Marketing Attribution Models
1.0.10
Classe Python criada para resolver problemas em relação à atribuição de marketing digital.
Enquanto navega on -line, um usuário tem vários pontos de contato antes da conversão, o que pode levar a jornadas cada vez mais longas e mais complexas.
Como conversões devidamente de crédito e optar por investimento na mídia?
Para combater isso, aplicamos modelos de atribuição .
Modelos heurísticos :
Última interação :
Atribuição padrão no Gogle Analytics e outras plataformas de mídia, como o Google Ads e o Facebook Business Manager;
Somente o último ponto de contato é creditado pela conversão.
Último clique não diretamente :
Todo o tráfego direto é ignorado e, portanto, 100% do resultado vai para o último canal através do qual o cliente chegou ao site antes de converter.
Primeira interação :
O resultado é totalmente atribuído ao primeiro ponto de contato.
Linear :
Todo ponto de contato é igualmente creditado.
Decaimento do tempo :
Quanto mais recente um ponto de contato, mais crédito fica.
Baseada em posição :
Nesse modelo, 40% do resultado é atribuído ao último ponto de contato, outros 40% ao primeiro e os 20% restantes são igualmente distribuídos entre os canais intermediários.
Modelos algotítmicos
Valor da Shapley
Utilizado na teoria dos jogos, esse valor é uma estimativa da contribuição de cada jogador individual em um jogo cooperativo.
As conversões são creditadas aos canais por um processo de permitir as viagens. Em cada permutação, é apresentado um canal para estimar o quão essencial é em geral.
Como exemplo , vejamos a seguinte jornada hipotherica:
Pesquisa orgânica> Facebook> Direct> $ 19 (como receita)
Para obter o valor do Shapley de cada canal, primeiro precisamos considerar todos os valores de conversão para as permutações do componente desta jornada.
Pesquisa orgânica> $ 7
Facebook> $ 6
Direto> $ 4
Pesquisa orgânica> Facebook> $ 15
Pesquisa orgânica> Direct> $ 7
Facebook> Diretor> $ 9
Pesquisa orgânica> Facebook> Direct> $ 19
O número de jonhas do componente aumenta exponencialmente os canais mais distintos que você possui: a taxa é de 2^n (2 para a potência de n) para os canais N.
Em outras palavras, com 3 pontos de contato distintos, existem 8 permutações. Com mais de 15 anos, por exemplo, esse processo é inviável .
Por padrão, a ordem dos pontos de contato não é levada em consideração ao calcular o valor do Shapley, apenas sua presença ou falta lá. Para fazer isso, o número de permutações aumenta .
Com isso em mente, observe que é muito difícil usar esse modelo ao considerar a ordem das interações. Para N canais, não apenas existem 2^n permutações de um determinado canal I , mas também todas as permuções que contêm i em uma posição diferente .
Algumas questões e limitações do valor de Shapley
As cadeias de Markov, uma cadeia de Markov, é um processo estocástico específico, no qual a distribuição de probabilidade de qualquer próximo estado depende apenas do que o estado atual é, desconsiderando quaisquer estados precedentes e sua sequência.
Na atribuição multicanal, podemos usar as cadeias de Markov para calcular a probabilidade de interação entre pares de canais de mídia com a matriz de transição .
Em relação à contribuição de cada canal nas conversões, o efeito de remoção entra: para cada Jorney um determinado canal é removido e uma probabilidade de conversão é calculada.
O valor atribuído a um canal, então, é obtido pela razão da diferença entre a probabilidade de conversão em geral e a probabilidade uma vez que o canal é removido sobre a probabilidade geral novamente.
Em outras palavras, quanto maior o efeito de remoção de um canal, maior a sua contribuição.
** Ao trabalhar com processos Markovian, não há restrições devido à quantidade ou ordem dos canais. A sequência deles, por si só, é uma parte fundamental do algoritmo.
>> pip install marketing_attribution_models from marketing_attribution_models import MAM Ao criar um objeto MAM, dois modelos de quadro de dados podem ser usados como entrada, dependendo do valor do parâmetro group_Channels .
Para esta demonstração, usaremos um quadro de dados no qual as viagens ainda não estão agrupadas , com cada linha como uma sessão diferente e sem um ID de viagem exclusivo.
NOTA: A classe MAM possui um parâmetro embutido para criação de identificação de jornada, create_journey_id_based_on_conversion , que, se true , um ID é criado com base no ID do usuário, entrada no parâmetro group_channels_id_list e a coluna indicando que existe uma conversão ou não, cujo cujo O nome é definido pelo parâmetro Journey_With_Conv_Colname .
Nesse cenário, todas as sessões de cada usuário distinto serão encomendadas e, para cada conversão, um novo ID da jornada é criado. No entanto, incentivamos muito que essa criação de identificação de jornada seja personalizada com base no conhecimento específico para os negócios em mãos e conclusões exploratórias. Por exemplo, se em um determinado negócio observar que a duração média da jornada é de cerca de uma semana, um novo Critereon poderá ser definido para que, uma vez que qualquer usuário não tenha nenhuma interação por sete dias, a jornada quebra sob a suposição, houve uma perda de interesse.
Quanto aos parâmetros agora, veja como eles estão configurados para nossos canais de grupo_ canais = TRUE Cenário:
attributions = MAM ( df ,
group_channels = True ,
channels_colname = 'channels' ,
journey_with_conv_colname = 'has_transaction' ,
group_channels_by_id_list = [ 'user_id' ],
group_timestamp_colname = 'visitStartTime' ,
create_journey_id_based_on_conversion = True )Para explorar e entender os recursos do MAM, um "gerador de dados aleatório" foi implementado através do uso do parâmetro random_df quando definido como true .
attributions = MAM ( random_df = True )Depois que o objeto MAM for criado, podemos verificar nosso banco de dados agora com a adição de nossa jornada_id e com sessões agrupadas em viagens usando o atribuído ".dataframe" .
attributions . DataFrame| Journey_id | canais_agg | Time_Till_Conv_Agg | convertido_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID: 0_J: 0 | 0,0 | Verdadeiro | 1 | |
| 1 | ID: 0_J: 1 | Pesquisa do Google | 0,0 | Verdadeiro | 1 |
| 2 | ID: 0_J: 10 | Pesquisa do Google> orgânico> marketing por e -mail | 72,0> 24.0> 0,0 | Verdadeiro | 1 |
| 3 | ID: 0_J: 11 | Orgânico | 0,0 | Verdadeiro | 1 |
| 4 | ID: 0_J: 12 | Email Marketing> Facebook | 432.0> 0,0 | Verdadeiro | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID: 9_J: 5 | Direct> Facebook | 120.0> 0,0 | Verdadeiro | 1 |
| 20342 | ID: 9_J: 6 | Pesquisa do Google> Pesquisa do Google> Pesquisa do Google | 48.0> 24.0> 0,0 | Verdadeiro | 1 |
| 20343 | ID: 9_J: 7 | Orgânico> Organic> Pesquisa do Google> Pesquisa do Google | 480.0> 480.0> 288.0> 0,0 | Verdadeiro | 1 |
| 20344 | ID: 9_J: 8 | Direto> orgânico | 168.0> 0,0 | Verdadeiro | 1 |
| 20345 | ID: 9_J: 9 | Pesquisa do Google> Organic> Pesquisa do Google> Emai ... | 528.0> 528.0> 408.0> 240.0> 0.0 | Verdadeiro | 1 |
Este atributo é atualizado para cada modelo de atribuição gerado. Somente no caso de modelos heurísticos, uma nova coluna é anexada contendo o valor de atribuição dado pelo referido modelo.
Nota: O atributo .DataFrame não interfere em nenhum cálculo do modelo. Se for alterado pelo uso, os seguintes resultados não serão afetados.
attributions . attribution_last_click ()
attributions . DataFrame| Journey_id | canais_agg | Time_Till_Conv_Agg | convertido_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID: 0_J: 0 | 0,0 | Verdadeiro | 1 | |
| 1 | ID: 0_J: 1 | Pesquisa do Google | 0,0 | Verdadeiro | 1 |
| 2 | ID: 0_J: 10 | Pesquisa do Google> orgânico> marketing por e -mail | 72,0> 24.0> 0,0 | Verdadeiro | 1 |
| 3 | ID: 0_J: 11 | Orgânico | 0,0 | Verdadeiro | 1 |
| 4 | ID: 0_J: 12 | Email Marketing> Facebook | 432.0> 0,0 | Verdadeiro | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID: 9_J: 5 | Direct> Facebook | 120.0> 0,0 | Verdadeiro | 1 |
| 20342 | ID: 9_J: 6 | Pesquisa do Google> Pesquisa do Google> Pesquisa do Google | 48.0> 24.0> 0,0 | Verdadeiro | 1 |
| 20343 | ID: 9_J: 7 | Orgânico> Organic> Pesquisa do Google> Pesquisa do Google | 480.0> 480.0> 288.0> 0,0 | Verdadeiro | 1 |
| 20344 | ID: 9_J: 8 | Direto> orgânico | 168.0> 0,0 | Verdadeiro | 1 |
| 20345 | ID: 9_J: 9 | Pesquisa do Google> Organic> Pesquisa do Google> Emai ... | 528.0> 528.0> 408.0> 240.0> 0.0 | Verdadeiro | 1 |
Geralmente, o volume de dados trabalhados é extenso, por isso é impraticável ou mesmo impossível analisar os resultados atribuídos a cada jornada com a transação. Com o atributo group_by_channels_models , no entanto, todos os resultados podem ser vistos agrupados por canal.
Nota : Os resultados agrupados não se substituem , caso o mesmo modelo seja usado em duas instâncias distintas. Ambos (ou até mais) deles são mostrados em " group_by_channels_models ".
attributions . group_by_channels_models| canais | attribution_last_click_heuristic |
|---|---|
| Direto | 2133 |
| Marketing por e -mail | 1033 |
| 3168 | |
| Exibição do Google | 1073 |
| Pesquisa do Google | 4255 |
| 1028 | |
| Orgânico | 6322 |
| YouTube | 1093 |
Assim como no atributo .dataframe , group_by_channels_models também é atualizado para todos os modelos usados sem a limitação de não exibir resultados algorítmicos.
attributions . attribution_shapley ()
attributions . group_by_channels_models| canais | attribution_last_click_heuristic | attribution_shapley_size4_conv_rate_algoritmic | |
|---|---|---|---|
| 0 | Direto | 109 | 74.926849 |
| 1 | Marketing por e -mail | 54 | 70.558428 |
| 2 | 160 | 160.628945 | |
| 3 | Exibição do Google | 65 | 110.649352 |
| 4 | Pesquisa do Google | 193 | 202.179519 |
| 5 | 64 | 72.982433 | |
| 6 | Orgânico | 315 | 265.768549 |
| 7 | YouTube | 58 | 60.305925 |
Todos os modelos heurísticos se comportam o mesmo ao usar os atributos .DataFrame e .group_by_channels_models , conforme explicado antes, e a saída de todos os métodos do modelo heurístico retornam uma tupla contendo duas séries de pandas .
attribution_first_click = attributions . attribution_first_click ()A primeira série da tupla são os resultados em uma granularidade de jornada , semelhante à observada no atributo .dataframe
attribution_first_click [ 0 ] 0 [1, 0, 0, 0, 0]
1 [1]
2 [1, 0, 0, 0, 0, 0, 0, 0, 0]
3 [1, 0]
4 [1]
...
20512 [1, 0]
20513 [1, 0, 0]
20514 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
20515 [1, 0, 0]
20516 [1, 0, 0, 0]
Length: 20517, dtype: object
O segundo contém os resultados com uma granularidade de canal , como visto no atributo .group_by_channels_models .
attribution_first_click [ 1 ]| canais | attribution_first_click_heuristic | |
|---|---|---|
| 0 | Direto | 2078 |
| 1 | Marketing por e -mail | 1095 |
| 2 | 3177 | |
| 3 | Exibição do Google | 1066 |
| 4 | Pesquisa do Google | 4259 |
| 5 | 1007 | |
| 6 | Orgânico | 6361 |
| 7 | YouTube | 1062 |
De todos os modelos presentes no objeto mam, apenas o último clique, o primeiro clique e o linear não têm parâmetros personalizáveis , mas group_by_channels_models , que tem um valor booleano que, quando definido, o modelo não retorna a atribuição gorupida por canais.
Criado para replicar a atribuição padrão do Google Analytics ( Last Click Non Direct ), no qual o tráfego direto é substituído , caso as interações anteriores tenham uma fonte de tráfego específica diferente de si mesma em um determinado tempo (6 meses por padrão).
Se não especificado, o parâmetro but_not_this_channel está definido como 'direto' , mas pode ser definido como qualquer outro canal de interesse para o negócio.
attributions . attribution_last_click_non ( but_not_this_channel = 'Direct' )[ 1 ]| canais | attribution_last_click_non_direct_heuristic | |
|---|---|---|
| 0 | Direto | 11 |
| 1 | Marketing por e -mail | 60 |
| 2 | 172 | |
| 3 | Exibição do Google | 69 |
| 4 | Pesquisa do Google | 224 |
| 5 | 67 | |
| 6 | Orgânico | 350 |
| 7 | YouTube | 65 |
Este modelo possui um parâmetro list_positos_first_middle_last , no qual os pesos, respectivamente, para as posições dos canais em cada jornada, podem me especificar de acordo com as decisões relacionadas à empresa . A distribuição padrão do parâmetro é de 40% para o canal introduzido , 40% para a conversão / último canal e 20% para os intermidiados .
attributions . attribution_position_based ( list_positions_first_middle_last = [ 0.3 , 0.3 , 0.4 ])[ 1 ]| canais | attribution_position_based_0.3_0.3_0.4_heuristic | |
|---|---|---|
| 0 | Direto | 95.685085 |
| 1 | Marketing por e -mail | 57.617191 |
| 2 | 145.817501 | |
| 3 | Exibição do Google | 56.340693 |
| 4 | Pesquisa do Google | 193.282305 |
| 5 | 54.678557 | |
| 6 | Orgânico | 288.148896 |
| 7 | YouTube | 55.629772 |
Existem duas configurações personalizáveis: a taxa de decaimento , através do parâmetro Decay_over_time * e o tempo (em horas) entre cada decainidade através do parâmetro de frequência .
Vale a pena notar, no entanto, que, caso haja mais de um ponto de contato entre os intervalos de frequência, o valor de conversão será igualmente distribuído entre esses canais.
Como exemplo:
attributions . attribution_time_decay (
decay_over_time = 0.6 ,
frequency = 7 )[ 1 ]| canais | attribution_time_decay0.6_freq7_heuristic | |
|---|---|---|
| 0 | Direto | 108.679538 |
| 1 | Marketing por e -mail | 54.425914 |
| 2 | 159.592216 | |
| 3 | Exibição do Google | 64.350107 |
| 4 | Pesquisa do Google | 192.838884 |
| 5 | 64.611414 | |
| 6 | Orgânico | 314.920082 |
| 7 | YouTube | 58.581845 |
Uppon sendo chamado, este modelo retorna uma tupla com quatro componentes. Os dois primeiros (indexados 0 e 1) são parecidos com os modelos heurísticos, com a representação do .DataFrame e .group_by_channels_models , respectivamente. Quanto aos terceiros e quartos componentes (indexados 2 e 3), os resultados são a matriz de transição e a tabela de efeito de remoção .
Para começar, é possível indicar se as mesmas transições de estado são consideradas ou não ( por exemplo, direto para diretamente).
attribution_markov = attributions . attribution_markov ( transition_to_same_state = False )| canais | attribution_markov_algorítmico | |
|---|---|---|
| 0 | Direto | 2305.324362 |
| 1 | Marketing por e -mail | 1237.400774 |
| 2 | 3273.918832 | |
| 3 | YouTube | 1231.183938 |
| 4 | Pesquisa do Google | 4035.260685 |
| 5 | 1205.949095 | |
| 6 | Orgânico | 5358.270644 |
| 7 | Exibição do Google | 1213.691671 |
Essa configuração não afeta os resultados gerais atribuídos para cada canal, mas os valores observados na matriz de transição . Porque definimos transição_to_same_state como false , a diagonal, indicando que os estados em transição para si mesmos, são anulados.
ax , fig = plt . subplots ( figsize = ( 15 , 10 ))
sns . heatmap ( attribution_markov [ 2 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )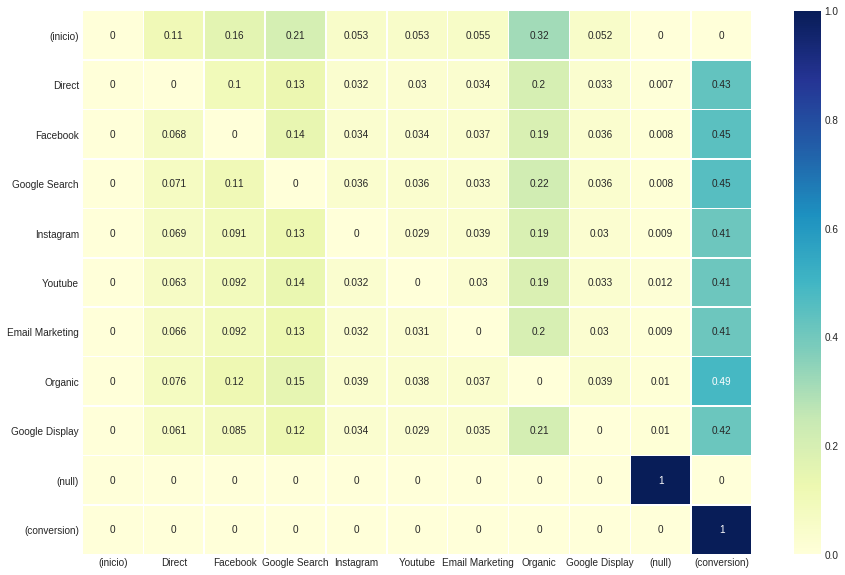
O efeito de remoção , a quarta saída Attribution_Markov , é obtida pela razão da diferença entre a probabilidade de conversão em geral e a probabilidade uma vez que o canal é removido sobre a probabilidade geral novamente.
ax , fig = plt . subplots ( figsize = ( 2 , 5 ))
sns . heatmap ( attribution_markov [ 3 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )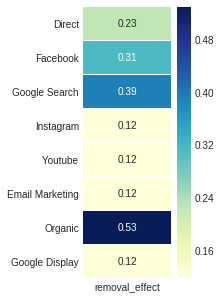
Finalmente, o segundo modelo Algorith da Mam cujo conceito vem da teoria dos jogos . O objetivo aqui é distribuir a contribuição de cada jogador (no nosso caso, canal) em um jogo de cooperação calculado usando combinações de viagens com e sem um determinado canal.
O tamanho do parâmetro define um limite de quanto tempo dura uma cadeia de canais em todas as jornadas. Por padrão, seu valor é definido como 4 , o que significa que apenas os quatro últimos canais que precedem uma conversão são considerados.
O método de cálculo das contribuições marginais de cada canal pode variar com o parâmetro de ordem . Por padrão, ele é definido como falso , o que significa que a contribuição é calculada desconsiderando a ordem de cada canal nas jornadas.
attributions . attribution_shapley ( size = 4 , order = True , values_col = 'conv_rate' )[ 0 ]| Combinações | conversões | Total_seques | conversion_value | conv_rate | attribution_shapley_size4_conv_rate_order_algoritmic | |
|---|---|---|---|---|---|---|
| 0 | Direto | 909 | 926 | 909 | 0,981641 | [909.0] |
| 1 | Direct> Email Marketing | 27 | 28 | 27 | 0,964286 | [13.948270234099155, 13.051729765900845] |
| 2 | Direct> Email Marketing> Facebook | 5 | 5 | 5 | 1.000000 | [1.6636366232390172, 1.5835883671498818, 1.752 ... |
| 3 | Direct> Email Marketing> Facebook> Google D ... | 1 | 1 | 1 | 1.000000 | [0,2563402919193473, 0,2345560799963515, 0,259 ... |
| 4 | Direct> Email Marketing> Facebook> Google s ... | 1 | 1 | 1 | 1.000000 | [0,2522517802130265, 0,2401286956930936, 0,255 ... |
| ... | ... | ... | ... | ... | ... | ... |
| 1278 | YouTube> Organic> Pesquisa do Google> Google Dis ... | 1 | 2 | 1 | 0,500000 | [0,2514214624662836, 0,24872101523605275, 0,24 ... |
| 1279 | YouTube> Organic> Pesquisa do Google> Instagram | 1 | 1 | 1 | 1.000000 | [0,2544401477637237, 0,2541071889956603, 0,253 ... |
| 1280 | YouTube> Organic> Instagram | 4 | 4 | 4 | 1.000000 | [1.2757196742326997, 1.4712839059493295, 1.252 ... |
| 1281 | YouTube> Organic> Instagram> Facebook | 1 | 1 | 1 | 1.000000 | [0,2357631944623868, 0,2610913781266248, 0,247 ... |
| 1282 | YouTube> Organic> Instagram> Pesquisa do Google | 3 | 3 | 3 | 1.000000 | [0,7223482210689489, 0,7769049003203142, 0,726 ... |
Finalmente, o parâmetro indicando qual métrica é usada para calcular o valor do Shapley é valores_col , que por padrão está definido como taxa de conversão . Ao fazer isso, viagens sem conversões são levadas para aceitar.
É possível, no entanto, considerar apenas conversões literais ao usar o modelo como visto abaixo.
attributions . attribution_shapley ( size = 3 , order = False , values_col = 'conversions' )[ 0 ]| Combinações | conversões | Total_seques | conversion_value | conv_rate | attribution_shapley_size3_conversions_algoritmic | |
|---|---|---|---|---|---|---|
| 0 | Direto | 11 | 18 | 18 | 0.611111 | [11.0] |
| 1 | Direct> Email Marketing | 4 | 5 | 5 | 0,800000 | [2.0, 2.0] |
| 2 | Direct> Email Marketing> Pesquisa do Google | 1 | 2 | 2 | 0,500000 | [-3.1666666666666665, -7.666666666666666, 11.8 ... |
| 3 | Direct> email marketing> orgânico | 4 | 6 | 6 | 0,666667 | [-7.8333333333333333, -10.83333333333333332, 22.6 ... |
| 4 | Direct> Facebook | 3 | 4 | 4 | 0,750000 | [-8,5, 11.5] |
| ... | ... | ... | ... | ... | ... | ... |
| 75 | Instagram> Organic> YouTube | 46 | 123 | 123 | 0,373984 | [5.8333333333333332, 34.333333333333333, 5.83333 ... |
| 76 | Instagram> YouTube | 2 | 4 | 4 | 0,500000 | [2,0, 0,0] |
| 77 | Orgânico | 64 | 92 | 92 | 0,695652 | [64.0] |
| 78 | Orgânico> YouTube | 8 | 11 | 11 | 0,727273 | [30.5, -22,5] |
| 79 | YouTube | 11 | 15 | 15 | 0,733333 | [11.0] |
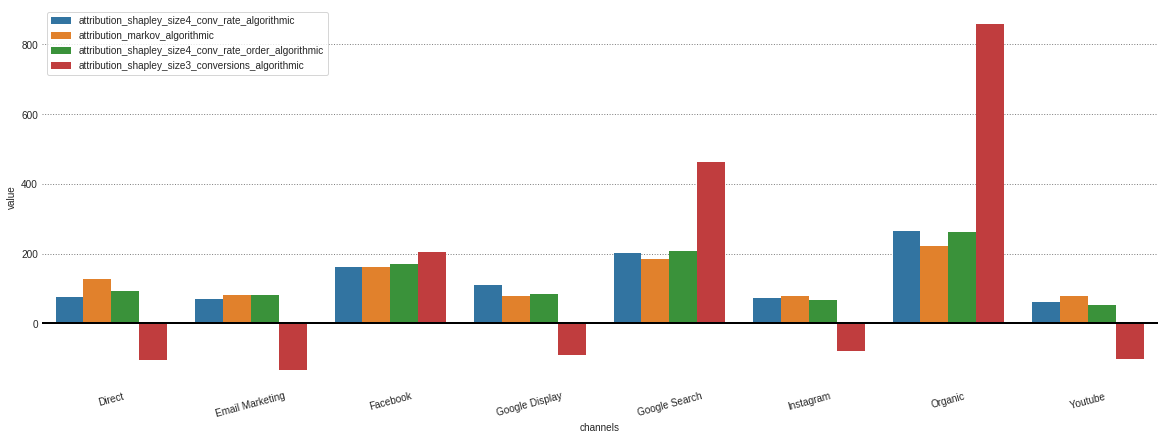
Depois de obter todas as atribuições de diferentes modelos armazenados em nosso objeto .group_by_channels_models , é possível plotar e comparar resultados para insights
attributions . plot ()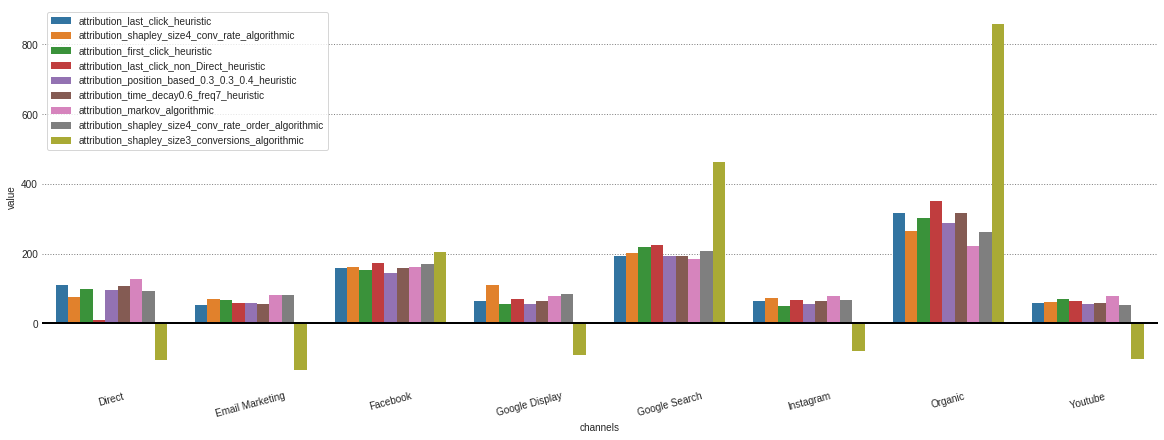
Caso você esteja interessado apenas nos modelos algorítmicos, isso pode me especificar no parâmetro Model_Type .
attributions . plot ( model_type = 'algorithmic' )