streaming
v0.9.1
Construímos StreamingDataset para fazer treinamento em grandes conjuntos de dados a partir do armazenamento em nuvem o mais rápido, barato e escalável possível.
Ele foi especialmente projetado para treinamento distribuído e com vários nó para modelos grandes-maximizando garantias de correção, desempenho e facilidade de uso. Agora, você pode treinar com eficiência em qualquer lugar, independentemente do local dos dados de treinamento. Basta transmitir nos dados que você precisa, quando precisar. Para saber mais sobre por que construímos StreamingDataset, leia nosso blog de anúncio.
StreamingDataSet é compatível com qualquer tipo de dados, incluindo imagens, texto, vídeo e dados multimodais .
Com suporte para os principais provedores de armazenamento em nuvem (AWS, OCI, GCS, Azure, Databricks e qualquer armazenamento de objetos compatível com S3, como Cloudflare R2, CoreWeave, Backblaze B2, etc.) e projetado como um substituto de seu pytorch IterAlabledataset classe , StreamingDataSet se integra perfeitamente aos seus fluxos de trabalho de treinamento existentes.

O streaming pode ser instalado com pip :
PIP Instale a transmissão de mosaico
Converta seu conjunto de dados bruto em um de nossos formatos de streaming suportados:
Formato MDS (Mosaic Data Shard) que pode codificar e decodificar qualquer objeto Python
CSV / TSV
Jsonl
importar numpy como npfrom pil importar imagem de streaming importar mdswriter# diretório local ou remoto no qual armazenar os arquivos de saída compactadosdata_dir = 'path-to-dataset'# um dicionário de mapeamento de campos de entrada para seus dados typeScolumns = {'imagem': 'jpeg' , 'classe': 'int'}# compactação de shard, se anycompression = 'zstd'# salve as amostras como shards usando mdswriterwith mdsscriter (out = data_dir, colunas = colunas, compressão = compressão) como fora: para i no intervalo (10000 ): amostra = {'imagem': image.FromArray (np.random.randint (0, 256, (32, 32, 3), np.uint8)), 'classe': np.random.randint (10),
} out.write (amostra)Carregue seu conjunto de dados de streaming para o armazenamento em nuvem de sua escolha (AWS, OCI ou GCP). Abaixo está um exemplo de carregamento de um diretório para um balde S3 usando a CLI da AWS.
$ AWS S3 CP-Recursivo Path-to-DataSet S3: // My-Bucket/Path-to-Dataset
de Torch.utils.data importar dataloader de streaming import streamingDataSet# caminho remoto em que o conjunto de dados completo é persistentemente armazenado. /Path-to-DataSet '# Crie streaming datasetDataset = streamingDataSet (local = local, remoto = remoto, shuffle = true)# Vamos ver o que está na amostra# 1337 ... amostra = conjunto de dados [1337] img = amostra [' imagem '] CLS = amostra [' classe ']# Crie pytorch dataloaderDataloader = Dataloader (DataSet)
Iniciar guias, exemplos, referências de API e outras informações úteis podem ser encontradas em nossos documentos.
Temos tutoriais de ponta a ponta para treinar um modelo sobre:
Cifar-10
Facesyntetics
SyntheticNlp
Também temos código inicial para os seguintes conjuntos de dados populares, que podem ser encontrados no diretório streaming :
| Conjunto de dados | Tarefa | Ler | Escrever |
|---|---|---|---|
| Laion-400m | Texto e imagem | Ler | Escrever |
| WebVid | Texto e vídeo | Ler | Escrever |
| C4 | Texto | Ler | Escrever |
| Enwiki | Texto | Ler | Escrever |
| Pilha | Texto | Ler | Escrever |
| Ade20K | Segmentação de imagem | Ler | Escrever |
| Cifar10 | Classificação da imagem | Ler | Escrever |
| COCO | Classificação da imagem | Ler | Escrever |
| Imagenet | Classificação da imagem | Ler | Escrever |
Para começar a treinar nesses conjuntos de dados:
Converta dados brutos em formato .mds usando o script correspondente no diretório convert .
Por exemplo:
$ python -m streaming.multimodal.convert.webvid - -in <arquivo csv> -Out <MDS Output Directory>
Importar a classe DataSet para começar a treinar o modelo.
de streaming.multimodal importar streamingInsideWebVidDataset = streamingInsideWebVid (local = local, remoto = remoto, shuffle = true)
Experimente facilmente misturas de dados com Stream . A amostragem do conjunto de dados pode ser controlada em relativa (proporção) ou absoluta (repete ou termos de amostras). Durante o streaming, os diferentes conjuntos de dados são transmitidos, embaralhados e misturados sem problemas.
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
Uma característica única de nossa solução: as amostras estão na mesma ordem, independentemente do número de GPUs, nós ou trabalhadores da CPU. Isso facilita:
Reproduzir e depurar treinos e picos de perda
Carregue um ponto de verificação treinado em 64 GPUs e depra em 8 GPUs com reprodutibilidade
Veja a figura abaixo - treinando um modelo em 1, 8, 16, 32 ou 64 GPUs produz exatamente a mesma curva de perda (até as limitações da matemática do ponto flutuante!)
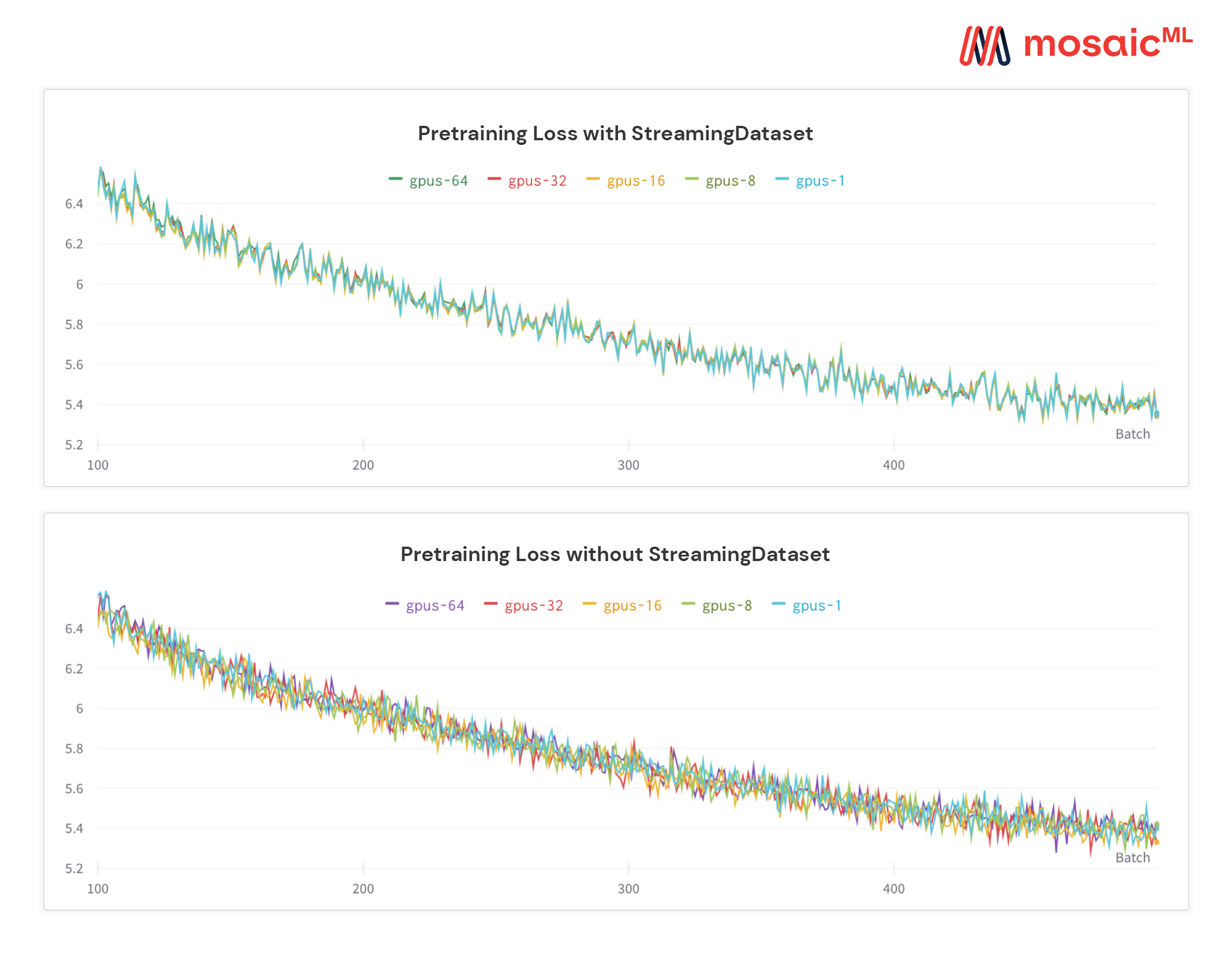
Pode ser caro - e irritante - esperar o seu trabalho retomar enquanto o dataloader gira após uma falha de hardware ou um pico de perda. Graças à nossa ordem determinística de amostra, o StreamingDataSet permite retomar o treinamento em segundos, não horas, no meio de uma longa corrida de treinamento.
Minimizar a latência da retomada pode economizar milhares de dólares em taxas de saída e tempo de computação de GPU ocioso em comparação com as soluções existentes.
Nosso formato de MDS corta o trabalho estranho ao osso, resultando em latência de amostra ultra baixa e maior taxa de transferência em comparação com alternativas para cargas de trabalho gargalenecidas pelo Dataloader.
| Ferramenta | Taxa de transferência |
|---|---|
| StreamingDataSet | ~ 19000 img/s |
| ImageFolder | ~ 18000 img/s |
| WebDataset | ~ 16000 img/s |
Os resultados mostrados são do treinamento ImageNet + ResNet-50, coletados em 5 repetições depois que os dados são armazenados em cache após a primeira época.
O modelo de convergência do uso do streamingDataSet é tão bom quanto usar o disco local, graças ao nosso algoritmo de embaralhamento.
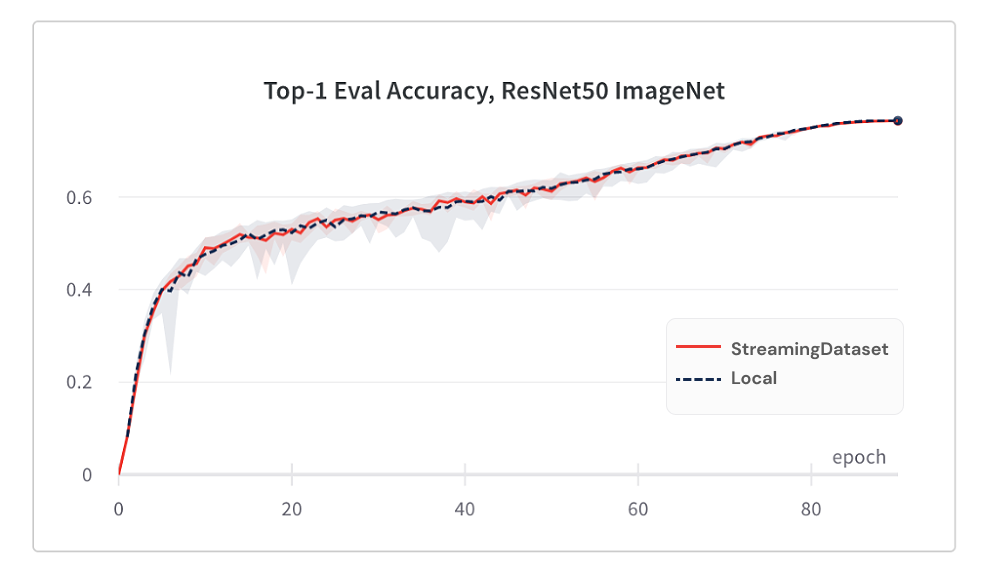
Abaixo estão os resultados do treinamento ImageNet + ResNet-50, coletados em 5 repetições.
| Ferramenta | Precisão Top-1 |
|---|---|
| StreamingDataSet | 76,51% +/- 0,09 |
| ImageFolder | 76,57% +/- 0,10 |
| WebDataset | 76,23% +/- 0,17 |
StreamingDataSet Shuffles em todas as amostras atribuídas a um nó, enquanto soluções alternativas apenas embaralham amostras em uma piscina menor (dentro de um único processo). A trânsito por uma piscina mais ampla espalha mais amostras adjacentes. Além disso, nosso algoritmo de embaralhamento minimiza amostras caídas. Descobrimos esses dois recursos de embaralhamento vantajosos para a convergência do modelo.
Acesse os dados que você precisa quando precisar.
Mesmo que uma amostra ainda não seja baixada, você pode acessar dataset[i] para obter a amostra i . O download será iniciado imediatamente e o resultado será retornado quando for feito - semelhante a um conjunto de dados Pytorch no estilo de mapa, com amostras numeradas sequencialmente e acessíveis em qualquer ordem.
DataSet = StreamingDataSet (...) Amostra = DataSet [19543]
StreamingDataSet Iterará com prazer em qualquer número de amostras. Você não precisa excluir para sempre as amostras para que o conjunto de dados seja divisível em um número de dispositivos assados. Em vez disso, cada época é repetida uma seleção diferente de amostras (nenhuma caiu) para que cada dispositivo processe a mesma contagem.
DataSet = StreamingDataSet (...) dl = Dataloader (DataSet, num_workers = ...)
Exclua dinamicamente os shards usados menos recentemente para manter o uso do disco sob um limite especificado. Isso é ativado definindo o argumento de streamingDataSet cache_limit . Veja o guia de embaralhamento para obter mais detalhes.
dataset = StreamingDataset( cache_limit='100gb', ... )
Aqui estão alguns projetos e experimentos que usaram o StreamingDataset. Tem algo para adicionar? Envie um email para [email protected] ou participe da nossa folga da comunidade.
Biomedlm: um modelo de linguagem grande específico de domínio para biomedicina por Mosaicml e Stanford CRFM
Modelos de difusão em mosaico: treinamento de difusão estável dos custos de zero <$ 160k
Mosaic LLMS: qualidade GPT-3 por <$ 500k
Mosaic Resnet: Treinamento de visão computacional incrivelmente rápida com a resnet em mosaico e compositor
Mosaic Deeplabv3: 5x Treinamento de segmentação de imagem mais rápido com receitas de mosaico
… Mais por vir! Fique atento!
Congratulamo -nos com quaisquer contribuições, solicitações de puxar ou problemas.
Para começar a contribuir, consulte nossa página contribuinte.
PS: Estamos contratando!
Se você gosta deste projeto, dê -nos uma estrela e confira nossos outros projetos:
Compositor - uma biblioteca pytorch moderna que facilita o treinamento de rede neural escalável e eficiente
Exemplos de Mosaicml - Exemplos de referência para o treinamento de modelos de ML rapidamente e com alta precisão - com código inicial para modelos de linguagem GPT / GPT, difusão estável, Bert, Resnet -50 e Deeplabv3
Mosaicml Cloud -Nossa plataforma de treinamento criada para minimizar os custos de treinamento para LLMs, modelos de difusão e outros grandes modelos-com orquestração de várias nuvens, escala de vários nó sem esforço e otimizações sob a alojamento para acelerar o tempo de treinamento
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

