
A implementação oficial da GFT, um modelo de fundação de tarefas cruzadas de domínio cruzado nos gráficos. O logotipo é gerado por Dall · e 3.
De autoria de Zehong Wang, Zheyuan Zhang, Nitesh V Chawla, Chuxu Zhang e Yanfang Ye.
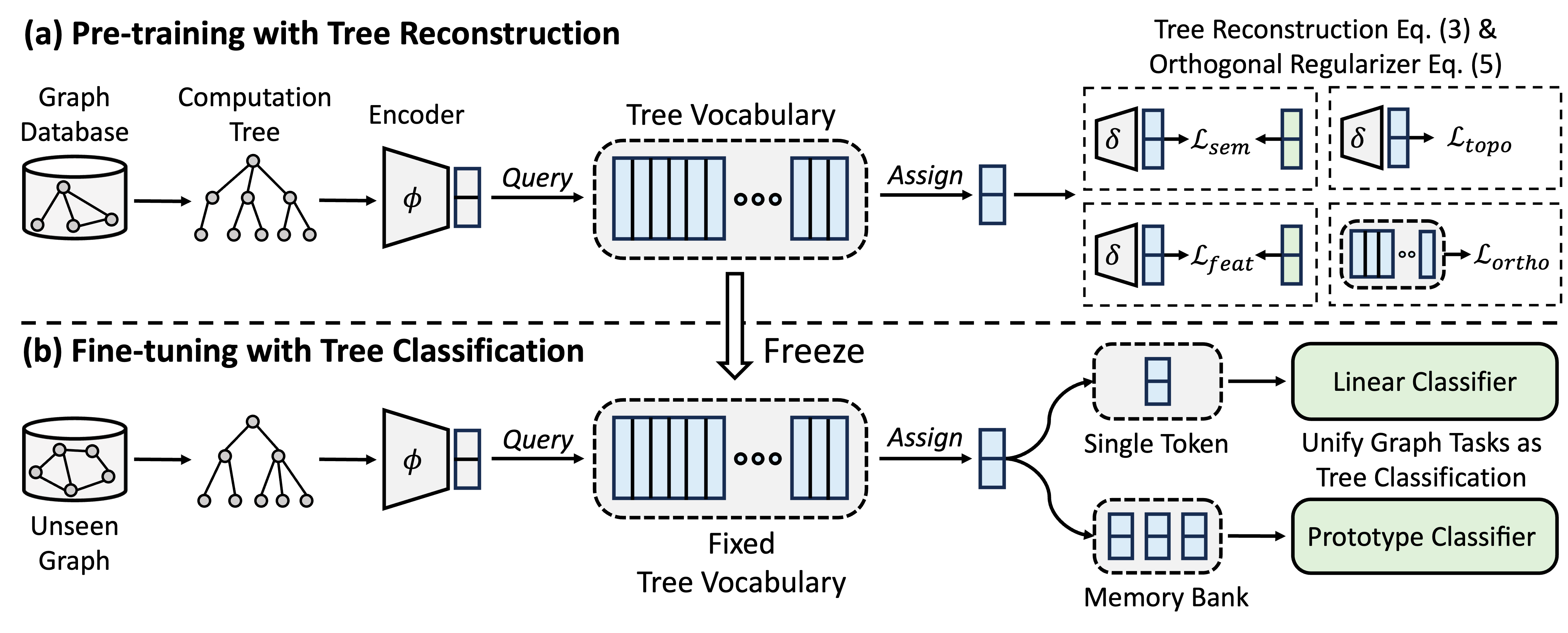
A GFT é um modelo de fundação gráfico de domínio cruzado e de tarefas cruzadas, que trata as árvores de computação como padrões transferíveis para obter um vocabulário de árvore transferível. Além disso, a GFT fornece uma estrutura unificada para alinhar tarefas relacionadas a gráficos, permitindo um único modelo de gráfico, por exemplo, GNN, para lidar em conjunto com tarefas no nível do nó, no nível da borda e no nível do gráfico.
Durante o pré-treinamento, o modelo codifica o conhecimento geral de um banco de dados de gráficos em um vocabulário de árvore através de uma tarefa de reconstrução de árvores. No ajuste fino, o vocabulário de árvore instruído é aplicado para unificar tarefas relacionadas a gráficos como tarefas de classificação de árvores, adaptando o conhecimento geral adquirido a tarefas específicas.
Você pode usar o CONDA para instalar o ambiente. Por favor, execute o seguinte script. Executamos todas as experiências em uma única GPU A40 48G, mas uma GPU com memória 24G é suficiente para lidar com todos os conjuntos de dados com mini-lote.
conda env create -f environment.yml
conda activate GFT
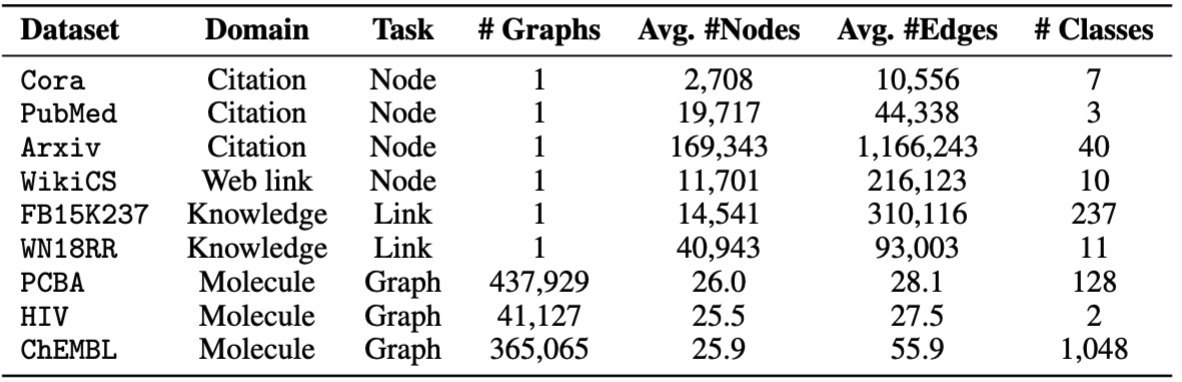
Usamos conjuntos de dados fornecidos pela OFA. Você pode executar o pretrain.py para baixar automaticamente os conjuntos de dados, que serão baixados para /data por padrão. O pipeline pré -processará automaticamente os conjuntos de dados convertendo descrições textuais em incorporações textuais.
Como alternativa, você pode baixar nossos conjuntos de dados e descompactação pré -processados na pasta /data .
O código da GFT é apresentado na pasta /GFT . A estrutura é a seguinte.
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
Você pode executar pretrain.py para pré-treinar em uma ampla gama de gráficos e finetune.py para adaptação a certas tarefas a jusante com a Finetuning básica ou o aprendizado de poucos anos.
Para reproduzir os resultados, fornecemos hiper-parâmetros detalhados para pré-treinamento e finetuning, mantidos em config/pretrain.yaml e config/finetune.yaml , respectivamente. Para alavancar os hiper-parâmetros padrão, fornecemos um comando --use_params para o pré-atreto e o Finetune.
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
Para a Finetuning, fornecemos oito conjuntos de dados, incluindo cora , pubmed , wikics , arxiv , WN18RR , FB15K237 , chemhiv e chempcba .
Como alternativa, você pode executar o script para reproduzir os experimentos.
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
NOTA: O modelo pré -terenciado será armazenado em ckpts/pretrain_model/ por padrão.
# The basic command for pretraining GFT
python GFT/pretrain.py
Quando você executa pretrain.py , pode personalizar os conjuntos de dados e hiper-parâmetros pré-treinamento.
Você pode usar --pretrain_dataset (ou --pt_data ) para definir os conjuntos de dados de pré -rAins usados e os pesos correspondentes. A configuração de dados predefinida está em config/pt_data.yaml , com as seguintes estruturas.
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
No caso acima, all é o nome da configuração, o que significa que todos os conjuntos de dados são usados em pré -treinamento. Para cada conjunto de dados, há um pares de valor-chave, onde a chave é o nome do conjunto de dados e o valor é o peso da amostragem. Por exemplo, cora: 5 significa que o conjunto de dados cora será amostrado 5 vezes em uma única época. Você pode projetar sua própria combinação de conjunto de dados para GFT pré -treinamento.
Você pode personalizar a fase de pré-treinamento alterando hiper-parâmetros do codificador, quantização de vetores, treinamento de modelos.
--pretrain_dataset : indique o conjunto de dados pré-treinamento. O mesmo para o acima.--use_params : use os hiper-parâmetros predefinidos.--seed : a semente usada para pré-treinamento.--hidden_dim : a dimensão na camada oculta de GNNs.--num_layers : as camadas GNN.--activation : a função de ativação.--backbone : o backbone gnn.--normalize : a camada de normalização.--dropout : a queda da camada GNN.--code_dim : a dimensão de cada código no vocabulário.--codebook_size : o número de códigos no vocabulário.--codebook_head : o número de cabeças de código de código. Se o número for maior que 1, você usará em conjunto vários vocabulários.--codebook_decay : a taxa de decaimento dos códigos.--commit_weight : o peso do termo de compromisso.--pretrain_epochs : o número de épocas.--pretrain_lr : a taxa de aprendizado.--pretrain_weight_decay : o peso do L2 regularizer.--pretrain_batch_size : o tamanho do lote.--feat_p : a taxa de corrupção do recurso.--edge_p : a taxa de corrupção de borda/estrutura.--topo_recon_ratio : a proporção das bordas deve ser reconstruída.--feat_lambda : o peso da perda de recursos.--topo_lambda : o peso da perda de topologia.--topo_sem_lambda : o peso da perda de topologia nos recursos da borda de reconstrução.--sem_lambda : O peso da perda semântica.--sem_encoder_decay : A taxa de atualização do momento para o codificador semântico. # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
Você pode definir --dataset para indicar o conjunto de dados a jusante e --use_params para usar os hiper-parâmetros predefinidos para cada conjunto de dados. Outros hiper-parâmetros que você pode indicar são apresentados da seguinte forma.
Para gráficos com 1 divisão predefinida, você pode definir --repeat para realizar várias experiências.
--hidden_dim : a dimensão na camada oculta de GNNs.--num_layers : as camadas GNN.--activation : a função de ativação.--backbone : o backbone gnn.--normalize : a camada de normalização.--dropout : a queda da camada GNN.--code_dim : a dimensão de cada código no vocabulário.--codebook_size : o número de códigos no vocabulário.--codebook_head : o número de cabeças de código de código. Se o número for maior que 1, você usará em conjunto vários vocabulários.--codebook_decay : a taxa de decaimento dos códigos.--commit_weight : o peso do termo de compromisso.--finetune_epochs : o número de épocas.--finetune_lr : a taxa de aprendizado.--early_stop : a época máxima de parada precoce.--batch_size : Se definido como 0, realize treinamento completo em gráfico. --lambda_proto : o peso do classificador de protótipo no Finetuning.
--lambda_act : O peso do classificador linear na Finetuning.
--trade_off : o trade-off entre usar o protótipo classier ou usar classificador linear em inferência.
Você pode adicionar --no_lin_clf ou --no_proto_clf para evitar o uso de classificador linear ou classificador de protótipo, respectivamente. Observe que esses dois termos são conflitos, pois você deve usar pelo menos um classificador.
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
Você pode definir --dataset para indicar o conjunto de dados a jusante e --use_params para usar os hiper-parâmetros predefinidos para cada conjunto de dados. Outros hiper-parâmetros que você pode indicar são apresentados da seguinte forma.
Os hiper-parâmetros dedicados para aprendizado de poucos tiro são
--n_train : o número de instâncias de treinamento por classe para o Finetuning the Model. Observe que o pequeno n_train alcança um desempenho desejável --n_task : o número de tarefas amostradas.--n_way : o número de maneiras.--n_query : o tamanho do conjunto de consultas por maneira.--n_shot : o tamanho do conjunto de suporte por maneira.--hidden_dim : a dimensão na camada oculta de GNNs.--num_layers : as camadas GNN.--activation : a função de ativação.--backbone : o backbone gnn.--normalize : a camada de normalização.--dropout : a queda da camada GNN.--code_dim : a dimensão de cada código no vocabulário.--codebook_size : o número de códigos no vocabulário.--codebook_head : o número de cabeças de código de código. Se o número for maior que 1, você usará em conjunto vários vocabulários.--codebook_decay : a taxa de decaimento dos códigos.--commit_weight : o peso do termo de compromisso.--finetune_epochs : o número de épocas.--finetune_lr : a taxa de aprendizado.--early_stop : a época máxima de parada precoce.--batch_size : Se definido como 0, realize treinamento completo em gráfico. --lambda_proto : o peso do classificador de protótipo no Finetuning.
--lambda_act : O peso do classificador linear na Finetuning.
--trade_off : o trade-off entre usar o protótipo classier ou usar classificador linear em inferência.
Você pode adicionar --no_lin_clf ou --no_proto_clf para evitar o uso de classificador linear ou classificador de protótipo, respectivamente. Observe que esses dois termos são conflitos, pois você deve usar pelo menos um classificador.
Os resultados experimentais podem variar devido à inicialização randomizada durante o pré -treinamento. Fornecemos os resultados experimentais usando diferentes sementes aleatórias (isto é, 1-5) em pré-treinamento para mostrar o impacto potencial da inicialização aleatória.
| Cora | PubMed | Wiki-cs | Arxiv | WN18RR | FB15K237 | HIV | PCBA | Média | |
|---|---|---|---|---|---|---|---|---|---|
| Semente = 1 | 78,58 ± 0,90 | 77,55 ± 1,54 | 79,38 ± 0,57 | 72,24 ± 0,16 | 91,56 ± 0,33 | 89,67 ± 0,35 | 72,69 ± 1,93 | 78,24 ± 0,23 | 79.99 |
| Semente = 2 | 78,27 ± 1,26 | 76,41 ± 1,36 | 79,36 ± 0,62 | 72,13 ± 0,24 | 91,72 ± 0,19 | 89,66 ± 0,31 | 71,62 ± 2,45 | 78,20 ± 0,33 | 79.67 |
| Semente = 3 | 78,16 ± 1,62 | 76,28 ± 1,37 | 79,32 ± 0,65 | 72,13 ± 0,30 | 91,57 ± 0,44 | 89,78 ± 0,23 | 71,58 ± 2,28 | 78,12 ± 0,37 | 79.62 |
| Semente = 4 | 78,42 ± 1,37 | 75,76 ± 1,58 | 79,44 ± 0,62 | 72,36 ± 0,34 | 91,70 ± 0,24 | 89,73 ± 0,21 | 72,57 ± 2,46 | 78,34 ± 0,27 | 79.79 |
| Semente = 5 | 78,56 ± 1,62 | 76,49 ± 2,00 | 79,27 ± 0,55 | 72,18 ± 0,26 | 91,47 ± 0,39 | 89,80 ± 0,19 | 72,27 ± 0,93 | 78,31 ± 0,34 | 79.79 |
| Relatado | 78,62 ± 1,21 | 77,19 ± 1,99 | 79,39 ± 0,42 | 71,93 ± 0,12 | 91,91 ± 0,34 | 89,72 ± 0,20 | 72,67 ± 1,38 | 77,90 ± 0,64 | 79.92 |
Para garantir melhor a reprodutibilidade, fornecemos os pontos de verificação da semente = 1 neste link. Selecionamos isso devido ao seu melhor desempenho médio. Você pode descompactar o arquivo baixado no caminho ckpts/pretrain_model/ e definir o --pt_seed 1 ao usar finetune.py para aproveitar delicadamente nossos pontos de verificação fornecidos.
Entre em contato com [email protected] ou abra um problema se tiver dúvidas.
Se você achar que o repositório é útil para sua pesquisa, cite o artigo original corretamente.
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}Este repositório é baseado na base de código da OFA, PYG, OGB e VQ. Obrigado pelo compartilhamento deles!


