Face Shape Classification using CNN
1.0.0

Este é um projeto de classificação de imagem para identificar 5 formas de rosto femininas usando redes neurais convolucionais (CNN) . Concluí isso como meu projeto Capstone para Curso Imersivo de Ciência de Dados com a Assembléia Geral (outubro de 2020).
Este projeto também é implantado como um aplicativo da Web usando o Stremlit no Heroku. Se você estiver interessado, verifique o formato do seu rosto em myfaceshape.herokuapp.com
Com base na revisão do consumidor da Deloitte, os consumidores estão exigindo uma experiência mais personalizada, no entanto, o julgamento permanece baixo. Na indústria de beleza e moda, mais de 40%dos adultos de 16 a 39 anos estão interessados em oferta personalizada, enquanto o julgamento é de apenas 10%a 14%. Entre os interessados, ~ 80% estão dispostos a pagar pelo menos 10% de preço mais alto.
Por poder classificar as formas de rosto, permitirá que as marcas ofereçam soluções mais personalizadas para aumentar a satisfação do cliente, enquanto aumentam a margem do posicionamento premium. Exemplo de casos de uso são:
Para este projeto, usarei a abordagem de aprendizado profundo com redes neurais convolucionais (CNN) para classificar 5 diferentes formas femininas (coração, oblongo, oval, redondo, quadrado). O modelo que foi a maior pontuação de precisão será escolhido.
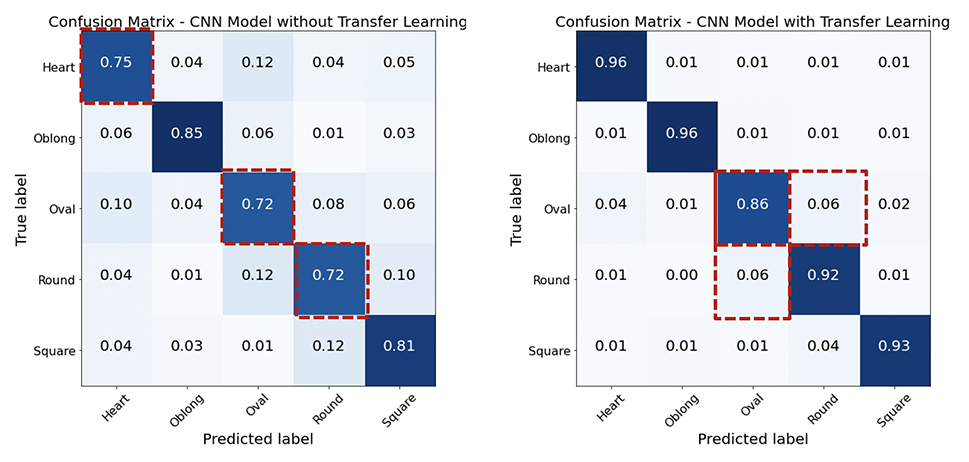
Eu explorei 2 abordagens da CNN, construindo do zero vs. aprendizado de trasfer com arquitetura VGG-16 e pesos pré-treinados da VGGFFace. A abordagem de aprendizado de transferência ajudou a aumentar a precisão, enquanto a forma mais mal classificada é "oval".
O pré-processamento da imagem também desempenhou um papel importante na redução de excesso de ajuste e no aumento da precisão da validação. Os principais motoristas são:
O conjunto de dados da forma do rosto é um conjunto de dados da Kaggle da Niten Lama.
Este conjunto de dados compreende um total de 5000 imagens das celebridades de todo o mundo que são categorizadas de acordo com sua forma de rosto, a saber:
Cada categoria consiste em 1000 imagens (800 para treinamento: 200 para teste)
O pré-processamento das imagens é um fator crítico na redução do modelo excessivo para o conjunto de dados de treinamento e aumentando a precisão da validação. As etapas a seguir foram exploradas:
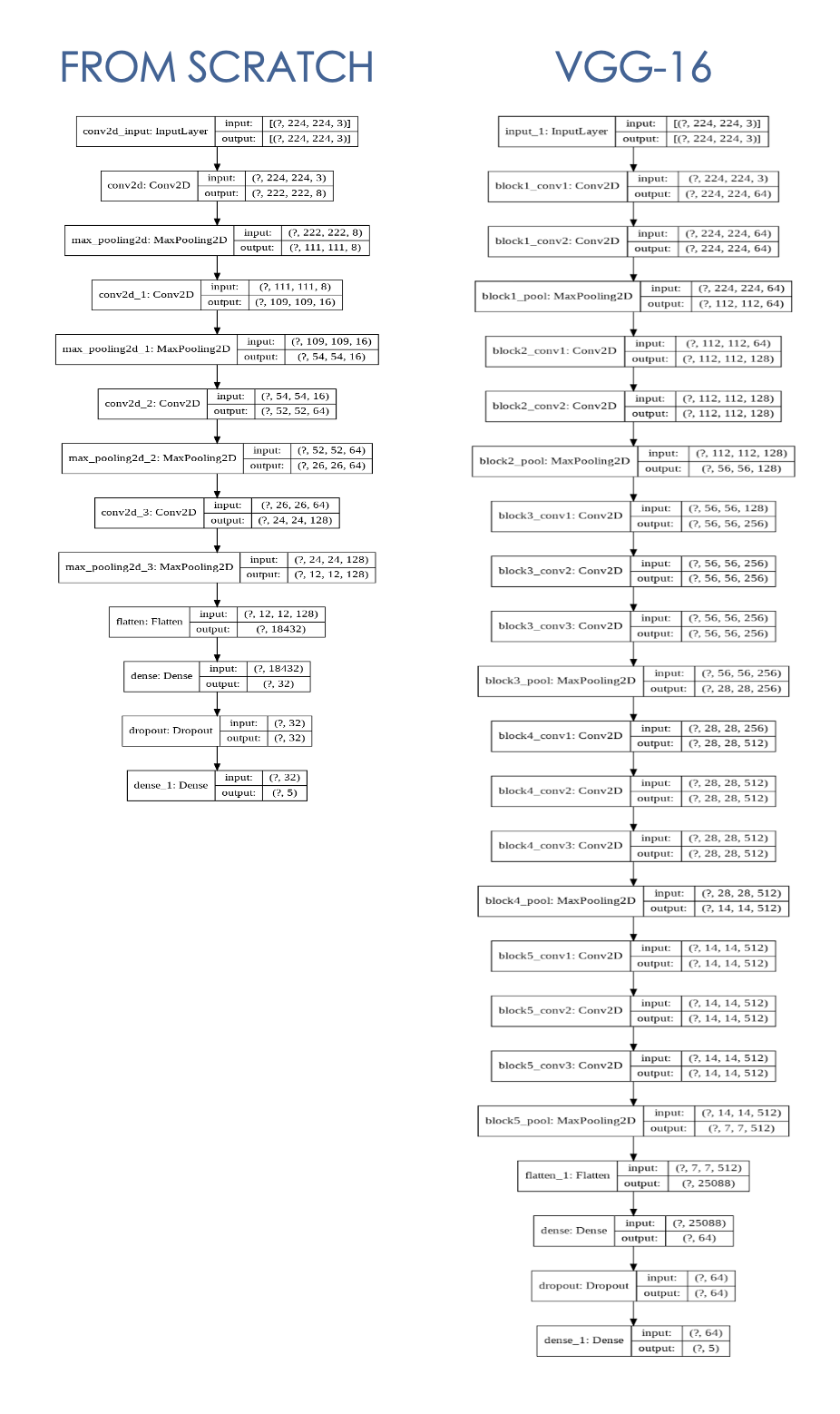
Modelo da CNN construído a partir do zero com dados de treinamento limitado de 4000 imagens (800 imagens x 5 classes), construo o modelo com 4 camadas convolucionais + max-pooling e 2 camadas densas (detalhes abaixo).
O modelo CNN com aprendizado de transferência me permite usar uma arquitetura VGG-16 mais complexa, usando pesos pré-treinados da VGGFFace que foram treinados em mais de 2,6 milhões de imagens.
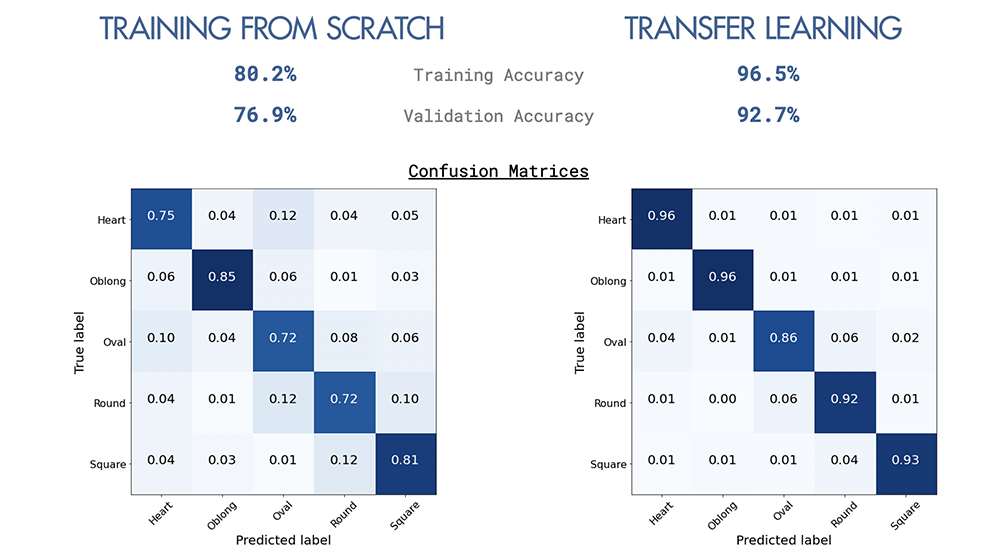
O aprendizado de transferência ajudou a melhorar significativamente a precisão, de 76,9% a 92,7%, com a ajuda de pesos pré-treinados em conjuntos de dados maiores.
A partir dos modelos construídos do zero, todos os modelos tiveram um desempenho melhor que a linha de base de 20% (5 classes são equilibradas com 20% cada).
Resumo de todos os modelos abaixo.

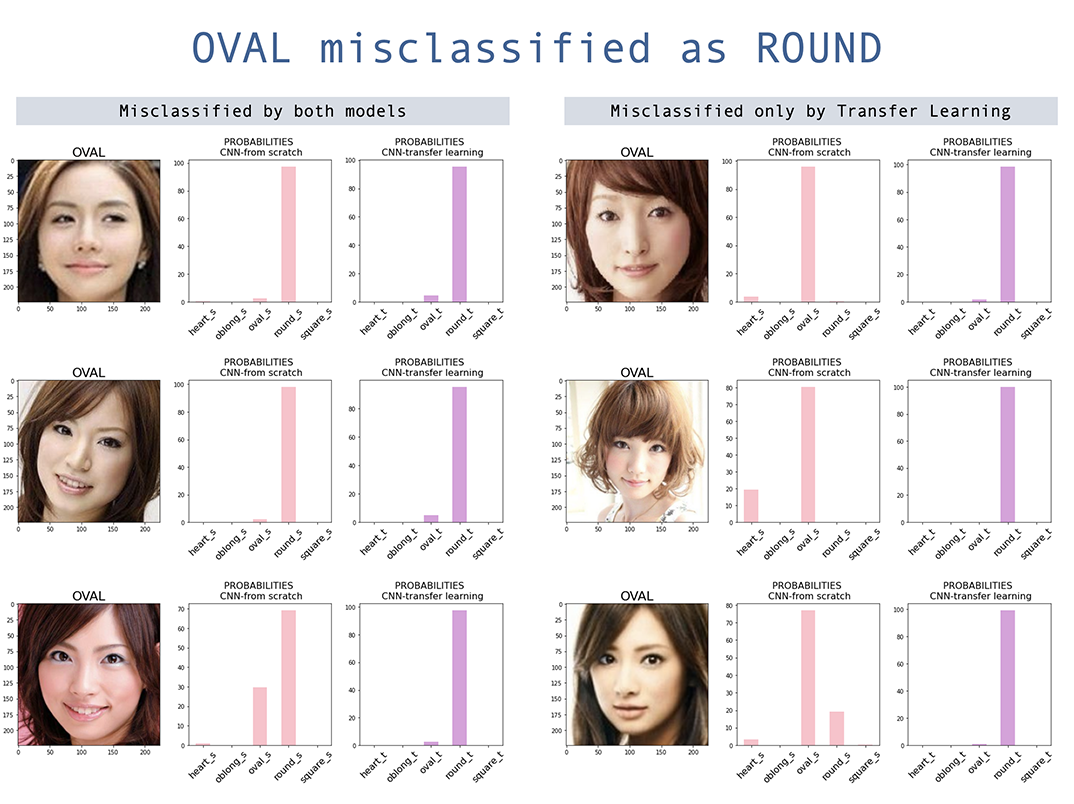
Ambos os modelos têm maior classificação incorreta no formato oval do rosto. Embora o modelo de aprendizado de transferência tenha melhorado a precisão do modelo construído a partir do zero, o Oval ainda é o mais classificado, com a maioria sendo oval classificada como redonda. É interessante A confusão entre oval e rodada são principalmente rostos asiáticos, e mais ainda com o aprendizado de transferência. É provável que os pesos pré -tenhados tenham menos imagens asiáticas.