flash attention
v2.7.0
Este repositório fornece a implementação oficial da Flashattion e Flashattion-2 dos documentos a seguir.
Flashattion: atenção exata rápida e com eficiência de memória com a consciência de IO
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
Papel: https://arxiv.org/abs/2205.14135
Artigo do IEEE Spectrum sobre nossa apresentação à referência MLPerf 2.0 usando a Flashattion.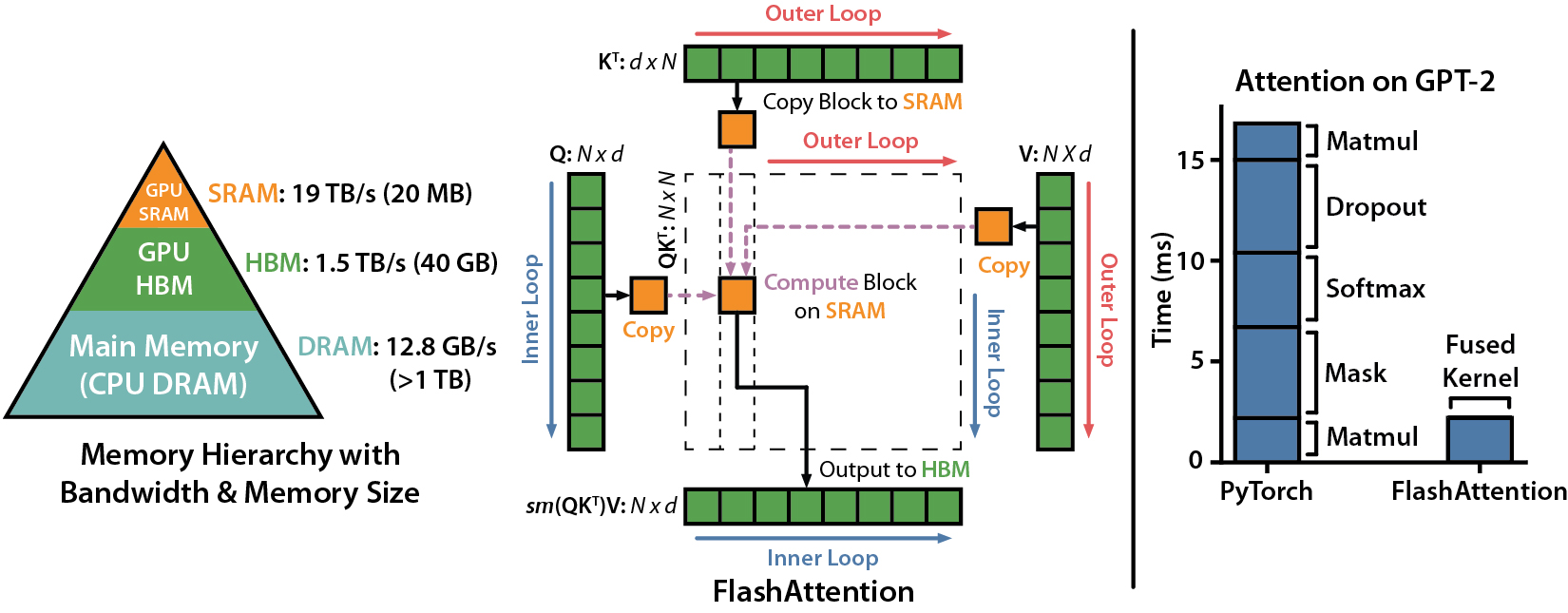
Flashattion-2: atenção mais rápida com melhor paralelismo e partição de trabalho
Tri Dao
Papel: https://tridao.me/publications/flash2/flash2.pdf

Ficamos muito felizes em ver o Flashattion sendo amplamente adotado em tão pouco tempo após seu lançamento. Esta página contém uma lista parcial de lugares onde o Flashattion está sendo usado.
Flashattion e Flashattion-2 são gratuitos para usar e modificar (consulte a licença). Cite e credite a Flashattion se você usá -la.
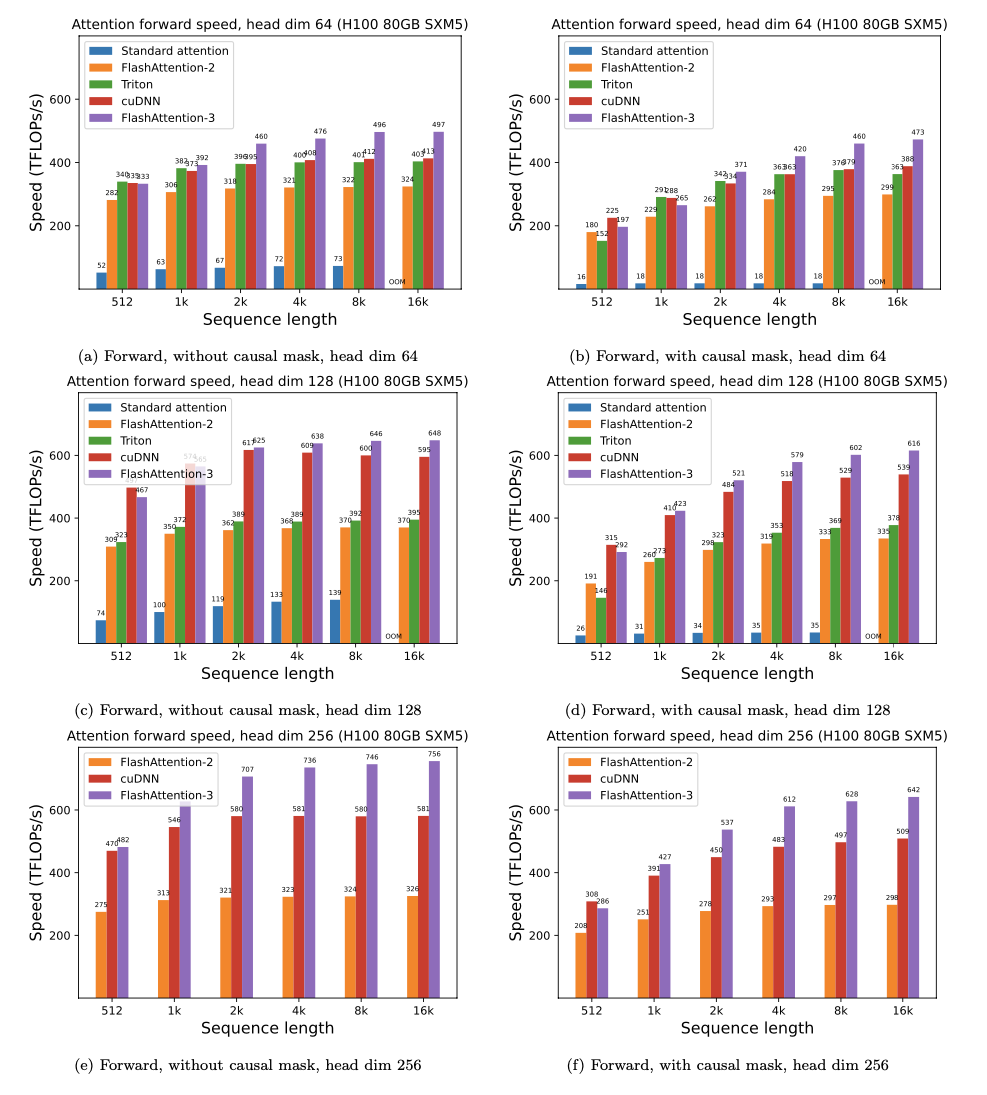
Flashattion-3 é otimizado para GPUs Hopper (por exemplo, H100).
BlogPost: https://tridao.me/blog/2024/flash3/
Papel: https://tridao.me/publications/flash3/flash3.pdf
Esta é uma versão beta para testar / benchmarking antes de integrarmos isso com o restante do repositório.
Lançado atualmente:
Requisitos: GPU H100 / H800, CUDA> = 12.3.
Por enquanto, recomendamos o CUDA 12.3 para o melhor desempenho.
Para instalar:
cd hopper
python setup.py installPara executar o teste:
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.pyRequisitos:
packaging pacote python ( pip install packaging )ninja python ( pip install ninja ) * * Verifique se o ninja está instalado e que funcione corretamente (por exemplo, ninja --version e echo $? Deve retornar o código de saída 0). Se não (às vezes ninja --version , echo $? Retorna um código de saída diferente de zero), desinstale e reinstale ninja ( pip uninstall -y ninja && pip install ninja ). Sem ninja , a compilação pode levar muito tempo (2H), pois não usa vários núcleos de CPU. Com ninja Compily leva de 3 a 5 minutos em uma máquina de 64 núcleos usando o CUDA Toolkit.
Para instalar:
pip install flash-attn --no-build-isolationComo alternativa, você pode compilar da fonte:
python setup.py install Se sua máquina tiver menos de 96 GB de RAM e muitos núcleos de CPU, ninja poderá executar muitos trabalhos de compilação paralela que poderiam esgotar a quantidade de RAM. Para limitar o número de trabalhos de compilação paralela, você pode definir a variável de ambiente MAX_JOBS :
MAX_JOBS=4 pip install flash-attn --no-build-isolation Interface: src/flash_attention_interface.py
Requisitos:
Recomendamos o contêiner Pytorch da NVIDIA, que possui todas as ferramentas necessárias para instalar o Flashattion.
Flashattion-2 com CUDA atualmente suporta:
A versão ROCM usa composable_kernel como back -end. Ele fornece a implementação do Flashattion-2.
Requisitos:
Recomendamos o contêiner Pytorch da ROCM, que possui todas as ferramentas necessárias para instalar o Flashattion.
Flashattion-2 com ROCM atualmente suporta:
As principais funções implementam a atenção do produto em escala (q @ k^t * softmax_scale) @ v):
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""Para ver como essas funções são usadas em uma camada de atenção de várias cabeças (que inclui projeção QKV, projeção de saída), consulte a implementação do MHA.
Atualização do Flashattion (1.x) para Flashattion-2
Essas funções foram renomeadas:
flash_attn_unpadded_func -> flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func -> flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func -> flash_attn_varlen_kvpacked_funcSe as entradas tiverem os mesmos comprimentos de sequência no mesmo lote, é mais simples e rápido usar essas funções:
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )Se seqlen_q! = Seqlen_k e causal = true, a máscara causal está alinhada ao canto inferior direito da matriz de atenção, em vez do canto superior esquerdo.
Por exemplo, se seqlen_q = 2 e seqlen_k = 5, a máscara causal (1 = mantenha, 0 = mascarada) é:
v2.0:
1 0 0 0
1 1 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
Se seqlen_q = 5 e seqlen_k = 2, a máscara causal é:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
Se a linha da máscara for zero, a saída será zero.
Otimize para inferência (decodificação iterativa) quando a consulta tem um comprimento de sequência muito pequeno (por exemplo, comprimento da sequência de consulta = 1). O gargalo aqui é carregar o cache KV o mais rápido possível e dividimos o carregamento em diferentes blocos de rosca, com um kernel separado para combinar resultados.
Consulte a função flash_attn_with_kvcache com mais recursos para inferência (execute a incorporação rotativa, atualizando o cache KV no local).
Graças à equipe do Xformers, e em particular Daniel Haziza, por essa colaboração.
Implemente a atenção da janela deslizante (ou seja, atenção local). Graças à IA Mistral e, em particular, Timothée Lacroix por essa contribuição. A janela deslizante foi usada no modelo Mistral 7B.
Implementar Alibi (Press et al., 2021). Agradecemos a Sanghun Cho, do Kakao Brain, por essa contribuição.
Implementar o passe determinístico para trás. Obrigado aos engenheiros de Meituan por essa contribuição.
Apoie o cache do KV paginado (ou seja, Pagedattion). Obrigado a @Beginlner por esta contribuição.
Apoie a atenção com o soft-capping, conforme usado nos modelos Gemma-2 e Grok. Obrigado a @narsil e @lucidrains por esta contribuição.
Obrigado a @ANI300 por esta contribuição.
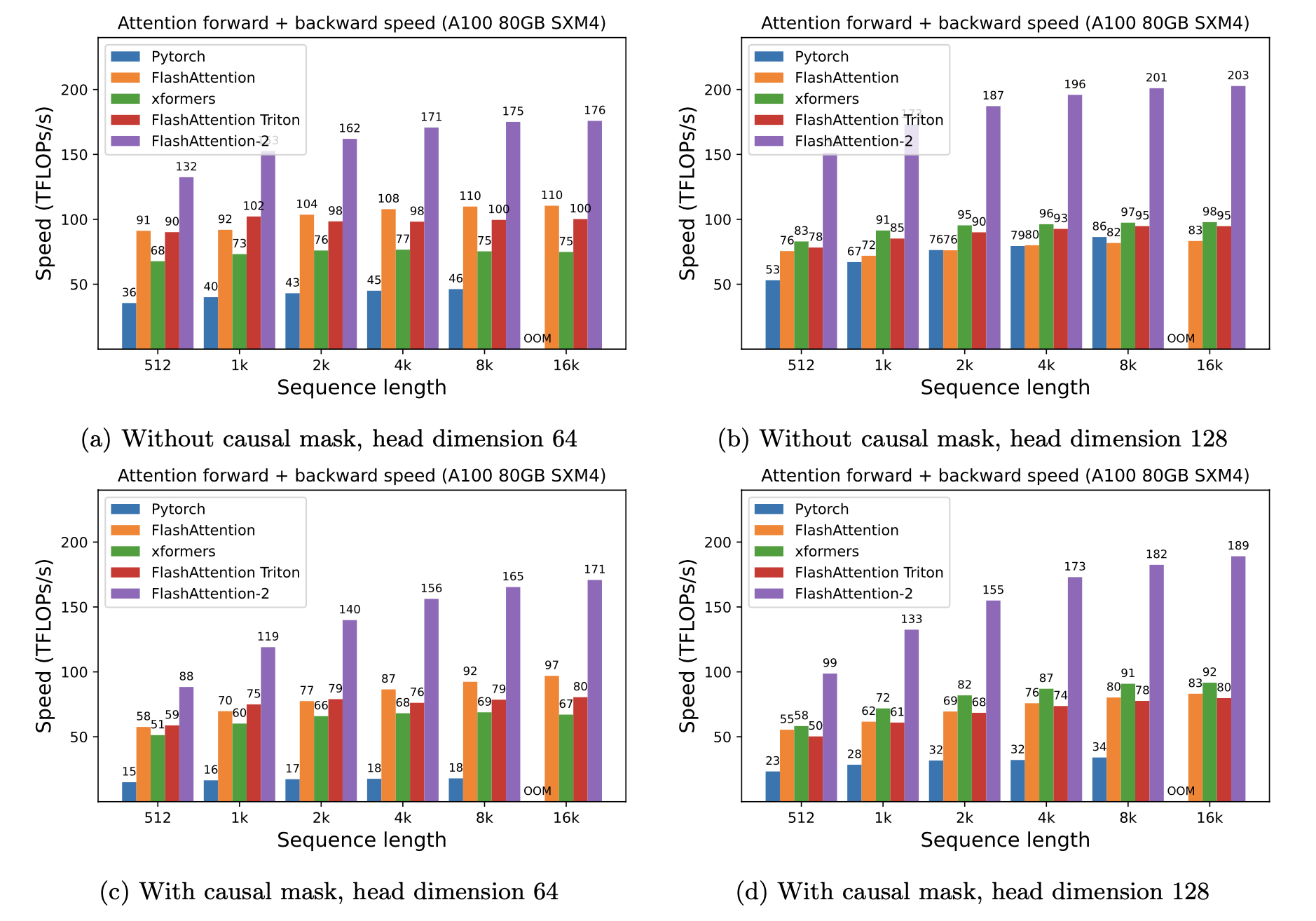
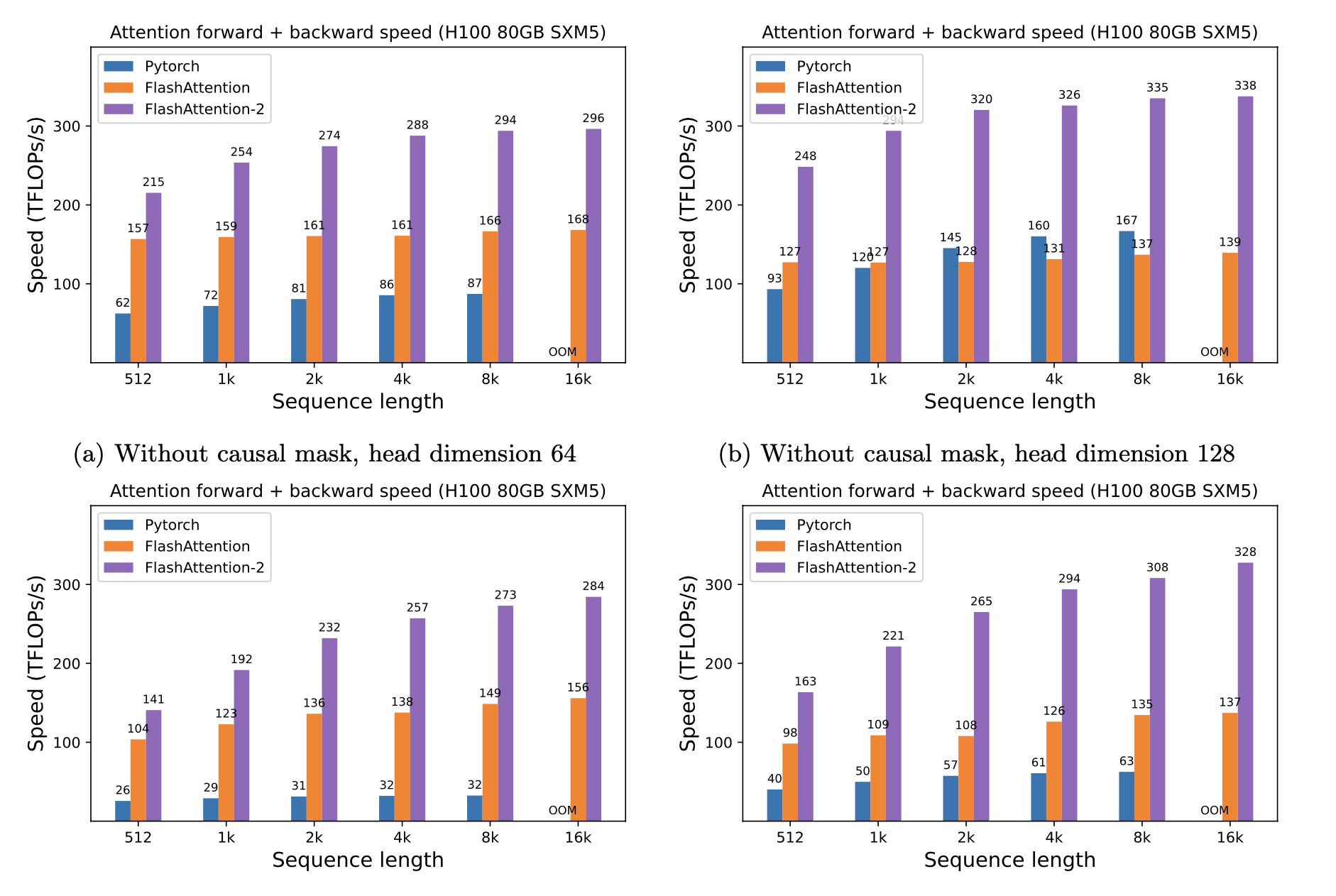
Apresentamos a aceleração esperada (PASSA COMBINENTE ADMINENTE + PASSE para trás) e a economia de memória de usar o Flashattion contra a atenção padrão do Pytorch, dependendo do comprimento da sequência, em diferentes GPUs (a aceleração depende da largura de banda da memória - vemos mais aceleração na memória GPU mais lenta).
Atualmente, temos benchmarks para essas GPUs:
Exibimos o Flashattion Speedup usando estes parâmetros:
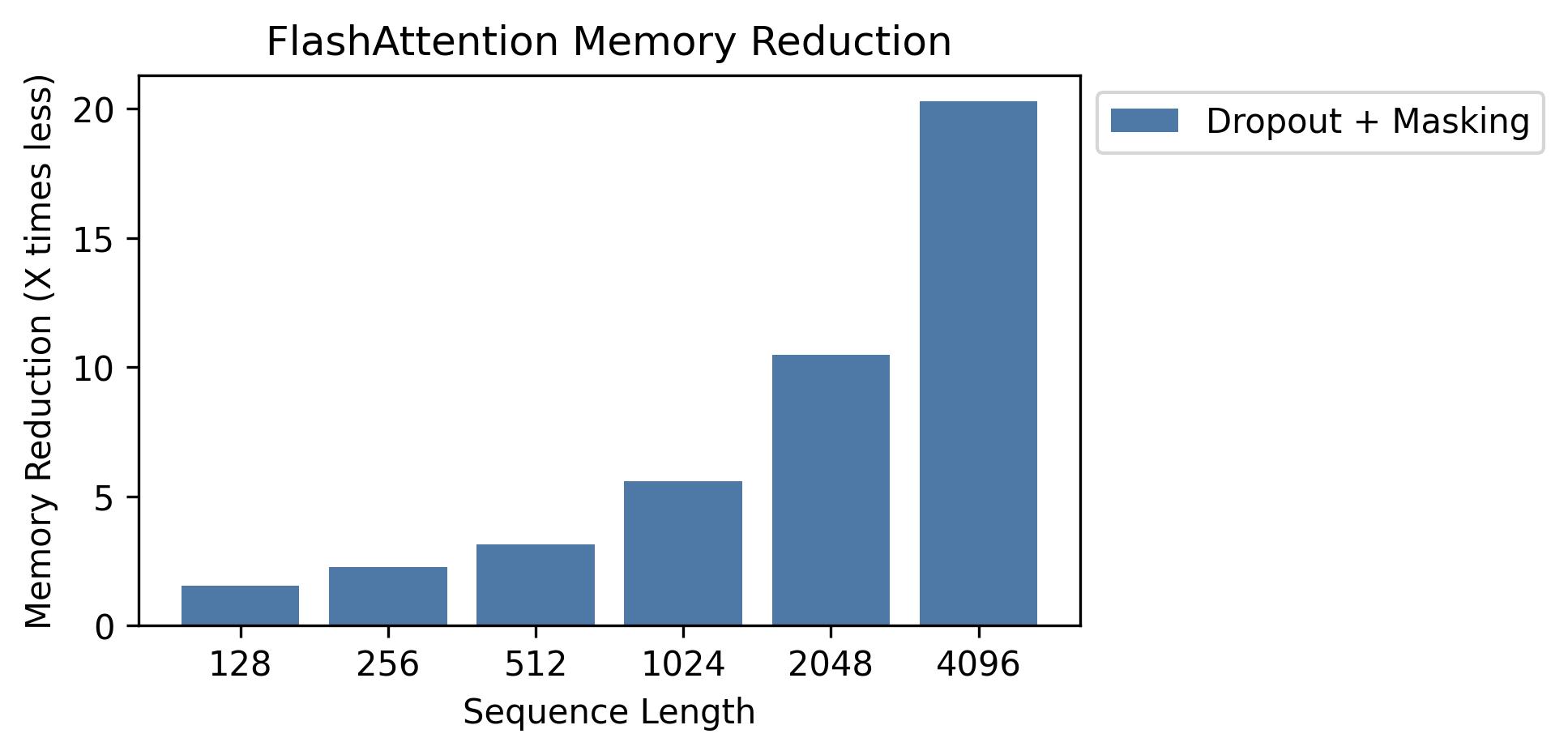
Mostramos economia de memória neste gráfico (observe que a pegada de memória é a mesma, não importa se você usa o abandono ou mascaramento). A economia de memória é proporcional ao comprimento da sequência - uma vez que a atenção padrão tem a memória quadrática no comprimento da sequência, enquanto o Flashattion possui memória linear no comprimento da sequência. Vemos 10x de economia de memória no comprimento da sequência 2k e 20x em 4k. Como resultado, o Flashattion pode escalar para comprimentos de sequência muito mais longos.
Lançamos a implementação completa do modelo GPT. Também fornecemos implementações otimizadas de outras camadas (por exemplo, MLP, camada de camada, perda de entropia cruzada, incorporação rotativa). No geral, isso acelera o treinamento em 3-5x em comparação com a implementação da linha de base do HuggingFace, atingindo até 225 Tflops/s de acordo com A100, equivalente a 72% de utilização do modelo (não precisamos de verificação de ativação).
Também incluímos um script de treinamento para treinar GPT2 no OpenWebtext e GPT3 na pilha.
Phil Tillet (Openai) tem uma implementação experimental da Flashattion in Triton: https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
Como o Triton é uma linguagem de nível superior que o CUDA, pode ser mais fácil entender e experimentar. As anotações na implementação do Triton também estão mais próximas do que é usado em nosso artigo.
Também temos uma implementação experimental em Triton que apóia o viés de atenção (por exemplo, álibi): https://github.com/dao-ailab/flash-attntion/blob/main/flash_attn/flash_attn_triton.py
Testamos que a Flashattion produz a mesma saída e gradiente que uma implementação de referência, até alguma tolerância numérica. Em particular, verificamos se o erro numérico máximo da Flashattion é no máximo o dobro do erro numérico de uma implementação de linha de base em Pytorch (para diferentes dimensões da cabeça, DTYPE de entrada, comprimento da sequência, causal / não causal).
Para executar os testes:
pytest -q -s tests/test_flash_attn.pyEste novo lançamento do Flashattion-2 foi testado em vários modelos de estilo GPT, principalmente em GPUs A100.
Se você encontrar bugs, abra um problema do Github!
Para executar os testes:
pytest tests/test_flash_attn_ck.pySe você usa esta base de código ou achou nosso trabalho valioso, cite:
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


