Awesome LLM 3D
1.0.0
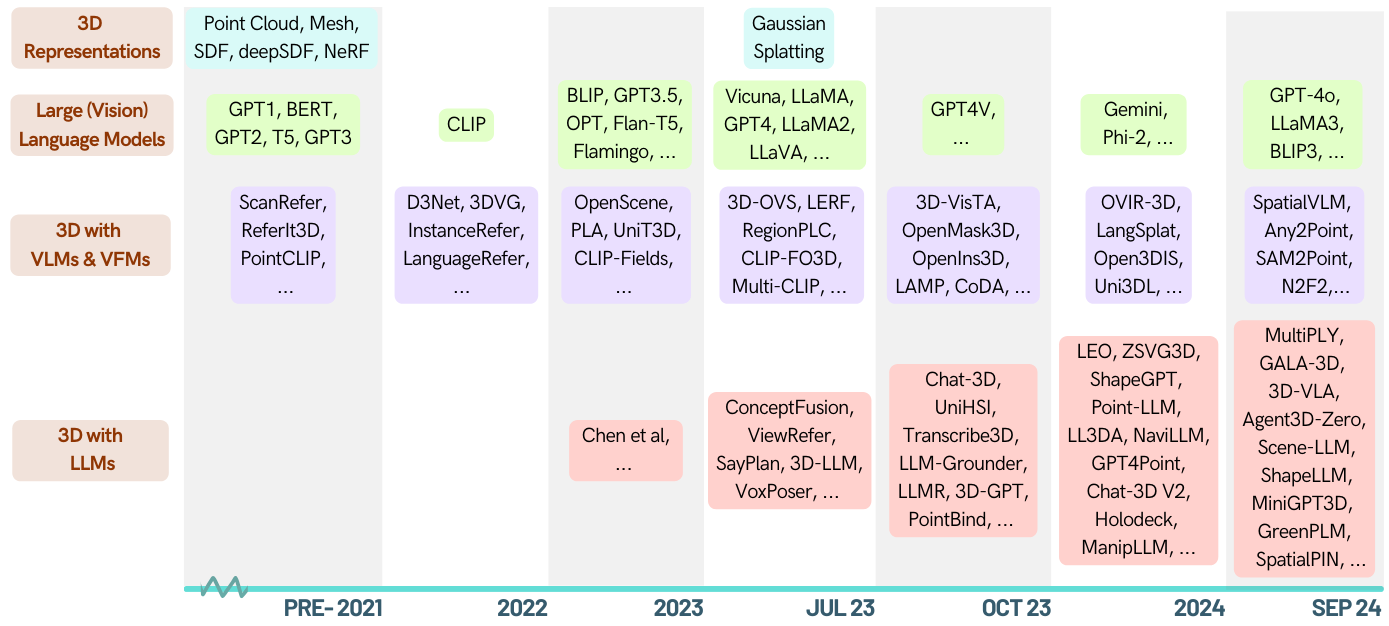
Aqui está uma lista com curadoria de artigos sobre tarefas relacionadas a 3D capacitadas por grandes modelos de idiomas (LLMS). Ele contém várias tarefas, incluindo entendimento 3D, raciocínio, geração e agentes incorporados. Além disso, incluímos outros modelos de fundação (CLIP, SAM) para toda a imagem desta área.
Este é um repositório ativo, você pode observar os últimos avanços. Se você achar útil, por favor, por favor, estrela este repo e cite o papel.
[2024-05-16]? Confira o primeiro documento de pesquisa no domínio 3D-LLM: quando o LLMS entrar no mundo 3D: uma pesquisa e meta-análise de tarefas 3D através de modelos de linguagem grande multimodal
[2024-01-06] Runsen Xu adicionou informações cronológicas e Xianzheng MA a reorganizou em ZA Ordem para melhor após os últimos avanços.
[2023-12-16] Xianzheng MA e Yash Bhalgat selecionaram esta lista e publicaram a primeira versão;
Awesome-llm-3d
Entendimento 3D (LLM)
Entendimento 3D (outros modelos de fundação)
Raciocínio 3D
3d geração
Agente incorporado 3D
Benchmarks 3D
Contribuindo
| Data | Palavras -chave | Instituto (primeiro) | Papel | Publicação | Outros |
|---|---|---|---|---|---|
| 2024-10-12 | Situação3d | Uiuc | A conscientização situacional é importante no raciocínio da linguagem da visão 3D | CVPR '24 | projeto |
| 2024-09-28 | Llava-3d | HKU | LLAVA-3D: Um caminho simples e eficaz para capacitar LMMs com a consciência 3D | Arxiv | projeto |
| 2024-09-08 | Msr3d | Bigai | Raciocínio multimodal situado em cenas 3D | Neurips '24 | projeto |
| 2024-08-28 | Greenplm | Hust | Mais texto, menos ponto: para o entendimento de linguagem de ponto de eficiência de dados em 3D | Arxiv | Github |
| 2024-06-17 | Llana | Unibo | Llana: grande idioma e assistente de nerf | Neurips '24 | projeto |
| 2024-06-07 | Espacialpin | Oxford | Spatialpin: aprimorando as capacidades de raciocínio espacial dos modelos de linguagem de visão por meio de Promping e interagindo Priors 3D | Neurips '24 | projeto |
| 2024-06-03 | Spatialrgpt | Ucsd | SpatialRGPT: Raciocínio espacial fundamentado em modelos de linguagem de visão | Neurips '24 | Github |
| 2024-05-02 | Minigpt-3d | Hust | Minigpt-3D: Alinhando com eficiência nuvens de ponto 3D com modelos de linguagem grandes usando PRIORES 2D | ACM MM '24 | projeto |
| 2024-02-27 | Shapellm | Xjtu | Shapellm: compreensão universal de objeto 3D para interação incorporada | Arxiv | projeto |
| 2024-01-22 | Espacialvlm | Google DeepMind | Spatialvlm: dotando modelos de linguagem da visão com recursos de raciocínio espacial | CVPR '24 | projeto |
| 2023-12-21 | LIDAR-LLM | PKU | LIDAR-LLM: Explorando o potencial de grandes modelos de linguagem para o entendimento do LIDAR 3D | Arxiv | projeto |
| 2023-12-15 | 3DAP | Shanghai Ai Lab | 3DAXIESPROMPTS: Liberando os recursos de tarefas espaciais 3D do GPT-4V | Arxiv | projeto |
| 2023-12-13 | Cena de bate-papo | Zju | Cena de bate-papo: Bridging 3D Scene e grandes modelos de idiomas com identificadores de objetos | Neurips '24 | Github |
| 2023-12-5 | GPT4Point | HKU | GPT4Point: uma estrutura unificada para a compreensão e geração de idiomas | Arxiv | Github |
| 2023-11-30 | LL3DA | Universidade de Fudan | LL3DA: Ajuste de instrução interativa visual para entendimento, raciocínio e planejamento omni-3d | Arxiv | Github |
| 2023-11-26 | ZSVG3D | CuHK (SZ) | Programação visual para aterramento visual 3D de vocabulário aberto de tiro zero | Arxiv | projeto |
| 2023-11-18 | Leo | Bigai | Um agente generalista incorporado no mundo 3D | Arxiv | Github |
| 2023-10-14 | JM3D-LLM | Universidade Xiamen | JM3D & JM3D-LLM: Elevando a representação 3D com pistas multimodais juntas | ACM MM '23 | Github |
| 2023-10-10 | Uni3d | Baai | Uni3d: Explorando a representação 3D unificada em escala | ICLR '24 | projeto |
| 2023-9-27 | - | Kaust | Correspondência de forma 3D de tiro zero | Siggraph Asia '23 | - |
| 2023-9-21 | LLM-GROWER | U-mich | LLM-GROWER: Aterramento visual 3D de vocabulário aberto com modelo de linguagem grande como um agente | ICRA '24 | Github |
| 2023-9-1 | Point-si | Cuhk | Point-Bind & Point-Llm: Alinhando Cloud com Multi-modalidade para entendimento, geração e instrução em 3D seguintes | Arxiv | Github |
| 2023-8-31 | Pointllm | Cuhk | Pointllm: capacitar grandes modelos de linguagem para entender as nuvens de pontos | ECCV '24 | Github |
| 2023-8-17 | Chat-3d | Zju | Chat-3D: Ajustando dados com eficiência de dados de grande linguagem para diálogo universal de cenas 3D | Arxiv | Github |
| 2023-8-8 | 3d-vista | Bigai | 3d-Vista: Transformador pré-treinado para visão 3D e alinhamento de texto | ICCV '23 | Github |
| 2023-7-24 | 3d-llm | UCLA | 3D-LLM: Injetando o mundo 3D em grandes modelos de idiomas | Neurips '23 | Github |
| 2023-3-29 | ViewRefer | Cuhk | ViewRefer: compre o conhecimento de várias vistas para o aterramento visual 3D | ICCV '23 | Github |
| 2022-9-12 | - | Mit | Aproveitando modelos de idiomas grandes (visuais) para o entendimento da cena do robô 3D | Arxiv | Github |
| EU IA | palavras -chave | Instituto (primeiro) | Papel | Publicação | Outros |
|---|---|---|---|---|---|
| 2024-10-12 | Lexicon3d | Uiuc | Lexicon3D: sondando modelos de fundação visual para compreensão complexa da cena 3D | Neurips '24 | projeto |
| 2024-10-07 | Diff2Scene | CMU | Segmentação semântica 3D de vocabulário aberto com modelos de difusão de texto a imagem | ECCV 2024 | projeto |
| 2024-04-07 | Any2Point | Shanghai Ai Lab | Any2Point: capacitar qualquer modelos grandes de modalidade para entendimento 3D eficiente | ECCV 2024 | Github |
| 2024-03-16 | N2F2 | Oxford-VGG | N2F2: entendimento da cena hierárquica com campos de características neurais aninhadas | Arxiv | - |
| 2023-12-17 | SAI3D | PKU | SAI3D: Segmento de qualquer instância em cenas 3D | Arxiv | projeto |
| 2023-12-17 | Open3dis | Vinai | Open3Dis: Segmentação de instância 3D de vocabulário aberto com orientação de máscara 2D | Arxiv | projeto |
| 2023-11-6 | Ovi-3d | Universidade Rutgers | OVIR-3D: Recuperação de instância 3D de vocabulário aberto sem treinamento em dados 3D | Corl '23 | Github |
| 2023-10-29 | OpenMask3d | Eth | OpenMask3d: Segmentação de instância 3D de vocabulário aberto | Neurips '23 | projeto |
| 2023-10-5 | Fusão aberta | - | Fusão aberta: mapeamento 3D de vocabulário aberto em tempo real e representação de cena consultável | Arxiv | Github |
| 2023-9-22 | OV-3DDET | Hkust | CODA: Descoberta de caixa colaborativa e alinhamento cruzado para detecção de objetos 3D de vocabulário aberto | Neurips '23 | Github |
| 2023-9-19 | LÂMPADA | - | Do idioma aos mundos 3D: adaptação do modelo de linguagem para a percepção da nuvem de pontos | OpenReview | - |
| 2023-9-15 | Opennerf | - | Opennerf: Open Set 3D Neural Scene Segmentation com recursos em pixels e vistas novas renderizadas | OpenReview | Github |
| 2023-9-1 | Openins3d | Cambridge | OpenIns3D: Snap e procure para a segmentação de instância de vocabular em 3D | Arxiv | projeto |
| 2023-6-7 | Elevação contrastiva | Oxford-VGG | Elevação contrastiva: segmentação da instância do objeto 3D por fusão contrastiva lenta e rápida | Neurips '23 | Github |
| 2023-6-4 | Multi-clip | Eth | Multi-clipe: pré-treinamento contrastivo de visão de visão para tarefas de resposta a perguntas em cenas 3D | Arxiv | - |
| 2023-5-23 | 3d-ovs | NTU | Segmentação de vocabulário aberto 3D supervisionado | Neurips '23 | Github |
| 2023-5-21 | VL-campos | Universidade de Edimburgo | Campos de VL: Rumo a representações espaciais implícitas e implícitas de idiomas | ICRA '23 | projeto |
| 2023-5-8 | Clip-Fo3D | Universidade de Tsinghua | CLIP-FO3D: Aprendendo representações de cena 3D em mundo aberto gratuito do clipe dense 2D | ICCVW '23 | - |
| 2023-4-12 | 3D-VQA | Eth | PRÉ-TREINAMENTO DA VISIO | CVPRW '23 | Github |
| 2023-4-3 | RegionPlc | HKU | RegionPlc: aprendizado contrastivo regional de pontuação para o entendimento da cena em mundo aberto 3D | Arxiv | projeto |
| 2023-3-20 | CG3D | Jhu | Clip Goes 3D: Aproveitando o ajuste rápido para o reconhecimento 3D fundamentado em linguagem | Arxiv | Github |
| 2023-3-16 | Lerf | UC Berkeley | Lerf: Campos de radiação incorporados em linguagem | ICCV '23 | Github |
| 2023-2-14 | ConceptFusion | Mit | ConceptFusion: Mapeamento 3D multimodal de set aberto | RSS '23 | projeto |
| 2023-1-12 | CLIP2SCENE | HKU | CLIP2SCENE: Rumo ao entendimento da cena 3D com eficiência de etiqueta por clipe | CVPR '23 | Github |
| 2022-12-1 | Unidade3d | Tum | Unidade3d: um transformador unificado para legendas densas em 3D e aterramento visual | ICCV '23 | Github |
| 2022-11-29 | PLA | HKU | PLA: Entendimento de cena 3D de vocabulário aberto orientado a idiomas | CVPR '23 | Github |
| 2022-11-28 | OpenScene | Etz | OpenScene: entendimento da cena 3D com vocabulários abertos | CVPR '23 | Github |
| 2022-10-11 | Campos de clipes | NYU | Campos de clipes: campos semânticos fracamente supervisionados para memória robótica | Arxiv | projeto |
| 2022-7-23 | Abstração semântica | Columbia | Abstração semântica: Entendimento de cena 3D em mundo aberto de modelos 2D de linguagem de visão | Corl '22 | projeto |
| 2022-4-26 | Scannet200 | Tum | Segmentação semântica interna em campo de idiomas na natureza | ECCV '22 | projeto |
| Data | palavras -chave | Instituto (primeiro) | Papel | Publicação | Outros |
|---|---|---|---|---|---|
| 2023-5-20 | 3d-clr | UCLA | Aprendizagem de conceitos 3D e raciocínio de imagens de várias visualizações | CVPR '23 | Github |
| - | Transcribe3d | TTI, Chicago | Transcribe3D: Grounding LLMS usando informações transcritas para o raciocínio referencial 3D com fino de cor | Corl '23 | Github |
| Data | palavras -chave | Instituto | Papel | Publicação | Outros |
|---|---|---|---|---|---|
| 2023-11-29 | Shapegpt | Universidade de Fudan | Shapegpt: geração de formas 3D com um modelo de linguagem multimodal unificado | Arxiv | Github |
| 2023-11-27 | Meshgpt | Tum | Meshgpt: gerando malhas de triângulo com transformadores apenas para decodificadores | Arxiv | projeto |
| 2023-10-19 | 3D-GPT | Anu | 3D-GPT: modelagem 3D processual com grandes modelos de linguagem | Arxiv | Github |
| 2023-9-21 | Llmr | Mit | LLMR: solicitação em tempo real de mundos interativos usando modelos de idiomas grandes | Arxiv | - |
| 2023-9-20 | Dreamllm | Megvii | Dreamllm: compreensão e criação multimodais sinérgicas | Arxiv | Github |
| 2023-4-1 | Chatavatar | Deemos Tech | Dreamface: Geração progressiva de faces 3D animatáveis sob orientação de texto | ACM TOG | site |
| Data | palavras -chave | Instituto | Papel | Publicação | Outros |
|---|---|---|---|---|---|
| 2024-01-22 | Espacialvlm | DeepMind | Spatialvlm: dotando modelos de linguagem da visão com recursos de raciocínio espacial | CVPR '24 | projeto |
| 2023-11-27 | Dobb-e | NYU | Ao trazer robôs para casa | Arxiv | Github |
| 2023-11-26 | Steve | Zju | Veja e pense: agente incorporado em ambiente virtual | Arxiv | Github |
| 2023-11-18 | Leo | Bigai | Um agente generalista incorporado no mundo 3D | Arxiv | Github |
| 2023-9-14 | Unihsi | Shanghai Ai Lab | Interação unificada de cena humana por meio de contatos solicitados | Arxiv | Github |
| 2023-7-28 | RT-2 | Google Deepmind | RT-2: Modelos de ação de visão de visão transferem conhecimento da Web para controle robótico | Arxiv | Github |
| 2023-7-12 | SayPlan | QUT Center for Robotics | SayPlan: aterrendo grandes modelos de linguagem usando gráficos de cena 3D para planejamento de tarefas de robô escalável | Corl '23 | Github |
| 2023-7-12 | Voxposer | Stanford | Voxposer: mapas de valor 3D composíveis para manipulação robótica com modelos de linguagem | Arxiv | Github |
| 2022-12-13 | RT-1 | RT-1: Transformador de robótica para controle do mundo real em escala | Arxiv | Github | |
| 2022-12-8 | LLM-Planner | A Universidade Estadual de Ohio | Planner LLM: Planejamento fundamentado de poucos tiros para agentes incorporados com grandes modelos de idiomas | ICCV '23 | Github |
| 2022-10-11 | Campos de clipes | NYU, Meta | Campos de clipes: campos semânticos fracamente supervisionados para memória robótica | RSS '23 | Github |
| 2022-09-20 | NLMAP-SAYCAN | Representações de cenas consultáveis de vocabulário aberto para planejamento do mundo real | ICRA '23 | Github |
| Data | palavras -chave | Instituto | Papel | Publicação | Outros |
|---|---|---|---|---|---|
| 2024-09-08 | MSQA / MSNN | Bigai | Raciocínio multimodal situado em cenas 3D | Neurips '24 | projeto |
| 2024-06-10 | 3D-Grand / 3D-Pope | Umich | 3D-Grand: um conjunto de dados em escala para 3D-Llms com melhor aterramento e menos alucinação | Arxiv | projeto |
| 2024-06-03 | Banco espacialrgpt | Ucsd | SpatialRGPT: Raciocínio espacial fundamentado em modelos de linguagem de visão | Neurips '24 | Github |
| 2024-1-18 | Cenário | Bigai | Cenário: Escalando o aprendizado em linguagem da visão em 3D para o entendimento da cena fundamentada | Arxiv | Github |
| 2023-12-26 | EMBODIEDSCAN | Shanghai Ai Lab | EMBODIEDSCAN: uma suíte 3D multimodal holística para a IA incorporada | Arxiv | Github |
| 2023-12-17 | M3dbench | Universidade de Fudan | M3dbench: Vamos instruir modelos grandes com prompts 3D multimodais | Arxiv | Github |
| 2023-11-29 | - | DeepMind | Avaliando VLMs para anotação de objetos 3D baseados em pontuação | Arxiv | Github |
| 2023-09-14 | Crosscohence | Unibo | Olhando para palavras e pontos com atenção: uma referência para coerência de texto a forma | ICCV '23 | Github |
| 2022-10-14 | SQA3D | Bigai | SQA3D: Perguntas situadas respondendo em cenas 3D | ICLR '23 | Github |
| 2021-12-20 | Scanqa | Riken AIP | Scanqa: Resposta de perguntas em 3D para compreensão da cena espacial | CVPR '23 | Github |
| 2020-12-3 | Scan2Cap | Tum | Scan2Cap: legendas densas com reconhecimento de contexto em varreduras RGB-D | CVPR '21 | Github |
| 2020-8-23 | Referit3d | Stanford | Refere-se: ouvintes neurais para identificação de objetos 3D de granulação fina em cenas do mundo real | ECCV '20 | Github |
| 2019-12-18 | ScanRefer | Tum | ScanRefer: localização de objetos 3D em varreduras RGB-D usando linguagem natural | ECCV '20 | Github |
Suas contribuições são sempre bem -vindas!
Vou manter alguns pedidos de tração abertos se não tiver certeza se eles são impressionantes para o 3D LLMS, você pode votar neles adicionando? para eles.
Se você tiver alguma dúvida sobre esta lista opinativa, entre em contato em [email protected] ou Wechat ID: MXZ1997112.
Se você achar esse repositório útil, considere citar este artigo:
@misc{ma2024llmsstep3dworld,
title={When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models},
author={Xianzheng Ma and Yash Bhalgat and Brandon Smart and Shuai Chen and Xinghui Li and Jian Ding and Jindong Gu and Dave Zhenyu Chen and Songyou Peng and Jia-Wang Bian and Philip H Torr and Marc Pollefeys and Matthias Nießner and Ian D Reid and Angel X. Chang and Iro Laina and Victor Adrian Prisacariu},
year={2024},
journal={arXiv preprint arXiv:2405.10255},
}Este repo é inspirado em impressionante-llm


