vision_transformer
1.0.0
Neste repositório, lançamos modelos dos papéis
Os modelos foram pré-treinados nos conjuntos de dados ImageNet e ImageNet-21K. Fornecemos o código para ajustar os modelos lançados em Jax/linho.
Os modelos desta base de código foram originalmente treinados em https://github.com/google-research/big_vision/ onde você pode encontrar um código mais avançado (por exemplo, treinamento multi-host), bem como alguns dos scripts de treinamento originais (por exemplo, configs /vit_i21k.py para pré-treinamento de um VIT, ou configs/transfer.py para transferir um modelo).
Índice:
Abaixo, os colabs são executados com as GPUs e TPUs (8 núcleos, paralelismo de dados).
O primeiro colab demonstra o código Jax de Transformers e MLP Mixers. Este colab permite editar os arquivos do repositório diretamente na interface do usuário do COLAB e anotou as células colab que o orientam no código passo a passo e permite interagir com os dados.
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax.ipynb
O segundo colab permite que você explore o transformador de visão> 50k e os pontos de verificação híbridos que foram usados para gerar os dados do terceiro artigo "Como treinar seu vit? ...". O COLAB inclui código para explorar e selecionar pontos de verificação e fazer inferência usando o código JAX deste repositório e também usando a popular biblioteca timm Pytorch que também pode carregar esses pontos de verificação. Observe que um punhado de modelos também está disponível diretamente no TF-HUB: Sayakpaul/Coleções/Vision_transformer (contribuição externa de Sayak Paul).
O segundo colab também permite ajustar os pontos de verificação em qualquer conjunto de dados TFDS e seu próprio conjunto de dados com exemplos em arquivos JPEG individuais (opcionalmente lendo diretamente do Google Drive).
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax_augreg.ipynb
Nota : Por enquanto (20/6/21), o Google Colab suporta apenas uma única GPU (Nvidia Tesla T4), e o TPUS (atualmente o TPUV2-8) está ligado indiretamente à vm Colab e se comunica com uma rede lenta, o que leva a bonito Velocidade de treinamento ruim. Você geralmente deseja configurar uma máquina dedicada se tiver uma quantidade não trivial de dados para ajustar. Para detalhes, consulte a seção de corrida na nuvem.
Verifique se você tem Python>=3.10 instalado em sua máquina.
Instale as dependências JAX e Python em execução:
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
Para versões mais recentes do JAX, siga as instruções fornecidas no repositório correspondente vinculado aqui. Observe que as instruções de instalação para CPU, GPU e TPU difere um pouco.
Instale o Flaxformer, siga as instruções fornecidas no repositório correspondente vinculado aqui.
Para mais detalhes, consulte a seção em execução na nuvem abaixo.
Você pode executar o ajuste fino do modelo baixado no seu conjunto de dados de interesse. Todos os modelos compartilham a mesma interface da linha de comando.
Por exemplo, para ajustar um Vit-B/16 (pré-treinado no ImageNet21K) no CIFAR10 (observe como especificamos b16,cifar10 como argumentos à configuração e como instruímos o código para acessar os modelos diretamente de um balde GCS em vez de primeiro baixá -los no diretório local):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'Para ajustar um mixer-b/16 (pré-treinado no imagenet21k) no CIFAR10:
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' O papel "Como treinar seu vit? ..." adicionou> 50k pontos de verificação que você pode ajustar com a configuração configs/augreg.py . Quando você especifica apenas o nome do modelo (o valor config.name de configs/model.py ), o melhor ponto de verificação i21k por precisão de validação upstream ("recomendado" ponto de verificação, consulte a seção 4.5 do papel) é escolhido. Para decidir qual modelo você deseja usar, dê uma olhada na Figura 3 no papel. Também é possível escolher um ponto de verificação diferente (consulte Colab vit_jax_augreg.ipynb ) e, em seguida, especifique o valor da coluna filename ou adapt_filename , que corresponde aos nomes de arquivos sem .npz do diretório gs://vit_models/augreg .
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01 Atualmente, o código baixará automaticamente os conjuntos de dados CIFAR-10 e CIFAR-100. Outros conjuntos de dados públicos ou personalizados podem ser facilmente integrados, usando a biblioteca de dados do TensorFlow. Observe que você também precisará atualizar vit_jax/input_pipeline.py para especificar alguns parâmetros sobre qualquer conjunto de dados adicionado.
Observe que nosso código usa todas as GPUs/TPUs disponíveis para ajuste fino.
Para ver uma lista detalhada de todos os sinalizadores disponíveis, execute python3 -m vit_jax.train --help .
Notas sobre memória:
--config.accum_steps=8 -alternativamente, você também poderá diminuir o --config.batch=512 (e diminuir --config.base_lr de acordo).--config.shuffle_buffer=50000 . Por Alexey Dosovitskiy*†, Lucas Beyer*, Alexander Kolesnikov*, Dirk Weissenborn*, Xiaohua Zhai*, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigl, Sylain Gelly, Jakob, Hercera e Neil, Jakob, Her.
(*) Contribuição técnica igual, (†) Aconselhamento igual.
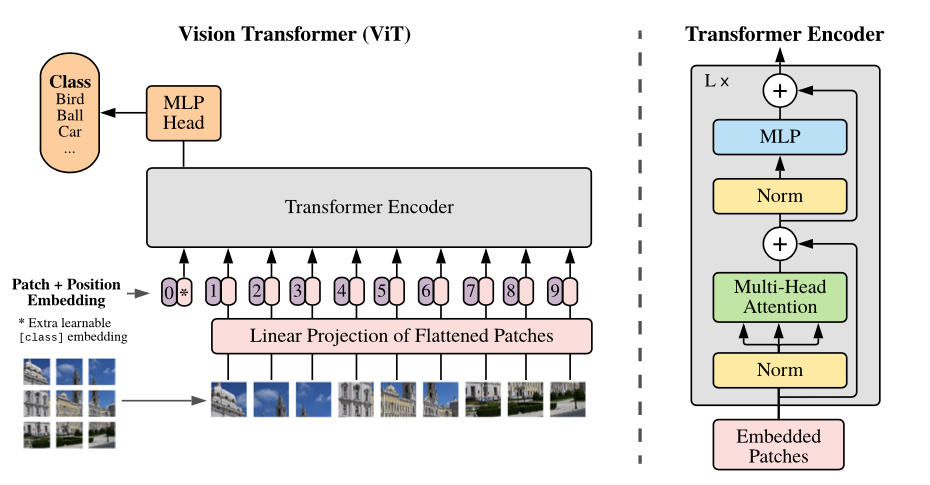
Visão geral do modelo: dividimos uma imagem em patches de tamanho fixo, incorporamos linearmente cada um deles, adicionamos incorporações de posição e alimentamos a sequência resultante de vetores a um codificador de transformador padrão. Para executar a classificação, usamos a abordagem padrão de adicionar um "token de classificação" extra aprendizado à sequência.
Fornecemos uma variedade de modelos VIT em diferentes baldes GCS. Os modelos podem ser baixados com por exemplo:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
Os nomes de arquivos do modelo (sem a extensão .npz ) correspondem ao config.model_name in vit_jax/configs/models.py
gs://vit_models/imagenet21k -modelos pré-treinados no imagenet-21k.gs://vit_models/imagenet21k+imagenet2012 -modelos pré-treinados no imagenet-21k e ajustados no imagenet.gs://vit_models/augreg -Modelos pré-treinados no ImageNet-21K, aplicando quantidades variadas de Augreg. Desempenho aprimorado.gs://vit_models/sam - modelos pré -treinados no imagenet com sam.gs://vit_models/gsam - modelos pré -treinados no imagenet com gsam.Recomendamos o uso dos seguintes pontos de verificação, treinados com o Augreg que possuem as melhores métricas de pré-treinamento:
| Modelo | Ponto de verificação pré-treinado | Tamanho | Ponto de verificação ajustado | Resolução | Img/s | Precisão do imagenet |
|---|---|---|---|---|---|---|
| L/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 MIB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85,59% |
| B/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 MIB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85,49% |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 MIB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83,73% |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 MIB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85,99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 MIB | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83,85% |
| Ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 MIB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78,22% |
| B/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 MIB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83,59% |
| S/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 MIB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79,58% |
| R+ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 MIB | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75,40% |
Os resultados do papel Vit original (https://arxiv.org/abs/2010.11929) foram replicados usando os modelos de gs://vit_models/imagenet21k :
| modelo | conjunto de dados | abandono = 0,0 | abandono = 0,1 |
|---|---|---|---|
| R50+VIT-B_16 | Cifar10 | 98,72%, 3,9h (A100), TB.DEV | 98,94%, 10,1h (V100), TB.DEV |
| R50+VIT-B_16 | Cifar100 | 90,88%, 4,1h (A100), TB.DEV | 92,30%, 10,1h (V100), TB.DEV |
| R50+VIT-B_16 | ImageNet2012 | 83,72%, 9,9h (A100), TB.DEV | 85,08%, 24,2h (V100), TB.DEV |
| Vit-B_16 | Cifar10 | 99,02%, 2,2h (A100), TB.DEV | 98,76%, 7,8h (V100), TB.DEV |
| Vit-B_16 | Cifar100 | 92,06%, 2,2h (A100), TB.DEV | 91,92%, 7,8h (V100), TB.DEV |
| Vit-B_16 | ImageNet2012 | 84,53%, 6,5h (A100), TB.DEV | 84,12%, 19,3H (v100), TB.Dev |
| Vit-B_32 | Cifar10 | 98,88%, 0,8h (A100), TB.DEV | 98,75%, 1,8H (v100), TB.Dev |
| Vit-B_32 | Cifar100 | 92,31%, 0,8h (A100), TB.DEV | 92,05%, 1,8h (V100), TB.DEV |
| Vit-B_32 | ImageNet2012 | 81,66%, 3,3h (A100), TB.DEV | 81,31%, 4,9h (V100), TB.DEV |
| Vit-L_16 | Cifar10 | 99,13%, 6,9h (A100), TB.DEV | 99,14%, 24,7h (V100), TB.DEV |
| Vit-L_16 | Cifar100 | 92,91%, 7,1h (A100), TB.DEV | 93,22%, 24,4h (V100), TB.DEV |
| Vit-L_16 | ImageNet2012 | 84,47%, 16,8h (A100), TB.DEV | 85,05%, 59,7h (V100), TB.DEV |
| Vit-L_32 | Cifar10 | 99,06%, 1,9H (A100), TB.DEV | 99,09%, 6,1h (V100), TB.DEV |
| Vit-L_32 | Cifar100 | 93,29%, 1,9H (A100), TB.DEV | 93,34%, 6,2h (V100), TB.DEV |
| Vit-L_32 | ImageNet2012 | 81,89%, 7,5h (A100), TB.DEV | 81,13%, 15,0H (V100), TB.DEV |
Também gostaríamos de enfatizar que resultados de alta qualidade podem ser alcançados com cronogramas de treinamento mais curtos e incentivar os usuários de nosso código a jogar com hiper-parâmetros para trocar precisão e orçamento computacional. Alguns exemplos para conjuntos de dados CIFAR-10/100 são apresentados na tabela abaixo.
| a montante | modelo | conjunto de dados | Total_Steps / Warmup_Steps | precisão | Tempo de parede | link |
|---|---|---|---|---|---|---|
| imagenet21k | Vit-B_16 | Cifar10 | 500 /50 | 98,59% | 17m | tensorboard.dev |
| imagenet21k | Vit-B_16 | Cifar10 | 1000 /100 | 98,86% | 39m | tensorboard.dev |
| imagenet21k | Vit-B_16 | Cifar100 | 500 /50 | 89,17% | 17m | tensorboard.dev |
| imagenet21k | Vit-B_16 | Cifar100 | 1000 /100 | 91,15% | 39m | tensorboard.dev |
Por Ilya Tolstikhin*, Neil Houlsby*, Alexander Kolesnikov*, Lucas Beyer*, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy.
(*) Igual contribuição.
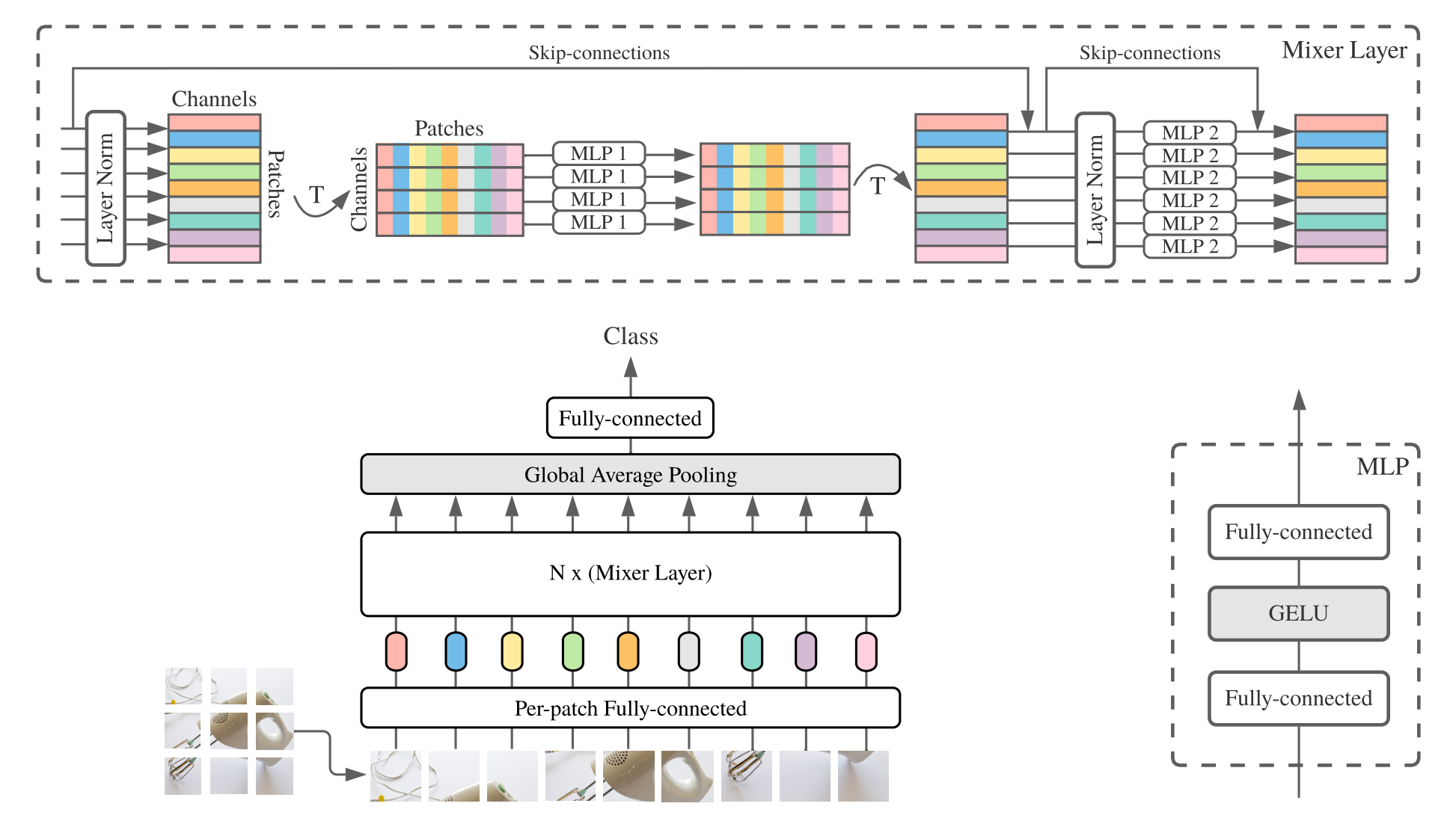
O MLP-Mixer ( Mixer para curta) consiste em incorporações lineares por patch, camadas do misturador e uma cabeça de classificador. As camadas do misturador contêm um MLP de mistura de token e um MLP de mistura de canal, cada um consistindo em duas camadas totalmente conectadas e uma não linearidade de Gelu. Outros componentes incluem: conexões de pular, abandono e cabeça de classificador linear.
Para instalação, siga as mesmas etapas acima.
Fornecemos os modelos Mixer-B/16 e Mixer-L/16 pré-treinados nos conjuntos de dados ImageNet e ImageNet-21K. Os detalhes podem ser encontrados na Tabela 3 do papel do misturador. Todos os modelos podem ser encontrados em:
https://console.cloud.google.com/storage/mixer_models/
Observe que esses modelos também estão disponíveis diretamente no TF-HUB: Sayakpaul/Coleções/MLP-Mixer (contribuição externa de Sayak Paul).
Executamos o código de ajuste fino no Google Cloud Machine com quatro GPUs V100 com os parâmetros de adaptação padrão deste repositório. Aqui estão os resultados:
| a montante | modelo | conjunto de dados | precisão | Wall_clock_time | link |
|---|---|---|---|---|---|
| Imagenet | Mixer-B/16 | Cifar10 | 96,72% | 3.0h | tensorboard.dev |
| Imagenet | Mixer-l/16 | Cifar10 | 96,59% | 3.0h | tensorboard.dev |
| ImageNet-21K | Mixer-B/16 | Cifar10 | 96,82% | 9.6h | tensorboard.dev |
| ImageNet-21K | Mixer-l/16 | Cifar10 | 98,34% | 10.0h | tensorboard.dev |
Para obter detalhes, consulte o post do Google AI Blog Lit: Adicionando entendimento de linguagem aos modelos de imagem ou leia o artigo CVPR "Lit: Transferência de Zero-Shot com ajuste de texto de imagem bloqueada" (https://arxiv.org/abs/2111.07991 ).
Publicamos um modelo Transformer B/16-BASE com uma precisão do ImageNet Zeroshot de 72,1%e um modelo de L/16 largo com uma precisão de Zeroshot de Imagenet de 75,7%. Para mais detalhes sobre esses modelos, consulte o cartão de modelo LIT.
Fornecemos uma demonstração no navegador com pequenos codificadores de texto para uso interativo (os menores modelos devem até funcionar em um telefone celular moderno):
https://google-research.github.io/vision_transformer/lit/
E, finalmente, um colab para usar os modelos JAX com codificadores de imagem e texto:
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
Observe que nenhum dos modelos acima suporta entradas multilíngues ainda, mas estamos trabalhando na publicação desses modelos e atualizará esse repositório assim que estiverem disponíveis.
Este repositório contém apenas o código de avaliação para modelos LIT. Você pode encontrar o código de treinamento no repositório big_vision :
https://github.com/google--research/big_vision/tree/main/big_vision/configs/proj/image_text
O Zeroshot esperado resulta de model_cards/lit.md (observe que a avaliação de Zeroshot é ligeiramente diferente da avaliação simplificada no COLAB):
| Modelo | B16B_2 | L16L |
|---|---|---|
| ImageNet Zero-shot | 73,9% | 75,7% |
| ImageNet V2 Zero-Shot | 65,1% | 66,6% |
| Cifar100 Zero-Shot | 79,0% | 80,5% |
| Pets37 Zero-Shot | 83,3% | 83,3% |
| Resisc45 Zero-Shot | 25,3% | 25,6% |
| Recuperação de imagem para texto MS-COCO | 51,6% | 48,5% |
| Recuperação de texto para imagem MS-COCO | 31,8% | 31,1% |
Embora os colabs acima sejam bastante úteis para começar, você geralmente gostaria de treinar em uma máquina maior com aceleradores mais poderosos.
Você pode usar os seguintes comandos para configurar uma VM com GPUs no Google Cloud:
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAMEComo alternativa, você pode usar os seguintes comandos semelhantes para configurar uma VM em nuvem com TPUs anexadas a eles (abaixo dos comandos copiados do tutorial da TPU):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME E, em seguida, busque o repositório e as dependências de instalação (incluindo jaxlib com suporte à TPU) como de costume:
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateSe você estiver conectado a uma VM com as GPUs anexadas, instale o JAX e outras dependências com o seguinte comando:
pip install -r vit_jax/requirements.txtSe você estiver conectado a uma VM com TPUs anexado, instale o JAX e outras dependências com o seguinte comando:
pip install -r vit_jax/requirements-tpu.txtInstale o Flaxformer, siga as instruções fornecidas no repositório correspondente vinculado aqui.
Para GPUs e TPUs, verifique se o JAX pode se conectar aos aceleradores anexados com o comando:
python -c ' import jax; print(jax.devices()) 'E finalmente execute um dos comandos mencionados na seção ajustando um modelo.
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
Em ordem cronológica reversa:
2022-08-18: Modelo Lit-B16B_2 adicionado que foi treinado para 60k etapas (lit_b16b: 30k) sem cabeça linear no lado da imagem (lit_b16b: 768) e tem melhor desempenho.
2022-06-09: Adicionado os modelos VIT e Mixer treinados do zero usando GSAM no ImageNet sem fortes aumentos de dados. Os Vits resultantes superam os de tamanhos semelhantes treinados usando o Otimizador ADAMW ou o algoritmo SAM original, ou com fortes aumentos de dados.
2022-04-14: Modelos adicionados e colab para modelos LIT.
2021-07-29: Adicionado modelos Vit-B/8 AuGreg (3 pontos de verificação a montante e adaptações com resolução = 224).
2021-07-02: Adicionado o papel "Quando a visão transformadores superam as resnetas ..."
2021-07-02: Adicionado SAM (minimização com reconhecimento de nitidez) Ponto de verificação VIT e MLP-Mixer.
2021-06-20: Adicionado o papel "Como treinar seu vit? ..." e um novo colab para explorar os postos de verificação pré-treinados e de ajuste fino e 50k mencionados no artigo.
2021-06-18: Este repositório foi reescrito para usar a API de linho de linho e ml_collections.ConfigDict para configuração.
2021-05-19: Com a publicação do artigo "Como treinar seu vit? ...", adicionamos mais de 50k Modelos Vit e Híbridos pré-treinados no ImageNet e ImageNet-21K com vários graus de aumento de dados e regularização do modelo , e ajustado fino no Imagenet, Pets37, Kitti-Distance, Cifar-100 e Resisc45. Confira vit_jax_augreg.ipynb para navegar neste tesouro de modelos! Por exemplo, você pode usar esse colab para buscar os nomes de arquivos dos pontos de verificação pré-treinados e ajustados recomendados da coluna i21k_300 da Tabela 3 no papel.
2020-12-01: Adicionado o modelo híbrido R50+Vit-B/16 (Vit-B/16 na parte superior de um backbone Resnet-50). Quando pré -criado no ImageNet21K, esse modelo alcança quase o desempenho do modelo L/16 com menos da metade do custo computacional de fino. Observe que "R50" é um pouco modificado para a variante B/16: o ResNet-50 original possui [3,4,6,3] blocos, cada um reduzindo a resolução da imagem por um fator de dois. Em combinação com a haste Resnet, isso resultaria em uma redução de 32x, portanto, mesmo com um tamanho de patch (1,1), a variante Vit-B/16 não pode mais ser realizada. Por esse motivo, usamos blocos [3,4,9] para a variante R50+B/16.
2020-11-09: Adicionado o modelo Vit-L/16.
2020-10-29: Modelos adicionados Vit-B/16 e Vit-L/16 pré-terem pretido no ImageNet-21K e depois ajustados no ImageNet na resolução de 224x224 (em vez do padrão 384x384). Esses modelos têm o sufixo "-224" em seu nome. Espera-se que eles atinjam 81,2% e 82,7% de precisão Top-1, respectivamente.
Liberação de código aberto preparado por Andreas Steiner.
Nota: Este repositório foi bifurcado e modificado no Google-Research/big_transfer.
Este não é um produto oficial do Google.


