mario ai
1.0.0
Este projeto contém código para treinar um modelo que reproduz automaticamente o primeiro nível do Super Mario World usando apenas pixels brutos como entrada (sem recursos de engenharia manual). A técnica usada é profunda Q-Learning, conforme descrito no artigo Atari (resumo), combinado com um transformador espacial.
O método de treinamento é profundo em q-learning com uma memória de repetição, ou seja, o modelo observa sequências de telas, salva-as em sua memória e depois treina nelas, onde "treinamento" significa que aprende a prever com precisão os valores esperados de recompensa de ação (" ação "significa" pressione o botão x ") com base nas memórias coletadas. A memória de repetição tem, por padrão, um tamanho de 250 mil entradas. Quando começa a ficar cheio, novas entradas substituem as mais antigas. Para os lotes de treinamento, os exemplos são escolhidos aleatoriamente (distribuição uniforme) e as recompensas das memórias são reestimadas com base no que a rede aprendeu até agora.
A entrada de cada exemplo tem a seguinte estrutura:
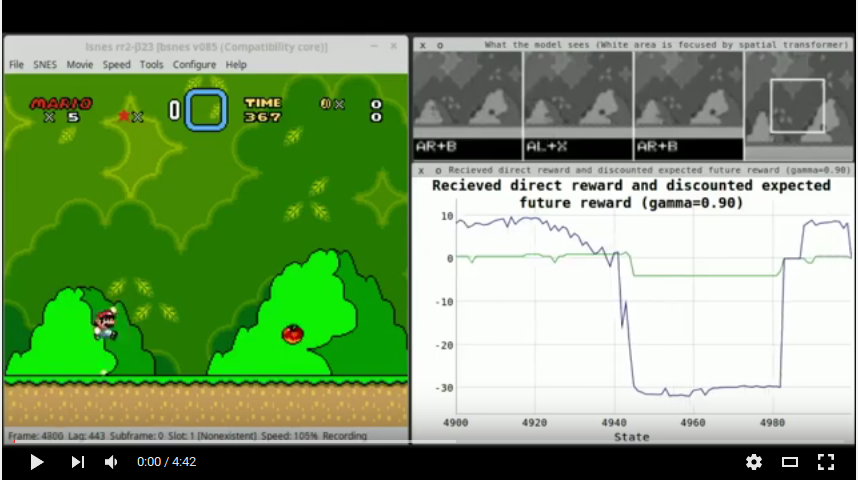
T está atualmente definido como 4 (observe que isso inclui o último estado da sequência). As telas são capturadas em cada 5º quadro. A saída de cada exemplo são os valores de recompensa de ação da ação escolhida (recompensa direta recebida + valor Q-com desconto do próximo estado). O modelo pode escolher duas ações por estado: um botão de seta (para cima, para baixo, direita, esquerda) e um dos outros botões de controle (A, B, X, Y). Isso é diferente do modelo Atari, no qual o agente só poderia escolher um botão de cada vez. (Sem essa mudança, o agente não poderia teoricamente não dar muitos saltos, o que o forçará a manter o botão A pressionado e se mover para a direita.) Como a função de recompensa é construída de tal maneira que quase nunca é 0, exatamente dois de Espera-se que os valores de saída de cada exemplo sejam diferentes de zero.
O agente recebe as seguintes recompensas:
+0.5 Se o agente se moveu para a direita, +1.0 se ele se movesse rapidamente para a direita (8 pixels ou mais em comparação com o último estado do jogo), -1.0 se ele se movesse para a esquerda e -1.5 se for moveu-se rapidamente para a esquerda (-8 pixels ou mais).+2.0 Enquanto a animação acabada de nível estiver jogando.-3.0 Enquanto a animação da morte está tocando. O gamma (desconto para recompensas esperadas/indiretas) está definido como 0.9 .
Treinar o modelo apenas em aumentos de pontuação (como no artigo Atari) provavelmente não funcionaria, porque os inimigos reaparecem quando o local de desova se move para fora da tela, para que o agente possa matá -los repetidamente, cada vez aumentando sua pontuação.
Um MSE seletivo é usado para treinar o agente. Ou seja, para cada exemplo, os gradientes são calculados como seriam para um MSE. No entanto, os gradientes de todos os valores de ação são definidos como 0 se a recompensa de destino foi 0. Isso é porque cada exemplo contém apenas a recompensa recebida por um par de botões escolhidos (botão de seta, outro botão). Outros pares de ações teriam sido possíveis, mas o agente não as escolheu e, portanto, a recompensa por eles não é clara. Seus valores de recompensa (por exemplo) são definidos como 0, mas não porque eram realmente 0, mas porque não sabemos o que recompensa o agente teria recebido se os tivesse escolhido. O gradiente de propagação retropacagante para eles (ou seja, se o agente prever um valor desigual para 0) não é razoável.
Essa implementação pode se dar ao luxo de diferenciar entre os botões escolhidos e não escolhidos (no vetor alvo) com base na recompensa desigual de 0, porque a recompensa recebida de um botão escolhido é (aqui) quase nunca exatamente 0 (devido à construção de a função de recompensa). Outras implementações podem precisar cuidar mais dessa etapa.
A política é um Epsilon-Greedy One, que começa em Epsilon = 0,8 e recoza isso para 0,1 na ação escolhida de 400k-th. Sempre que, de acordo com a política, uma ação aleatória deve ser escolhida, o agente lança uma moeda (ou seja, 50:50) e randomiza uma de suas duas (setas, outros botões) ações ou randomiza as duas.
O modelo é composto por três ramos:
No final dos ramos, tudo é mesclado a um vetor, alimentado através de uma camada oculta, antes de atingir os neurônios de saída. Esses neurônios de saída prevêem a recompensa esperada por botão pressionado.
Visão geral da rede:

O transformador espacial requer uma rede de localização, que é mostrada abaixo:

Ambas as redes têm em geral cerca de 6,6M parâmetros.
O agente é treinado apenas no primeiro nível (primeiro à direita no mundo acima no início). Outros níveis sofrem significativamente mais com várias dificuldades com as quais o agente dificilmente pode lidar. Alguns deles são:
O primeiro nível quase não tem essas dificuldades e, portanto, se presta ao DQN, e é por isso que é usado aqui. O treinamento em qualquer nível e depois testar em outro também é bastante difícil, porque cada nível parece introduzir coisas novas, como inimigos novos e bastante diferentes ou nova mecânica (escalada, novos itens, objetos que o espremem até a morte, etc.).
luarocks install packageName ): nn , cudnn , paths , image , display . A tela geralmente não faz parte da tocha.git clone https://github.com/qassemoquab/stnbhwd.gitcd stnbhwdluarocks make stnbhwd-scm-1.rockspecsudo apt-get install sqlite3 libsqlite3-devluarocks install lsqlite3source/src/libray/lua.cpp e insira o seguinte código em namespace { : #ifndef LUA_OK
#define LUA_OK 0
#endif
#ifdef LUA_ERRGCMM
REGISTER_LONG_CONSTANT("LUA_ERRGCMM", LUA_ERRGCMM, CONST_PERSISTENT | CONST_CS);
#endif
source/include/core/controller.hpp e altere a função do_button_action de privado para público. Basta cortar a linha void do_button_action(const std::string& name, short newstate, int mode); No private: Block e Cole -o no public: Block.source/src/lua/input.cpp e antes de lua::functions LUA_input_fns(... (no final do arquivo) inserir: int do_button_action(lua::state& L, lua::parameters& P)
{
auto& core = CORE();
std::string name;
short newstate;
int mode;
P(name, newstate, mode);
core.buttons->do_button_action(name, newstate, mode);
return 1;
}
core.lua2->input_controllerdata aparentemente nunca é definido (qual btw permitirá que essas funções falhem silenciosamente, ou seja, sem nenhum erro).source/src/lua/input.cpp , no bloco lua::functions LUA_input_fns(... , adicione do_button_action aos comandos da Lua que podem ser chamados dos scripts Lua carregados no emulador. Para fazer isso, mude a linha {"controller_info", controller_info}, para {"controller_info", controller_info}, {"do_button_action", do_button_action}, .source/ .make .options.build .libwxgtk3.0-dev e não a versão 2.8-DEV, como a página oficial desse pacote pode dizer para você fazer.source/ execute sudo cp lsnes /usr/bin/ && sudo chown root:root /usr/bin/lsnes . Depois disso, você pode iniciar o LSNES simplesmente digitando lsnes em uma janela do console.sudo mkdir /media/ramdisksudo chmod 777 /media/ramdisksudo mount -t tmpfs -o size=128M none /media/ramdisk && mkdir /media/ramdisk/mario-ai-screenshotsSCREENSHOT_FILEPATH em config.lua .git clone https://github.com/aleju/mario-ai.git .cd no diretório criado.lsnes em uma janela de terminal.Configure -> Settings -> Advanced e defina o limite de memória Lua como 1024 MB. (Só deve ser feito uma vez.)Configure -> Settings -> Controller ). Jogue até o mundo do mundo aparecer. Lá, vá para a direita e inicie esse nível. Jogue esse nível um pouco e salve um punhado ou mais dos estados através do File -> Save -> State nos states/train do subdiretório. O nome não importa, mas eles precisam terminar em .lsmv . (Tente espalhar os estados por todo o nível.)th -ldisplay.start . Se isso não funcionar, você ainda não instalou o visor, use luarocks install display .http://localhost:8000/ no seu navegador.Tools -> Run Lua script... e selecione train.lua .Tools -> Reset Lua VM .learned/ . Observe que você pode manter a memória de reprodução ( memory.sqlite ) e treinar uma nova rede com ela. Você pode testar o modelo usando test.lua . Não espere que isso jogue incrivelmente bem. O agente ainda morrerá muito, ainda mais se você terminou o treinamento em um conjunto ruim de parâmetros.


