Gemini_API_Entity_Extraction
1.0.0
Neste caderno, usando a API Gemini (Gemini 1.5 Flash), extrairei certas informações do texto Descrição do trabalho que eu raspei e colecionei no site de busca de emprego no passado
No meu projeto anterior, eu raspei e colecionei posições de engenheiro de software anunciadas em um site de busca de emprego, para obter mais detalhes, visite - https://github.com/morikaglobal/jobsite_selenium
Usando meu código de raspagem, os dados são raspados, o processamento de dados necessário e os dados são armazenados no arquivo CSV como este: resultado da pesquisa do canteiro de trabalho (arquivo CSV)
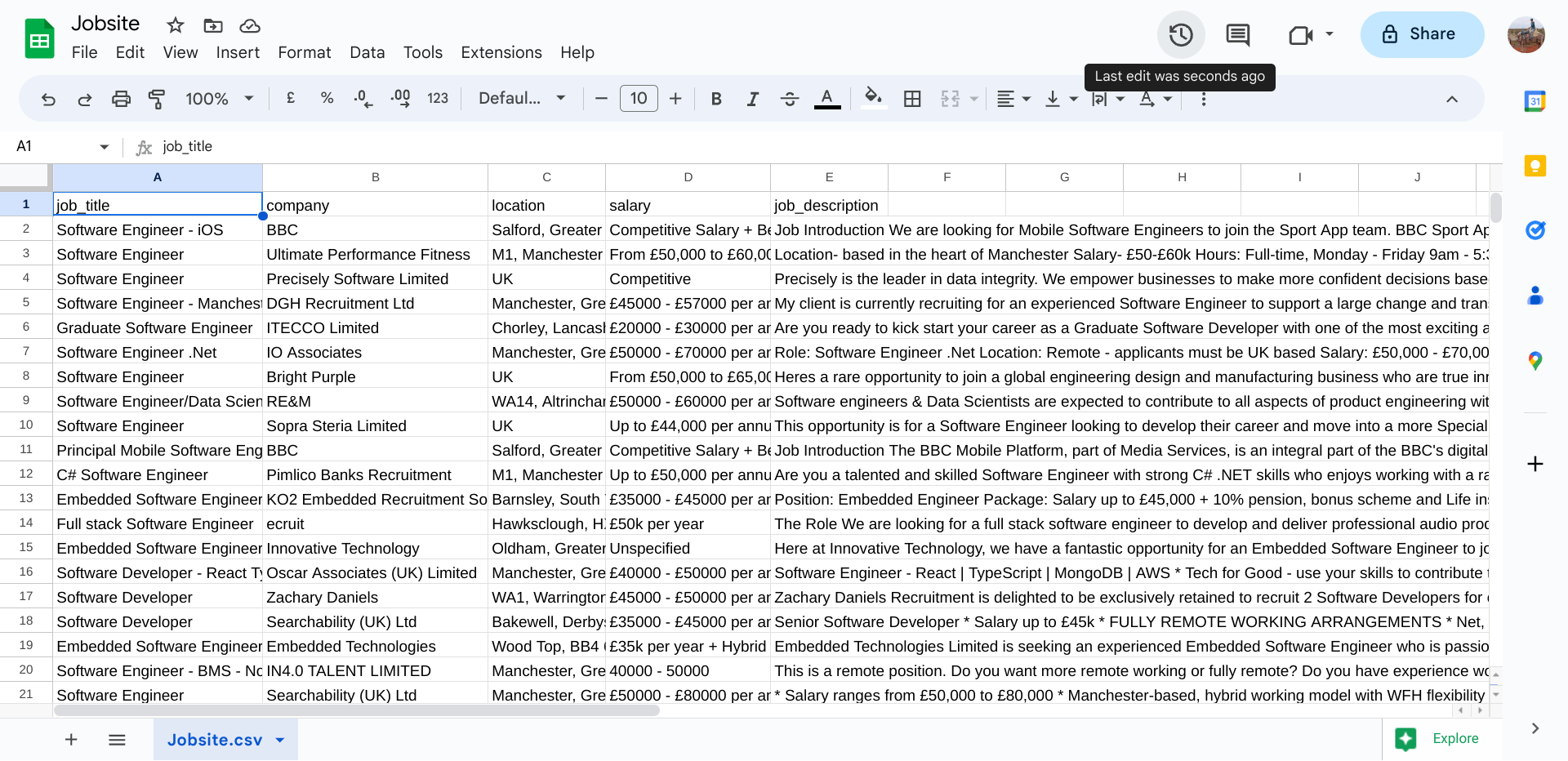
No entanto, notei que algumas posições parecem não estar relacionadas a posições de engenheiros de software, embora os títulos incluem a frase 'engenheiro de software' e linguagens e habilidades de programação específicas necessárias para cada trabalho só podem ser encontradas quando as descrições do trabalho são lidos manualmente.
Usando o Gemini 1.5 Flash, quero identificar se a posição está relacionada ou não ao engenheiro de software, de modo que, se não, posso remover as posições da lista/DataFrame. Ao mesmo tempo, quero utilizar a extração de entidades da API Gemini para que eu possa extrair certas informações - a posição real que os empregadores estão procurando por candidatos, bem como experiência e habilidades necessárias
Vou importar e usar os dados coletados do projeto acima disponível em - https://github.com/morikaglobal/jobsite_selenium/blob/master/jobsite.csv


