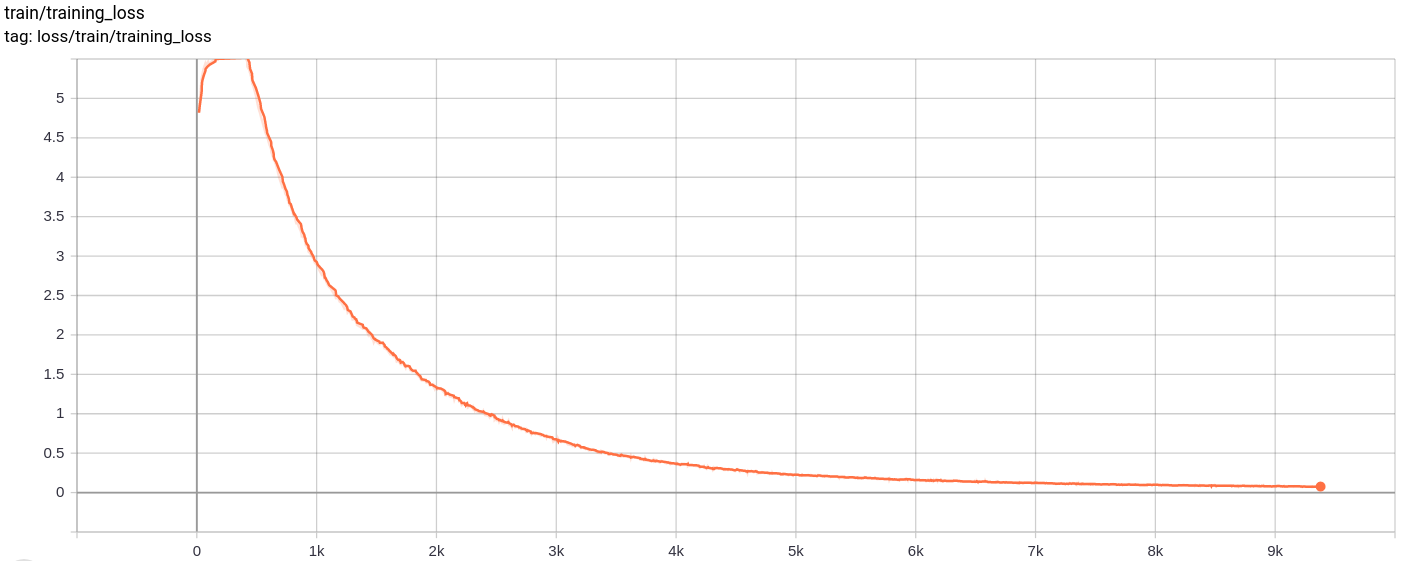
A perda total, a perda de reconstrução e a perda de quantização diminuem uniformemente conforme o esperado.
Testing_loss
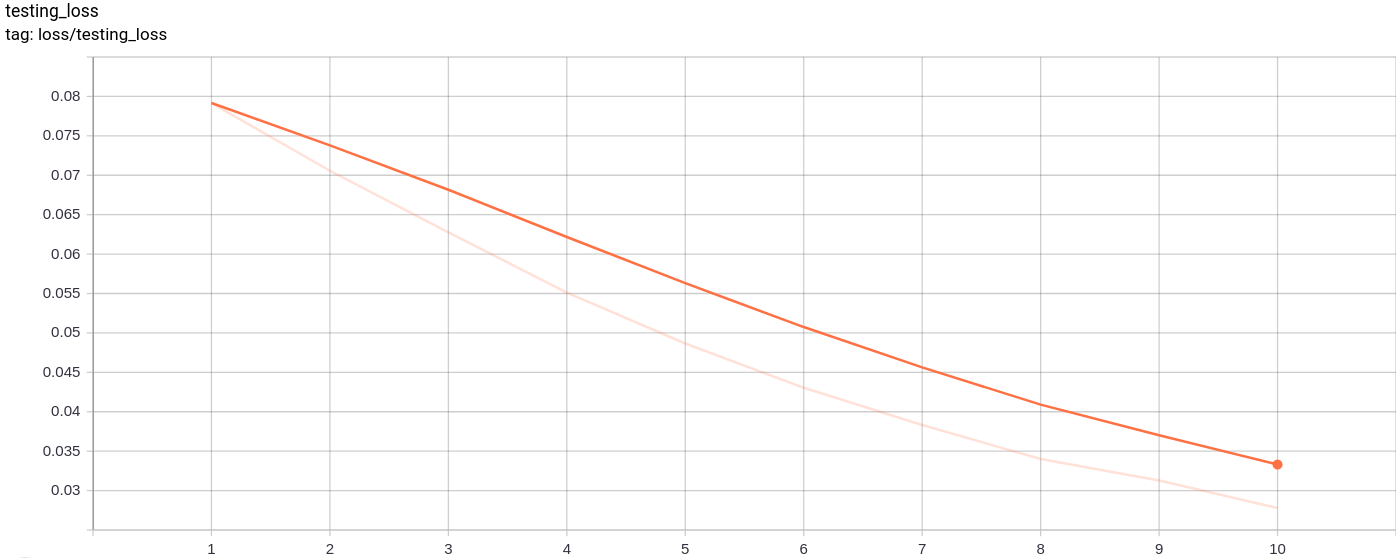
A perda de teste diminui uniformemente conforme o esperado.
A grade de imagem a seguir foi gerada após a passagem de imagens MNIST como entradas:

A geração é muito boa.
As seguintes grades de imagem foram geradas após a passagem de AZ amostrada aleatoriamente de uma unidade gaussiana como entrada para o modelo e depois passou pelo decodificador


As imagens não parecem perfeitas. Ajustando as dimensões do espaço latente, o número de vetores de incorporação etc. pode ajudar a gerar melhores imagens aleatórias.
O modelo foi treinado no Google Colab por 10 épocas, com tamanho de lote 128.
Depois de treinar, o modelo conseguiu reconstruir muito bem as imagens de entrada e também conseguiu gerar novas imagens, embora as imagens geradas não sejam tão boas.
O treinamento e a perda de testes também continuaram diminuindo quase monotonicamente.
Observei que o treinamento do modelo para mais de 10 a 20 épocas produziu resultados que sugeriam um provável sinal de excesso de ajuste no modelo. Além disso, experimentei diferentes dimensões do espaço lado e, na dimension = 40 produziram os melhores resultados. O melhor alcance para a dimensão chegou entre 16-42.
As fontes a seguir ajudaram muito a tornar este repositório


