ainovelprompter
1.0.0
O romance da AI Prompter pode gerar avisos de escrita para romances com base em características especificadas pelo usuário.
A IA Novel Prompter é um aplicativo de desktop projetado para ajudar os escritores a criar instruções consistentes e bem estruturadas para assistentes de redação de IA como ChatGPT e Claude. A ferramenta ajuda a gerenciar elementos da história, detalhes do personagem e gerar instruções adequadamente formatadas para continuar seu romance.
O executável está no executável Build/Bin
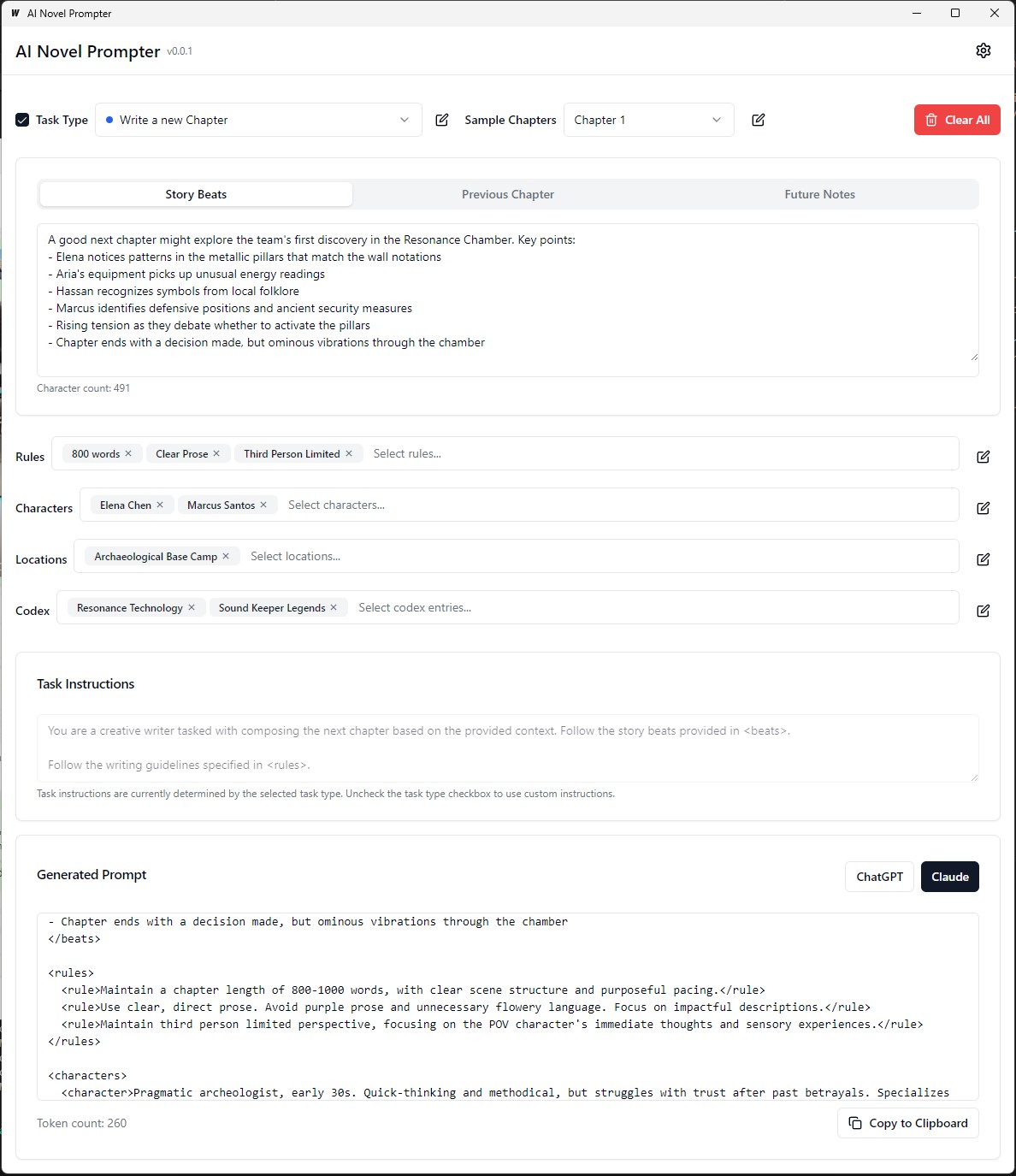
Cada categoria pode ser editada, salva e reutilizada em diferentes avisos:
Front-end :
Back -end :
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev Para construir um pacote redistribuível de modo de produção, use wails build .
wails buildO executável está no executável Build/Bin
Ou gerá -lo com:
wails build -nsisIsso pode ser feito para o Mac também, consulte a parte mais recente deste guia
O aplicativo construído estará disponível no diretório build .
Configuração inicial :
Criando um prompt :
Gerando saída :
Antes de executar o aplicativo, verifique se você tem o seguinte instalado:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Navegue até o diretório server :
cd server
Instale as dependências Go:
go mod download
Atualize o arquivo config.yaml com sua configuração de banco de dados.
Execute as migrações de banco de dados:
go run cmd/main.go migrate
Inicie o servidor de back -end:
go run cmd/main.go
Navegue até o diretório client :
cd ../client
Instale as dependências do front -end:
npm install
Inicie o servidor de desenvolvimento de front -end:
npm start
http://localhost:3000 para acessar o aplicativo. git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Atualize o arquivo docker-compose.yml com a configuração do seu banco de dados.
Inicie o aplicativo usando o Docker Compose:
docker-compose up -d
http://localhost:3000 para acessar o aplicativo. server/config.yaml .client/src/config.ts . Para construir o front -end para produção, execute o seguinte comando no diretório client :
npm run build
Os arquivos prontos para produção serão gerados no diretório client/build .
Este pequeno guia fornece instruções sobre como instalar o PostgreSQL no subsistema do Windows para Linux (WSL), juntamente com as etapas para gerenciar as permissões de usuário e solucionar problemas comuns.
Terminal WSL aberto : inicie sua distribuição WSL (recomendou o Ubuntu).
Pacotes de atualização :
sudo apt updateInstale o PostgreSQL :
sudo apt install postgresql postgresql-contribVerifique a instalação :
psql --versionDefina a senha do usuário do PostGresql :
sudo passwd postgresCrie banco de dados :
createdb mydbBanco de dados de acesso :
psql mydbImportar tabelas do arquivo SQL :
psql -U postgres -q mydb < /path/to/file.sqlListar bancos de dados e tabelas :
l # List databases
dt # List tables in the current databaseSwitch Database :
c dbnameCrie novo usuário :
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;Privilégios de concessão :
ALTER USER your_db_user CREATEDB;A função não existe erro : mude para o usuário 'PostGres':
sudo -i -u postgres
createdb your_db_namePermissão negada para criar extensão : login como 'postgres' e execute:
CREATE EXTENSION IF NOT EXISTS pg_trgm; Erro desconhecido do usuário : verifique se você está usando um usuário reconhecido do sistema ou consulte corretamente um usuário do PostgreSQL no ambiente SQL, não via sudo .
Para gerar dados de treinamento personalizado para ajustar um modelo de idioma para imitar o estilo de escrita de George MacDonald, o processo começa obtendo o texto completo de um de seus romances ", a princesa e o duende", do Projeto Gutenberg. O texto é então dividido em batidas individuais de história ou momentos -chave usando um aviso que instrui a IA a gerar um objeto JSON para cada batida, capturando o autor, o tom emocional, o tipo de escrita e o trecho de texto real.
Em seguida, o GPT-4 é usado para reescrever cada uma dessas histórias com suas próprias palavras, gerando um conjunto paralelo de dados JSON com identificadores exclusivos que ligam cada batida reescrita ao seu colega original. Para simplificar os dados e torná -los mais úteis para o treinamento, a grande variedade de tons emocionais é mapeada para um conjunto menor de tons principais usando uma função Python. Os dois arquivos JSON (batidas originais e reescritas) são usadas para gerar prompts de treinamento, onde o modelo é solicitado a reformular o texto gerado pelo GPT-4 no estilo do autor original. Finalmente, esses avisos e suas saídas de destino são formatados nos arquivos JSONL e JSON, prontos para serem usados para ajustar o modelo de idioma para capturar o estilo de escrita distintivo de MacDonald.
No exemplo anterior, o processo de geração de texto parafraseado usando um modelo de idioma envolveu algumas tarefas manuais. O usuário teve que fornecer manualmente o texto de entrada, executar o script e revisar a saída gerada para garantir sua qualidade. Se a saída não atender aos critérios desejados, o usuário precisará repetir manualmente o processo de geração com diferentes parâmetros ou fazer ajustes no texto de entrada.
No entanto, com a versão atualizada da função process_text_file , todo o processo foi totalmente automatizado. A função cuida da leitura do arquivo de texto de entrada, dividindo -o em parágrafos e enviando automaticamente cada parágrafo para o modelo de idioma para parafrasear. Ele incorpora várias verificações e mecanismos de tentativa de lidar com casos em que a saída gerada não atende aos critérios especificados, como a contenção de frases indesejadas, sendo muito curta ou muito longa ou consistindo em múltiplos parágrafos.
O processo de automação inclui vários recursos importantes:
Retomando do último parágrafo processado: se o script for interrompido ou precisar ser executado várias vezes, ele verifica automaticamente o arquivo de saída e retoma o processamento do último parágrafo parafraseado com sucesso. Isso garante que o progresso não seja perdido e o script possa pegar de onde parou.
Mecanismo de repetição com sementes e temperaturas aleatórias: se uma paráfrase gerada não atender aos critérios especificados, o script experimenta automaticamente o processo de geração até um número especificado de vezes. A cada tentativa, altera aleatoriamente os valores de semente e temperatura para introduzir variação nas respostas geradas, aumentando as chances de obter uma saída satisfatória.
Economia de progresso: o script salva o progresso para o arquivo de saída todos os números especificados de parágrafos (por exemplo, a cada 500 parágrafos). Isso protege contra a perda de dados em caso de interrupções ou erros durante o processamento de um grande arquivo de texto.
Registro e resumo detalhados: o script fornece informações detalhadas de registro, incluindo o parágrafo de entrada, saída gerada, tentativas de repetição e razões de falha. Ele também gera um resumo no final, exibindo o número total de parágrafos, parafraseou com sucesso parágrafos, parágrafos ignorados e o número total de tentativas.
Para gerar dados de treinamento personalizado do ORPO para ajustar um modelo de idioma para imitar o estilo de escrita de George MacDonald.
Os dados de entrada devem estar no formato JSONL, com cada linha contendo um objeto JSON que inclui a resposta prompt e escolhida. (No ajuste fino anterior) Para usar o script, você precisa configurar o cliente OpenAI com sua tecla API e especificar os caminhos de arquivo de entrada e saída. A execução do script processará o arquivo JSONL e gerará um arquivo CSV com colunas para o prompt, resposta escolhida e uma resposta rejeitada gerada. O script economiza progresso a cada 100 linhas e pode retomar de onde parou se interrompido. Após a conclusão, ele fornece um resumo do total de linhas processadas, linhas escritas, linhas ignoradas e detalhes de tentativa.
Qualidade do conjunto de dados Assuntos: 95% dos resultados dependem da qualidade do conjunto de dados. Um conjunto de dados limpo é essencial, pois mesmo um pouco de dados ruins pode prejudicar o modelo.
Revisão de dados manuais: Limpeza e avaliação do conjunto de dados podem melhorar bastante o modelo. Esta é uma etapa demorada, mas necessária, porque nenhuma quantidade de ajuste de parâmetro pode corrigir um conjunto de dados defeituosos.
Os parâmetros de treinamento não devem melhorar, mas impedem a degradação do modelo. Em conjuntos de dados robustos, o objetivo deve ser evitar repercussões negativas enquanto direciona o modelo. Não há taxa de aprendizado ideal.
Limitações de escala e hardware do modelo: modelos maiores (parâmetros 33b) podem permitir melhores ajustes finos, mas requerem pelo menos 48 GB de VRAM, tornando-os impraticáveis para a maioria das configurações domésticas.
Acumulação de gradiente e tamanho do lote: o acúmulo de gradiente ajuda a reduzir o excesso de ajuste, aumentando a generalização em diferentes conjuntos de dados, mas pode reduzir a qualidade após alguns lotes.
O tamanho do conjunto de dados é mais importante para ajustar um modelo básico do que um modelo bem ajustado. Sobrecarregar um modelo bem ajustado com dados excessivos pode degradar seu ajuste fino anterior.
Um cronograma ideal da taxa de aprendizado começa com uma fase de aquecimento, se mantém estável para uma época e depois diminui gradualmente usando um cronograma de cosseno.
Classificação e generalização do modelo: a quantidade de parâmetros treináveis afeta os detalhes e generalização do modelo. Os modelos de baixo rank generalizam melhor, mas perdem detalhes.
A aplicabilidade de Lora: o ajuste fino com eficiência de parâmetro (PEFT) é aplicável a grandes modelos de linguagem (LLMS) e sistemas como difusão estável (SD), demonstrando sua versatilidade.
A comunidade não lotada ajudou a resolver vários problemas com o Finetuning Llama3. Aqui estão alguns pontos -chave a serem lembrados:
Tokens Bos Double : Tokens Bos Double durante o Finetuning pode quebrar as coisas. A UNSLOTH corrige automaticamente esse problema.
Conversão GGUF : A conversão do GGUF está quebrada. Tenha cuidado com o BOS duplo e use a CPU em vez de GPU para conversão. A UNSLOTH possui conversões automáticas de GGUF incorporadas.
Pesos da base de buggy : alguns dos pesos da base da LLAMA 3 (não instruções) são "buggy" (não treinados): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> . Isso pode causar resultados de Nans e buggy. A UNSLOTH corrige automaticamente isso.
Prompt Sistema : De acordo com a comunidade não lotada, a adição de um prompt do sistema torna muito melhor o Finetuning da versão Instruct (e possivelmente a versão base).
Questões de quantização : os problemas de quantização são comuns. Veja esta comparação que mostra que você pode obter um bom desempenho com o LLAMA3, mas usar a quantização errada pode prejudicar o desempenho. Para o Finetuning, use o BitsandBytes NF4 para aumentar a precisão. Para o GGUF, use as versões I o máximo possível.
Modelos de contexto longo : modelos de contexto longo são pouco treinados. Eles simplesmente estendem a corda teta, às vezes sem treinamento, e depois treinam em um conjunto de dados concatenados estranhos para torná -lo um conjunto de dados longo. Essa abordagem não funciona bem. Uma escala de contexto longa e suave e contínua teria sido muito melhor se a escala de 8k a 1M de comprimento de contexto.
Para resolver alguns desses problemas, use UNSLOTH para o Finetuning Llama3.
Ao ajustar um modelo de idioma para parafrasear no estilo de um autor, é importante avaliar a qualidade e a eficácia das paráfrases geradas.
As seguintes métricas de avaliação podem ser usadas para avaliar o desempenho do modelo:
BLEU (Avaliação Bilíngue subestudo):
sacrebleu em Python.from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge (subestudo orientado para recall para avaliação esbelta):
rouge em Python.from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)Perplexidade:
perplexity = model.perplexity(generated_paraphrases)Medidas estilométricas:
stylometry em Python.from stylometry import extract_features; features = extract_features(generated_paraphrases)Para integrar essas métricas de avaliação ao seu pipeline Axolotl, siga estas etapas:
Prepare seus dados de treinamento criando um conjunto de dados de parágrafos das obras do autor -alvo e dividindo -o em conjuntos de treinamento e validação.
Tune seu modelo de idioma usando o conjunto de treinamento, seguindo a abordagem discutida anteriormente.
Gere paráfrases para os parágrafos no conjunto de validação usando o modelo ajustado.
Implemente as métricas de avaliação usando as respectivas bibliotecas ( sacrebleu , rouge , stylometry ) e calcule as pontuações para cada paráfrase gerada.
Realize avaliação humana coletando classificações e feedback dos avaliadores humanos.
Analise os resultados da avaliação para avaliar a qualidade e o estilo das paráfrases geradas e tomar decisões informadas para melhorar seu processo de ajuste fino.
Aqui está um exemplo de como você pode integrar essas métricas ao seu pipeline:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )Lembre -se de instalar as bibliotecas necessárias (Sacrebleu, Rouge, Stilometria) e adaptar o código para se adequar à sua implementação no Axolotl ou similar.
Neste experimento, explorei os recursos e diferenças entre vários modelos de IA na geração de um texto de 1500 palavras com base em um prompt detalhado. Testei modelos de https://chat.lmsys.org/, chatgpt4, Claude 3 Opus e alguns modelos locais no LM Studio. Cada modelo gerou o texto três vezes para observar a variabilidade em suas saídas. Também criei um prompt separado para avaliar a redação da primeira iteração de cada modelo e pedi ao ChatGPT 4 e Claude Opus 3 para fornecer feedback.
Através desse processo, observei que alguns modelos exibem maior variabilidade entre execuções, enquanto outros tendem a usar uma redação semelhante. Também houve diferenças significativas no número de palavras geradas e na quantidade de diálogo, descrições e parágrafos produzidos por cada modelo. O feedback da avaliação revelou que o ChatGPT sugere uma prosa mais "refinada", enquanto Claude recomenda menos prosa roxa. Com base nessas descobertas, compilei uma lista de sugestões para incorporar no próximo prompt, concentrando -se em precisão, estruturas de frases variadas, verbos fortes, reviravoltas únicas em motivos de fantasia, tom consistente, voz de narrador distinta e ritmo envolvente. Outra técnica a considerar é pedir feedback e reescrever o texto com base nesse feedback.
Estou aberto a colaborar com outras pessoas para ajustar ainda mais prompts para cada modelo e explorar suas capacidades nas tarefas de escrita criativa.
Os modelos têm vieses de formatação inerente. Alguns modelos preferem hífens para listas, outros asteriscos. Ao usar esses modelos, é útil refletir suas preferências para saídas consistentes.
Tendências de formatação:
LLAMA 3 Prefere listas com títulos e asteriscos em negrito.
Exemplo: cabeçalho de estojo de título em negrito
Liste itens com asteriscos após duas novas linhas
Liste os itens separados por uma nova linha
Próxima lista
Mais itens da lista
Etc ...
Exemplos de poucos anos:
Sistema Prompt Aderência:
Janela de contexto:
Censura:
Inteligência:
Consistência:
Listas e formatação:
Configurações de bate -papo:
Configurações de pipeline:
O LLAMA 3 é flexível e inteligente, mas tem contexto e citando limitações. Ajuste os métodos de solicitação de acordo.
Todos os comentários são bem -vindos. Abra um problema ou envie uma solicitação de tração se encontrar algum bug ou tiver recomendações para melhorias.
Este projeto está licenciado em: Licença Attribution-NonCommercial-Noderivatives (BY-NC-ND), consulte: https://creativecoMmons.org/license/by-nnc/4.0/deed.en


