GroundingDINO
Grounding DINO SwinB

Idea-CVR, pesquisa de ideias
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang ? .
[ Paper ] [ Demo ] [ BibTex ]
Implementação de Pytorch e modelos pré -criados para o dino fundamental. Para detalhes, consulte o dino de aterramento de papel: Casando-se com o Dino com pré-treinamento fundamentado para detecção de objetos de set-sedem .
2023/07/18 : Lançamos Semantic-Sam, um modelo de segmentação de imagem universal para ativar o segmento e reconhecemos qualquer coisa em qualquer granularidade desejada. Código e ponto de verificação estão disponíveis!2023/06/17 : Fornecemos um exemplo para avaliar o dino de aterramento no desempenho do Coco Zero-Shot.2023/04/15 : Consulte o CV nas leituras selvagens para aqueles que estão interessados em reconhecimento de set-sedão!2023/04/08 : Lançamos demos para combinar dino de aterramento com gligen para edições de imagem mais controláveis.2023/04/08 : Lançamos demos para combinar dino de aterramento com difusão estável para edições de imagem.2023/04/06 : Construímos uma nova demonstração casando-se com Groundingdino com segmento-anything chamado de segmento fundamentado, qualquer coisa pretende apoiar a segmentação em Groundingdino.2023/03/28 : Um vídeo do YouTube sobre o DINO de aterramento e a engenharia de prompt de detecção de objetos básicos. [Skalskip]2023/03/28 : Adicione uma demonstração ao abraçar espaço no rosto!2023/03/27 : Suporte ao modo de CPU-somente. Agora o modelo pode ser executado em máquinas sem GPUs.2023/03/25 : Uma demonstração para o dino aterramento está disponível no Colab. [Skalskip]2023/03/22 : O código já está disponível! Casando -se com dino de aterramento e gligente
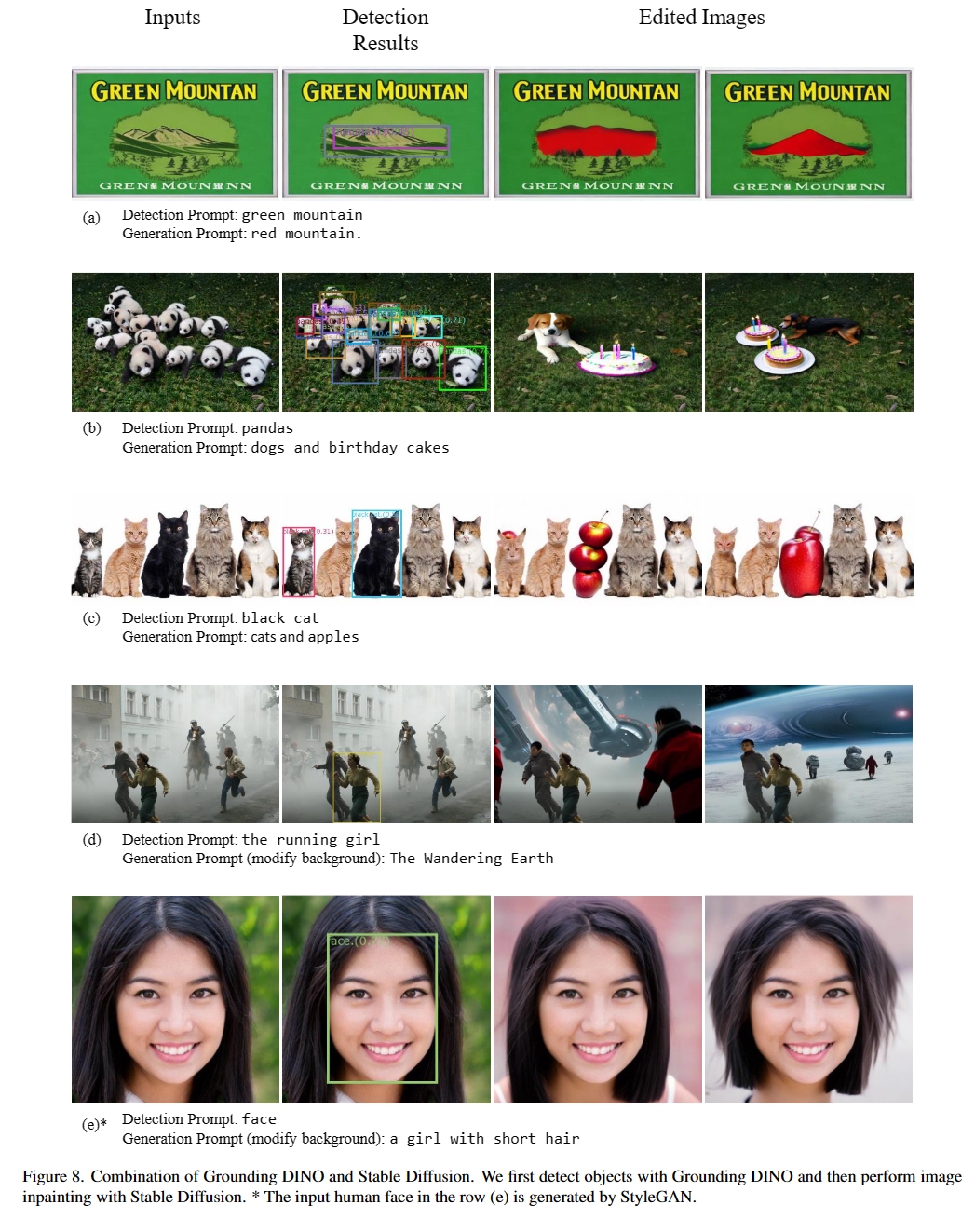
Casando -se com dino de aterramento e gligente (image, text) como entradas.900 (por padrão). Cada caixa possui pontuações de similaridade em todas as palavras de entrada. (Como mostrado nas figuras abaixo.)box_threshold .text_threshold como rótulos previstos.dogs da frase, two dogs with a stick. , você pode selecionar as caixas com maiores semelhanças de texto com dogs como saídas finais.. para o dino aterrado. 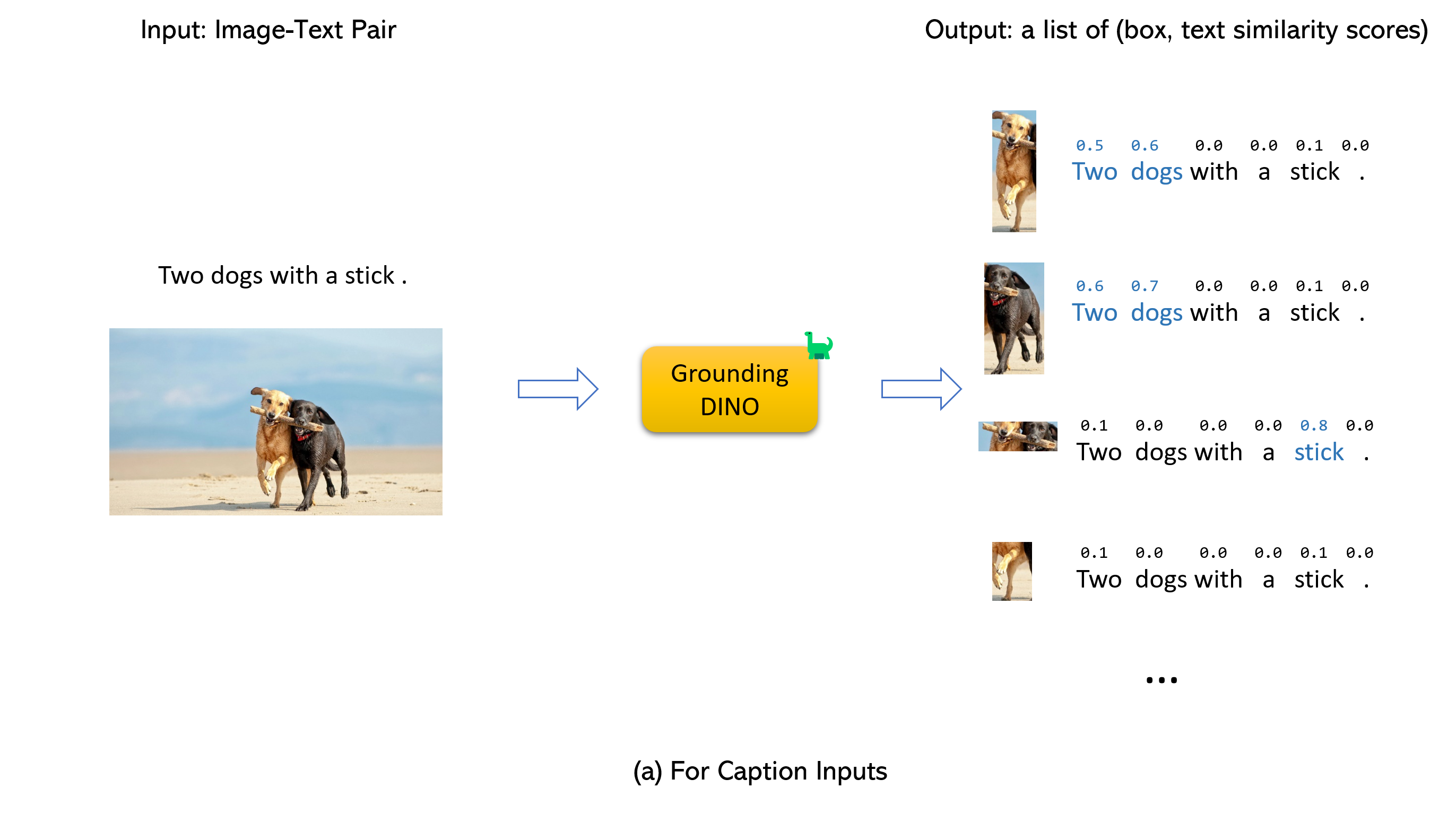
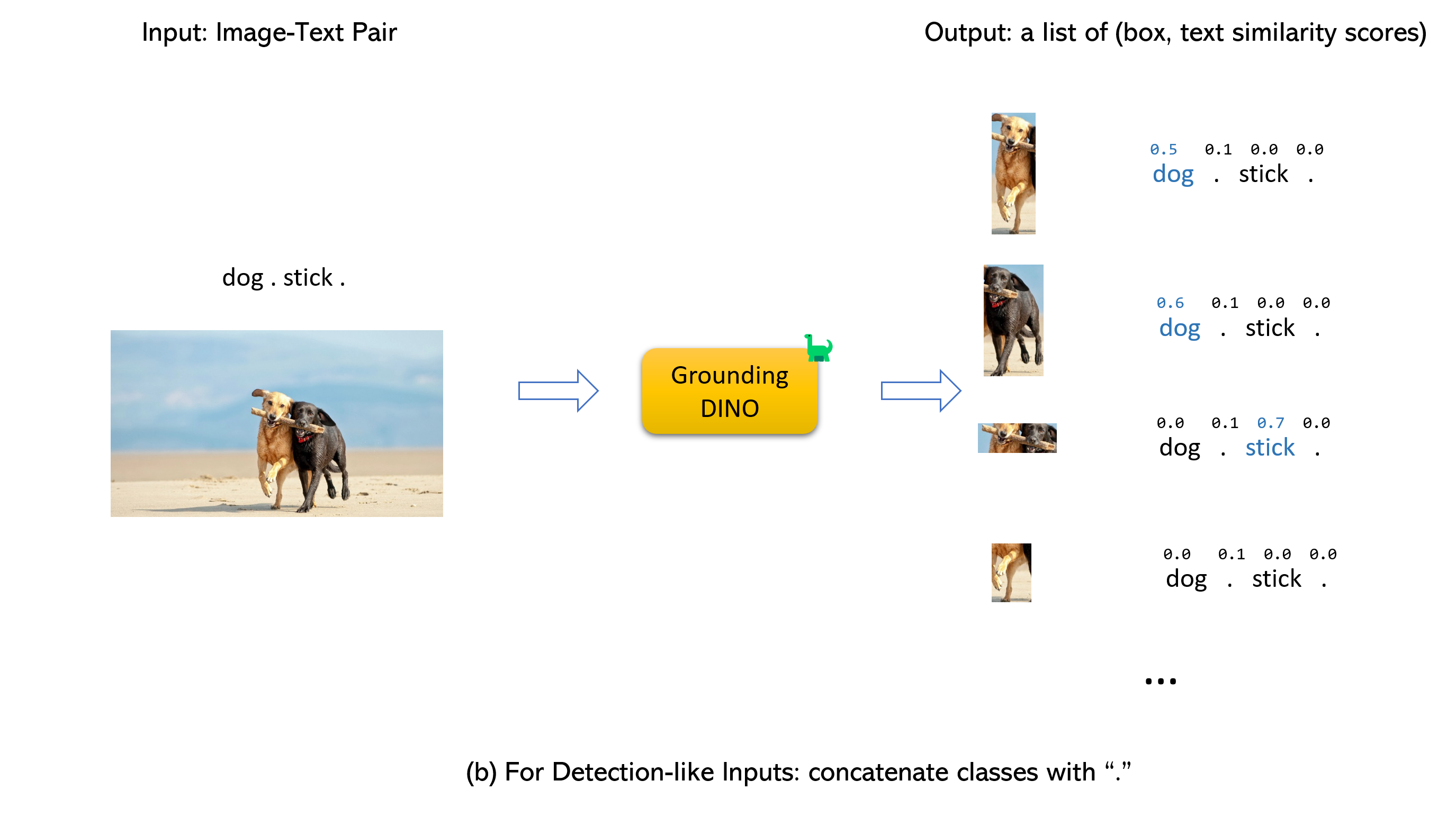
Observação:
CUDA_HOME está definida. Ele será compilado no modo somente CPU se nenhum CUDA disponível.Certifique -se de seguir as etapas de instalação estritamente, caso contrário, o programa poderá produzir:
NameError: name ' _C ' is not definedSe isso aconteceu, reinstale o Groundingdino ao reclone o git e faça todas as etapas de instalação novamente.
echo $CUDA_HOMESe não imprimir nada, significa que você não configurou o caminho/
Execute isso para que a variável de ambiente seja definida no shell atual.
export CUDA_HOME=/path/to/cuda-11.3Observe que a versão do CUDA deve estar alinhada com o seu tempo de execução do CUDA, pois pode existir vários CUDA ao mesmo tempo.
Se você deseja definir o CUDA_HOME permanentemente, armazene -o usando:
echo ' export CUDA_HOME=/path/to/cuda ' >> ~ /.bashrcDepois disso, obtenha o arquivo BASHRC e verifique CUDA_HOME:
source ~ /.bashrc
echo $CUDA_HOMENeste exemplo, /path/to/cuda-11.3 deve ser substituído pelo caminho em que seu kit de ferramentas CUDA está instalado. Você pode encontrar isso digitando qual NVCC em seu terminal:
Por exemplo, se a saída for/usr/local/cuda/bin/nvcc, então:
export CUDA_HOME=/usr/local/cudaInstalação:
1.Cone o repositório de Groundingdino do GitHub.
git clone https://github.com/IDEA-Research/GroundingDINO.git cd GroundingDINO/pip install -e .mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..Verifique seu ID da GPU (apenas se você estiver usando uma GPU)
nvidia-smi Substitua {GPU ID} , image_you_want_to_detect.jpg e "dir you want to save the output" com valores apropriados no comando a seguir
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
-i image_you_want_to_detect.jpg
-o " dir you want to save the output "
-t " chair "
[--cpu-only] # open it for cpu modeSe você deseja especificar as frases para detectar, aqui está uma demonstração:
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p ./groundingdino_swint_ogc.pth
-i .asset/cat_dog.jpeg
-o logs/1111
-t " There is a cat and a dog in the image . "
--token_spans " [[[9, 10], [11, 14]], [[19, 20], [21, 24]]] "
[--cpu-only] # open it for cpu mode Os token_spans especificam as posições de início e final de uma frases. Por exemplo, a primeira frase é [[9, 10], [11, 14]] . "There is a cat and a dog in the image ."[9:10] = 'a' , "There is a cat and a dog in the image ."[11:14] = 'cat' . Portanto, refere -se à frase a cat . Da mesma forma, o [[19, 20], [21, 24]] refere -se à frase a dog .
Consulte a demo/inference_on_a_image.py para obter mais detalhes.
Correndo com Python:
from groundingdino . util . inference import load_model , load_image , predict , annotate
import cv2
model = load_model ( "groundingdino/config/GroundingDINO_SwinT_OGC.py" , "weights/groundingdino_swint_ogc.pth" )
IMAGE_PATH = "weights/dog-3.jpeg"
TEXT_PROMPT = "chair . person . dog ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source , image = load_image ( IMAGE_PATH )
boxes , logits , phrases = predict (
model = model ,
image = image ,
caption = TEXT_PROMPT ,
box_threshold = BOX_TRESHOLD ,
text_threshold = TEXT_TRESHOLD
)
annotated_frame = annotate ( image_source = image_source , boxes = boxes , logits = logits , phrases = phrases )
cv2 . imwrite ( "annotated_image.jpg" , annotated_frame )UI da web
Também fornecemos um código de demonstração para integrar o Dino de aterramento com a UI da Web Gradio. Consulte a demo/gradio_app.py para obter mais detalhes.
Notebooks
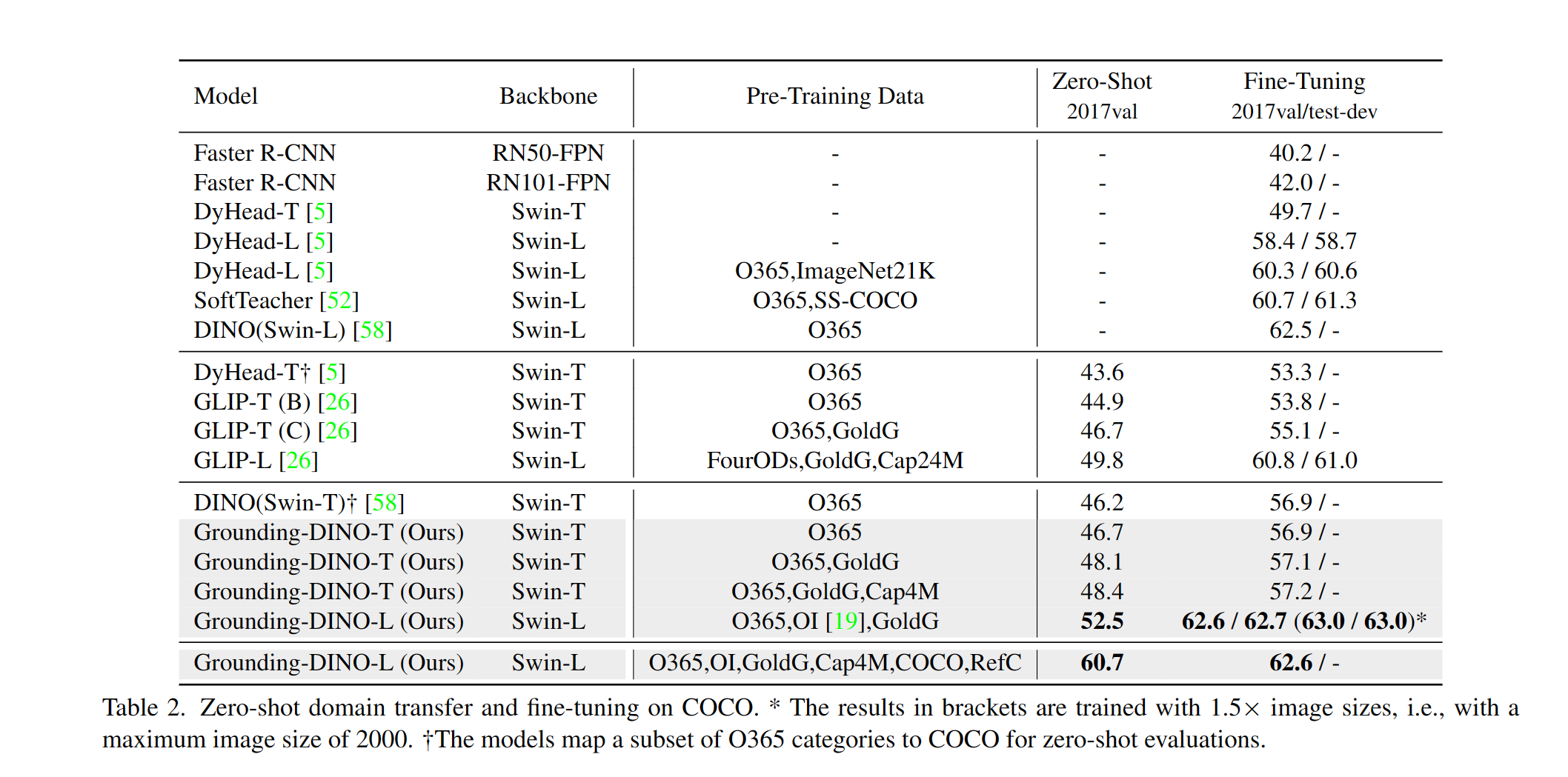
Fornecemos um exemplo para avaliar o desempenho do Dino Zero-Shot no Coco. Os resultados devem ser 48,5 .
CUDA_VISIBLE_DEVICES=0
python demo/test_ap_on_coco.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
--anno_path /path/to/annoataions/ie/instances_val2017.json
--image_dir /path/to/imagedir/ie/val2017| nome | espinha dorsal | Dados | Box AP no Coco | Ponto de verificação | Config | |
|---|---|---|---|---|---|---|
| 1 | Groundingdino-t | Swin-t | O365, GOLDG, CAP4M | 48.4 (zero tiro) / 57.2 (tune fino) | Link github | Link hf | link |
| 2 | Groundingdino-B | Swin-B | Coco, O365, Goldg, Cap4m, OpenImage, Odinw-35, Refcoco | 56.7 | Link github | Link hf | link |
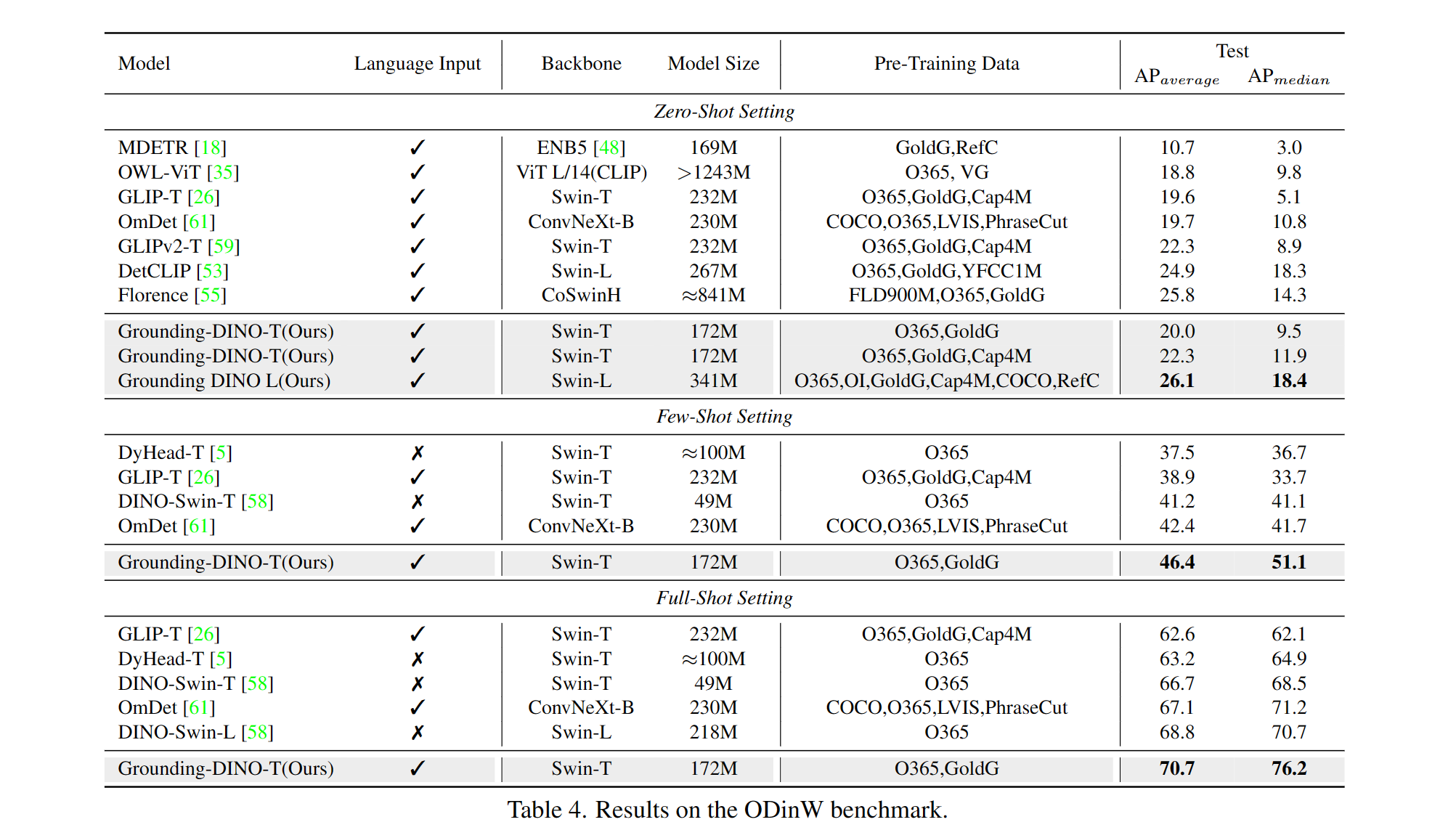

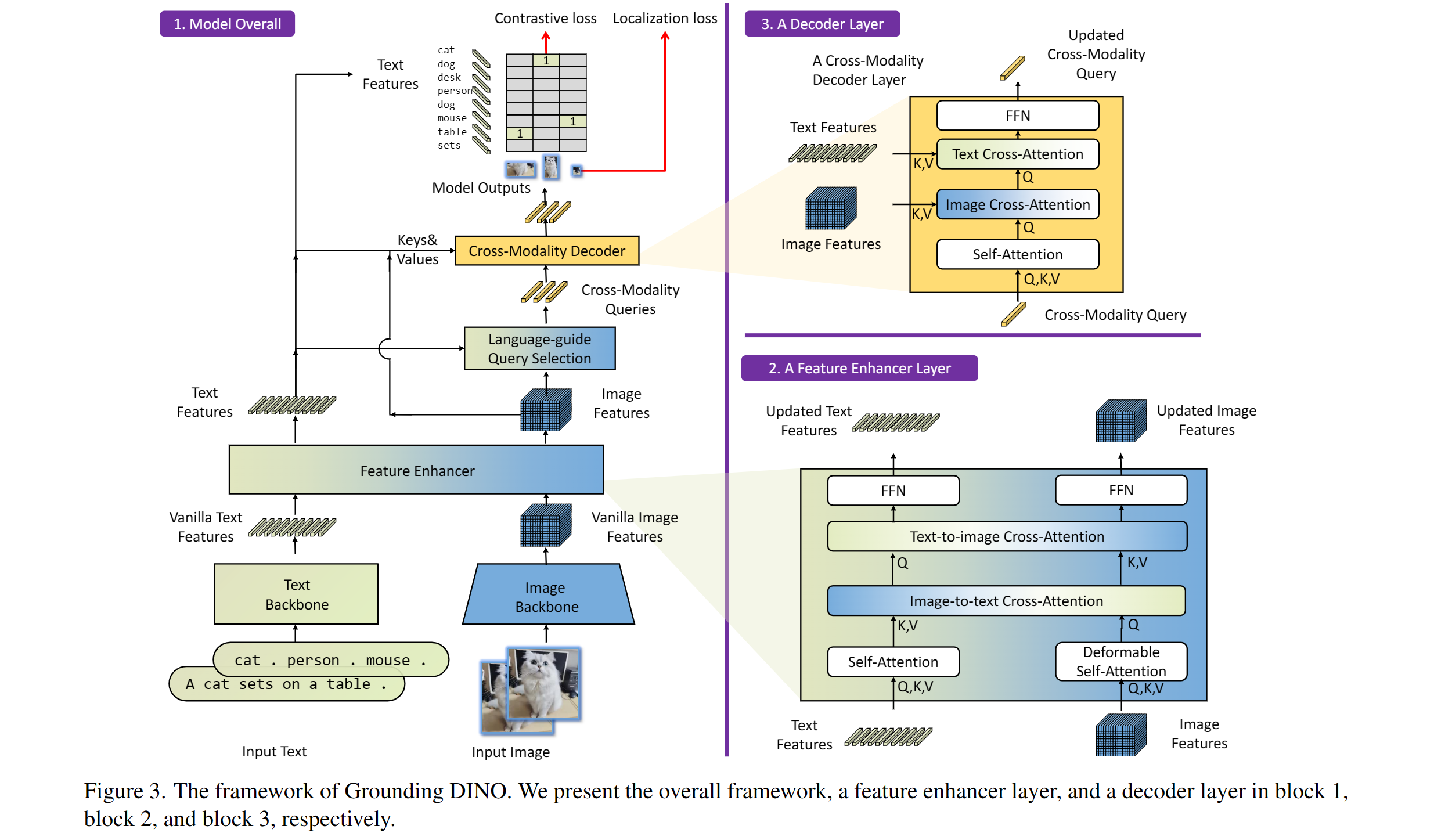
Inclui: um backbone de texto, um backbone de imagem, um intensificador de recursos, uma seleção de consulta guiada por idiomas e um decodificador de modalidade cruzada.
Nosso modelo está relacionado a Dino e Glip. Obrigado pelo seu ótimo trabalho!
Agradecemos também ao excelente trabalho anterior, incluindo Detr, Deformable DeTr, SMCA, Condicional Detr, Anchor Detr, Dynamic DeTr, DAB-Detr, DN-Detr, etc. Mais trabalhos relacionados estão disponíveis no Awesome Detection Transformer. Uma nova caixa de ferramentas também está disponível.
Agradecemos difusão e gliga estáveis por seus modelos incríveis.
Se você achar nosso trabalho útil para sua pesquisa, considere citar a seguinte entrada do Bibtex.
@article { liu2023grounding ,
title = { Grounding dino: Marrying dino with grounded pre-training for open-set object detection } ,
author = { Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others } ,
journal = { arXiv preprint arXiv:2303.05499 } ,
year = { 2023 }
}

