Desenvolva a API REST para executar a tradução da máquina usando o modelo SEQ2SEQ. A implantação do modelo é feita usando a plataforma Google pode.
O projeto é criado com:
Os dados deste projeto estão disponíveis como arquivo de texto na fonte de dados, onde cada linha tem uma frase em Kannada e tradução em inglês com delimitador de espaço. Verificamos manualmente aleatoriamente para garantir que cada exemplo fizesse sentido.
Primeiro, construímos o modelo de decodificador do codificador, com mecanismo de atenção usando GRU RNN. O treinamento foi feito usando o script python disponível aqui
Crie um aplicativo de frasco que possa ser acesso a partir de máquina local no endereço http://127.0.0.1:5000/Predict.
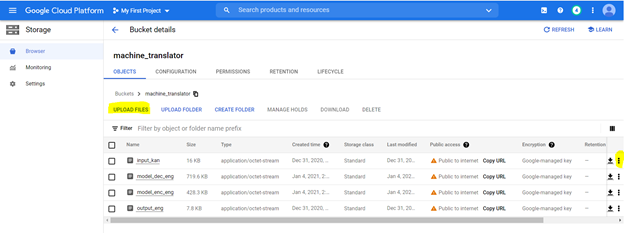
Usaremos o script para treinar o modelo. Depois de treinar o modelo, salvaremos os pesos do modelo em um arquivo .pt e armazenaremos no Google Cloud Storage. Também construímos o dicionário de vocabulário, indexando cada palavra para um número e apóia -os. Esses arquivos de picles também são armazenados no arquivo de armazenamento. Você pode acessá -los aqui, assim que esses arquivos estiverem em vigor, a implantação pode ser feita seguindo as etapas abaixo
Carregaremos os arquivos em um balde de armazenamento. Para criar um balde usando as seguintes opções, conforme destacado com as seguintes especificações
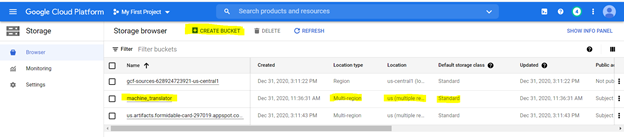
Para criar a função em nuvem, navegue para ela na plataforma GCP e use as opções destacadas para criar uma função,
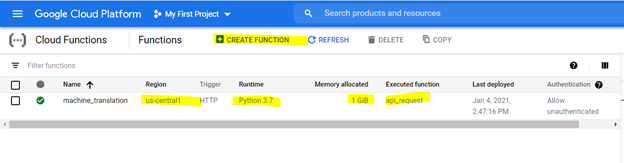
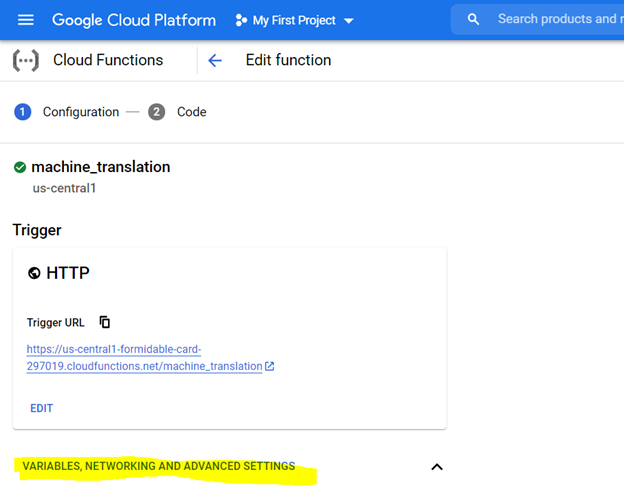
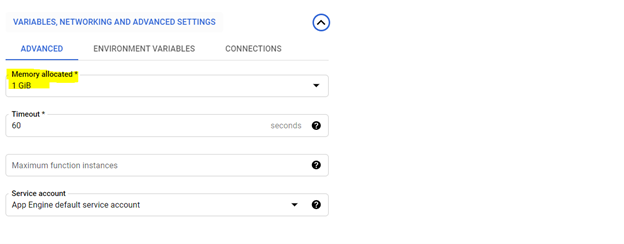
*Recomenda -se a alocação de 1 Gib Memory. Depois de definido, clique em 'Next' e implante o código no console da função em nuvem.
Para implantar o código, primeiro configure o console com as configurações destacadas abaixo e prepare o ambiente usando o arquivo de requisitos (isso é equivalente a Pip Install {Library}) como descrito abaixo,
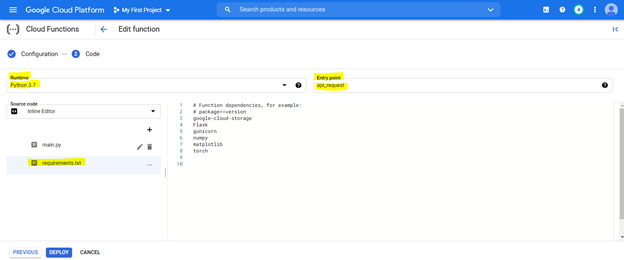
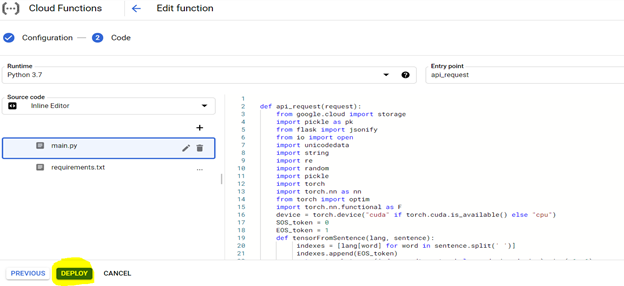

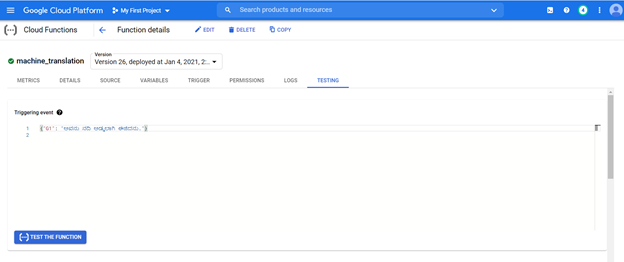

O modelo implantado pode ser acessado a partir do URL de qualquer sistema para traduzir frases de Kannada para o inglês.


