LLaMA Omni
1.0.0
Autores: Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui MA, Shaoleei Zhang, Yang Feng*
Llama-omni é um modelo de fala baseado na instrução LLAMA-3.1-8B. Ele suporta interações de fala de baixa e alta qualidade, gerando simultaneamente as respostas de texto e fala com base nas instruções de fala.
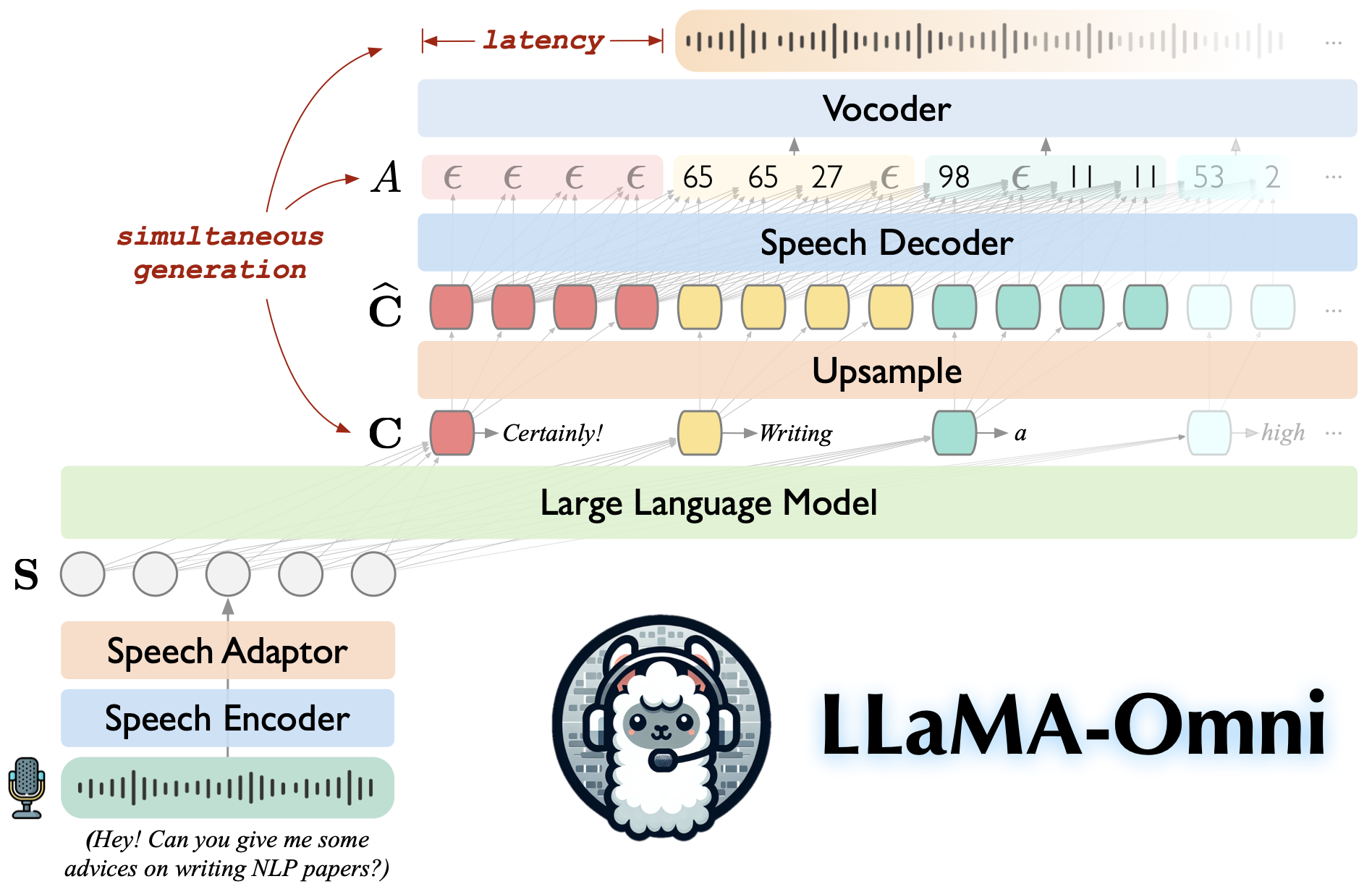
Construído na instrução LLAMA-3.1-8B, garantindo respostas de alta qualidade.
Interação da fala de baixa latência com uma latência tão baixa quanto 226ms.
Geração simultânea de respostas de texto e fala.
♻️ treinado em menos de 3 dias usando apenas 4 GPUs.
Clone este repositório.
clone git https://github.com/ictnlp/llama-omnicd llama-omni
Instale pacotes.
conda create -n llama -omni python = 3.10 O CONDA Ativa a llama-omni pip install pip == 24.0 pip install -e.
Instale fairseq .
clone git https://github.com/pytorch/fairseqcd Fairseq pip install -e. -Não-Build-isolation
Instale flash-attention .
pip install flash-attn--não-build-isolation
Faça o download do modelo Llama-3.1-8B-Omni do? Huggingface.
Faça o download do modelo Whisper-large-v3 .
Importar sussurro
Model = Whisper.load_model ("Large-V3", Download_root = "Models/Speech_Encoder/")Faça o download do vocoder Hifi-Gan baseado na unidade.
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -p vocoder wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -p vocoder/
Inicie um controlador.
python -m omni_speech.serve.Controller -Host 0.0.0.0 --port 10000
Inicie um servidor da Web Gradio.
python -m omni_speech.serve.gradio_web_server-Conntroller http: // localhost: 10000 --port 8000-model-list-mode recluad-vocoder/vocoder/g_00500000-vocoder vocoder/config.json
Inicie um trabalhador modelo.
python -m omni_speech.serve.model_worker-HOST 0.0.0.0-Controller http: // localhost: 10000 --port 40000-worker http: // lochost: 40000-Model-Path llama-3.1-8b-omni -Modelo-name llama-3.1-8b-omni--s2s
Visite http: // localhost: 8000/e interaja com o llama-3.1-8b-omni!
NOTA: Devido à instabilidade do streaming de reprodução de áudio em Gradio, implementamos apenas a síntese de áudio de streaming sem ativar o AutoPlay. Se você tiver uma boa solução, fique à vontade para enviar um PR. Obrigado!
Para executar a inferência localmente, organize os arquivos de instrução de fala de acordo com o formato no diretório omni_speech/infer/examples e consulte o script a seguir.
bash omni_speech/infer/run.sh omni_speech/infer/exemplos
Nosso código é lançado sob a licença Apache-2.0. Nosso modelo é destinado apenas a fins de pesquisa acadêmica e não pode ser usada para fins comerciais.
Você é livre para usar, modificar e distribuir esse modelo em ambientes acadêmicos, desde que as seguintes condições sejam atendidas:
Uso não comercial : o modelo não pode ser usado para fins comerciais.
Citação : se você usar este modelo em sua pesquisa, cite o trabalho original.
Para qualquer consulta de uso comercial ou para obter uma licença comercial, entre em contato com [email protected] .
Llava: a base de código que criamos.
SLAM-LLM: emprestamos algum código sobre o codificador de fala e o adaptador de fala.
Se você tiver alguma dúvida, não hesite em enviar um problema ou entre em contato com [email protected] .
Se nosso trabalho for útil para você, cite como:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

