Controlador de mão-de-obra
Construímos um controlador para o modelo de mão-de-obra no ambiente Mujoco, usando aprendizado profundo e aprendizado de reforço profundo. O controlador permite que a mão execute gestos em linguagem de sinais. Os gestos suportados desta mão são:
- Descansar
- Derrubar
- Dedo médio
- Sim
- Não
- Pedra
- Círculo
Demonstração Shadow-Hand: https://youtu.be/vt_booel3fu
Descrição da mão das sombras

Shadow-Hand é uma mão robótica 3D fornecida pelo repositório mujoco_menagerie , para fins acadêmicos e de pesquisa. Pode ser encontrado aqui: https://github.com/deepmind/mujoco_menagerie/tree/main/shadow_hand
Como funciona
A Hand-Hand usa 20 motores posicionais como atuadores para permitir o movimento nos dedos e no pulso. Seu atuador possui uma faixa de controle limitada definida pelo fabricante. As posições de cada atuador podem ser encontradas baixando o simulador mujoco e importando o arquivo XML da manobra (localizado em Objecs/Shadow_Hand/Scene_Left.xml ) no simulador via Drag & Drop . Para visualizar a posição e a orientação de cada atuador, a opção de juntas deve ser ativada dentro da janela de simulação, que pode ser encontrada no painel de renderização/elemento do modelo. Ao todo, eles são descritos analiticamente dentro do arquivo XML.
A posição e a faixa de controle de cada atuador da mão são fornecidas abaixo:
| eu ia | ctrl_limit_left | Ctrl_limit_right |
|---|
| 0 | -0.523599 | 0,174533 |
| 1 | -0.698132 | 0,488692 |
| 2 | -1.0472 | 1.0472 |
| 3 | 0 | 1.22173 |
| 4 | -0.20944 | 0.20944 |
| 5 | -0.698132 | 0,698132 |
| 6 | -0.261799 | 1.5708 |
| 7 | -0.349066 | 0,349066 |
| 8 | -0.261799 | 1.5708 |
| 9 | 0 | 3.1415 |
| 10 | -0.349066 | 0,349066 |
| 11 | -0.261799 | 1.5708 |
| 12 | 0 | 3.1415 |
| 13 | -0.349066 | 0,349066 |
| 14 | -0.261799 | 1.5708 |
| 15 | 0 | 3.1415 |
| 16 | 0 | 0,785398 |
| 17 | -0.349066 | 0,349066 |
| 18 | -0.261799 | 1.5708 |
| 19 | 0 | 3.1415 |

Clonagem comportamental
A clonagem comportamental (BC) é um método de ensino de controladores para executar tarefas observando e imitando especialistas em humanos. É uma técnica particularmente comum na robótica, onde um modelo aprende a executar tarefas imitando os seres humanos. Este método envolve:
- Coleta de dados : um especialista humano deve construir um conjunto de dados, que consiste em pares: (observações, ações) .
- Algoritmo de aprendizado : um algoritmo de aprendizado (por exemplo, uma rede neural) é projetada para mapear as observações (entradas) para ações esperadas (saídas).
- Implantação : o controlador é então avaliado e implantado no modelo físico.
Aprendizagem de reforço profundo
O aprendizado de reforço profundo (DRL) é outra técnica popular para as máquinas de ensino de executar tarefas de maneira ideal, mas difere da clonagem comportamental. Embora a clonagem comportamental aprenda diretamente com exemplos (demonstrações) do comportamento desejado, o DRL aprende através da interação com um ambiente e recebendo feedback na forma de recompensas ou penalidades. Nos ambientes DRL, um agente recebe seu estado $ s_ {t} $ Do meio ambiente, escolhe uma ação $ a_ {t} $ usando sua política $ pi _ { theta} $ , então transita para o próximo estado $ s_ {t+1} $ e finalmente recebe uma recompensa $ r_ {t+1} $ Com base em como a ação era boa. O objetivo do agente é maximizar os retornos cumulativos $ r = r_ {t + 1} + r_ {t + 2} + r_ {t + 3} + ... $.
Existem duas famílias populares de algoritmos que são usados em problemas de DRL:
- Métodos baseados em valor : Esses métodos visam encontrar uma função de valor, que é uma medida da recompensa cumulativa esperada que um agente pode obter de qualquer estado (ou par de ação estatal). A função de valor mais comum é a função Q, q (s, a), que mede o retorno esperado de tomar medidas $ a_ {t} $ em um estado $ s_ {t} $ . Outra maneira de medir o retorno esperado é através do uso de $ V (s) $ , que mede o quão bom é um estado $ s_ {t} $ . Às vezes, essas duas funções são combinadas para acelerar o processo de treinamento e o desempenho do aprendizado do agente. Ao estimar a função de valor corretamente, o agente pode fazer uma transição ideal entre estados consecutivos e, assim, aprender um comportamento ideal. As funções Q-função e de valor podem ser estimadas usando uma rede neural, conforme mostrado abaixo.
- Métodos de gradiente de políticas : em vez de calcular os retornos estimados, os métodos de gradiente de políticas otimizam diretamente a função da política sem a necessidade de uma função de valor como intermediário. A política é tipicamente parametrizada por um conjunto de pesos (por exemplo, uma rede neural), e o aprendizado envolve ajustar esses pesos para maximizar a recompensa esperada. A idéia é que, alterando os pesos de uma rede neural e, assim, alterando as ações selecionadas, também altera as recompensas que o agente recebe pelo meio ambiente. O objetivo do agente é alterar sua política (seus pesos) na diretora que maximiza suas recompensas, como mostrado abaixo. Uma das principais vantagens dos métodos de gradiente de políticas sobre os métodos baseados em valor é que eles permitem o uso de ações contínuas (por exemplo, valores de flutuação), em vez de ações discretas (por exemplo, 1,2,3). Isso é especificamente útil em ambientes mujoco, como o nosso, onde o objetivo é prever o controle (valores de flutuação) de cada atuador.
Observações (entradas)
A técnica de clonagem comportamental e DRL requerem um conjunto de dados ou um ambiente de simulação para recuperar os dados. Para treinar os dois agentes, construímos um conjunto de dados que consiste em pares $ (Sinal, ordem) -& gt; (Controle) $ .
- Sinal: o sinal é um conjunto de controles seqüenciais, que o controlador da mão deve executar, para executar um gesto de sinal. Por exemplo, para executar um gesto "sim", a mão deve primeiro fazer um punho (1), depois mover a mão para baixo (2) e depois para cima novamente (3).
- Ordem: Ordem é o índice do controle desejado dentro da sequência. Isso é necessário, porque o agente deve executar todos os controles sequencialmente, em uma ordem especificada. Por exemplo, no exemplo "sim", os controles (1), (2), (3) devem ser executados consecutivamente.
- Controle: o controle é um vetor (matriz) de 20 valores, um para cada atuador. Cada valor é um número de flutuação que controla a posição do atuador e não excede seus limites de controle descreveu a tabela acima.
Representação de sinal/pedido
A rede neural recebe um vetor de entrada e produz o vetor de controle. Embora o vetor de entrada deva ser um vetor de valores de flutuação, nosso conjunto de dados contém sinais, que são strings (palavras) e ordens, que são números inteiros. Como o conjunto de dados é muito pequeno, convertemos cada palavra e ordem para um vetor único, como mostrado abaixo:
| sinal | vetor |
|---|
| descansar | [0,0,0,0,0,0,1] |
| derrubar | [0,0,0,0,0,1,0] |
| dedo médio | [0,0,0,0,1,0,0] |
| sim | [0,0,0,1,0,0,0] |
| não | [0,0,1,0,0,0,0] |
| pedra | [0,1,0,0,0,0,0] |
| círculo | [1,0,0,0,0,0,0] |
| ordem | vetor |
|---|
| 1 | [0,0,1] |
| 2 | [0,1,0] |
| 3 | [1,0,0] |
Agora, esses recursos podem ser concatenados e inseridos no controlador de rede neural/agente DRL.
Rede Neural (BC)
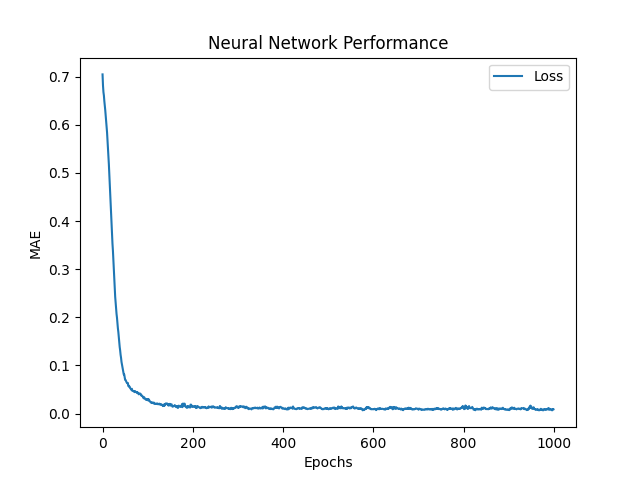
O objetivo da rede neural é prever os valores de controle dos 20 atuadores: $ hat {y_ {0}}, hat {y_ {1}}, hat {y_ {2}}, hat {y_ {3}}, ..., hat {y_ {19}} $ , usando o sinal, o par de pedidos como entrada. Para fazer isso, a rede gera uma previsão de controle e usa a função média de erro absoluto (MAE) para avaliar seu erro de previsão. Em seguida, a rede usa o Adam Optimizer, que é uma melhoria do algoritmo de descida de gradiente , para atualizar seus pesos e reduzir o MAE. Se $ y $ e $ hat {y} $ são o controle do alvo (real) e previsto, respectivamente, o MAE é definido como:
$ frac {1} {n} * sum_ {i = 1}^{n} | y_i - hat {y_i} | $
Otimização de política proximal (DRL)
A otimização de políticas proximais (PPO) é um algoitmo popular de gradiente de políticas que aborda alguns desafios na estabilidade e eficiência do treinamento enfrentadas pela otimização da política da região de confiança (TRPO). O PPO apresenta um mecanismo de recorte para impedir que a política seja atualizada drasticamente em uma única etapa (impede que os pesos recebam grandes atualizações e mudem drasticamente), garantindo que a nova política não se desvie muito do antigo. Ao usar a política, em vez de maximizar diretamente a recompensa esperada, o PPO visa maximizar uma versão cortada da função objetivo. Esse objetivo preso limita a proporção das probabilidades das políticas novas e antigas. Especificamente, se a nova política aumentaria significativamente a probabilidade da ação em comparação com a política antiga, essa alteração será cortada para estar dentro de um intervalo especificado (por exemplo, entre 0,8 e 1,2). Isso impede atualizações excessivamente agressivas que possam convergir rapidamente em políticas sub-ideais. Este intervalo é definido por um parâmetro de recorte $ e $ , que normalmente está definido entre $ [0,1, 0,3] $ .
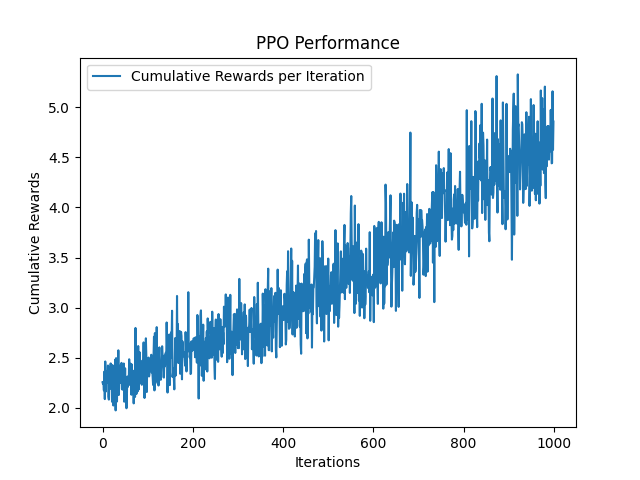
Assim como a rede neural do BC, o PPO recebe pares de (sinal, ordem) como entradas e emite o controle de destino da mão. Em seguida, em vez de usar uma função de perda (erro) para avaliar seu erro, ele usa uma função de recompensa para receber recompensas, que tenta maximizar em cada iteração. A função de recompensa $ R $ é definido como $ R_ {t} = frac {1} {euclidean (y_ {t} - hat {y_ {t}})} $ , onde euclidiano é a distância euclidiana entre o controle previsto e o alvo.
Versão Python e bibliotecas
- python == 3.9 https://www.python.org/downloads/release/python-390/
- Mujoco = 2.3.7 https://github.com/deepmind/mujoco
- tensorflow == 2.9.1 https://www.tensorflow.org/install
- ray [rllib] == 2.3.1 https://docs.ray.io/en/latest/rllib/index.html
- ginásio == 0.26.1 https://gymnasium.farama.org/
- matplotlib == 3.7.2 https://matplotlib.org/
Como correr
- python generate_expert_dataset.py para criar um conjunto de dados. A mão pode alternar os gestos usando botões-chave (1-7). O mouse pode ser usado para navegar pelo mundo da simulação
- Python Train_NN.py para treinar e avaliar a rede neural
- Python Train_Ppo.py para treinar e avaliar o agente de PPO
- python simulate_neural_network_controller.py para implantar e avaliar o controlador baseado em rede neural
- python simulate_neural_network_controller.py para implantar e avaliar o controlador baseado em PPO
Parâmetros Explicação
- trajetória_steps : o número de controles intermidados para executar entre dois controles consecutivos (por exemplo, se
start_ctrl = [1,1,1], end_ctrl = [2,2,2] and trajectory_steps=5 , então a mão executa 2 + 3 controlos entre [[ 1,1,1] e [2,2,2]. - CAM_VERBOSE : imprime a posição da câmera no terminal (isso ajuda a ajustar inicialmente a posição e a orientação da câmera).
- Sim_verbose : imprime os controles de cada atuador em cada timestep.
- One_hot_signs : seja para sinais e ordens de um hots. Se false, sinais e pedidos serão devolvidos como cordas e números inteiros, respectivamente. No entanto, tanto a rede neural quanto o agente DRL terão que ser modificados para permitir o uso de strings como entrada. Uma maneira de fazer isso é adicionar uma camada de incorporação (https://www.tensorflow.org/text/guide/word_embeddings). Isso pode ser útil nos casos em que o número de gestos, bem como os tamanhos de sequência dos sinais são extremamente grandes, portanto, o método de codificação em um hot não pode ser usado.
- Learning_rate : a taxa de alerta da rede neural. Isso reduz as atualizações da rede, garantindo que a rede converja lentamente para o mínimo local. 0,001 é um bom valor típico
- Epochs : o número de épocas para treinar a rede (número de vezes que o conjunto de dados será alimentado à rede). Padrões para 1000.
- LEST_FN : A função de perda da rede neural. Padrões para "mae".
- TRAIN_ITERATION : o número de iterações que o agente será treinado. Padrões para 1000.
- Semente : a semente aleatória, que é usada para gerar números aleatórios. Isso permite que os experimentos sejam reproduzidos. Padrões para 0.
Controlador personalizado
Um controlador de modelo personalizado pode ser fornecido na classe GLFWSimulator para controlar os atuadores da Hand (verifique os exemplos simulados_neural_network_controller.py e simulate_neural_network_controller.py ). A linha a seguir pode ser modificada
hand_controller = Controller(
model=agent,
ctrl_limits=ctrl_limits
)
para que o agente seja substituído por um agente personalizado. O agente (ou modelo) deve herdar a Controller class , encontrada no arquivo controladores/controller.py e definir os seguintes métodos:
-
def _set_sign(self, sign: str) : define o comportamento do controlador para o sinal especificado -
def _get_next_control(self, sign: str, order: int) : obtém o próximo controle do sinal especificado (por exemplo, se um sinal for definido como 10 controles seqüenciais, get_next_control deve retornar o próximo controle previsto dessa sequência (check model.py.py arquivo).
Ambiente de simulação
O ambiente de simulação é escrito usando a biblioteca GLFW, que é fornecida pelo Mujoco. Ele pode ser facilmente modificado modificando o loop while do arquivo simulaton/pyopengl.py .
Rede neural personalizada
A rede neural é incorporada em modelos/tf/nn.py usando a biblioteca TensorFlow. Uma rede neural personalizada pode ser construída estendendo o método de construção da NeuralNetwork class . As arquiteturas atuais usam 2 camadas de 128 unidades para cada vetor de entrada (128 para vetor de sinal e 128 para o vetor de ordem) e a função de ativação do RelU em cada camada. Em seguida, as duas camadas são concatenadas em um vetor de 256 unidades, que é seguido por outra camada de 128 neurônios e, finalmente, 20 unidades de saída. As 20 unidades finais são usadas para definir os controles do atuador.
Agente personalizado
Este repositório usa o agente PPO do rllib. No entanto, várias coisas podem ser adicionadas:
- Tune fino (pesquise melhores parâmetros para PPO). Atualmente, o Algorith usa os parâmetros padrão do PPO, conforme descrito por John Schulman et. AL no artigo original https://arxiv.org/abs/1707.06347
- Adicione um algoritmo de aprendizado mais forte: por exemplo , ator soft-crítico, conhecido como SAC é conhecido por ter um desempenho muito forte em ambientes mujoco: https://arxiv.org/pdf/1801.01290.pdf
- Aumente as iterações de treinamento: Nos modelos pré-treinados fornecidos nesta biblioteca, tanto a rede neural quanto o agente PPO foram treinados para 1000 iterações. Embora a rede neural tenha convergido para um pequeno erro, o PPO requer mais iterações de treinamento para convergir. Essa é a razão pela qual o controlador da PPO parece ter um comportamento estranho.
- Adicione uma rede neural personalizada como o modelo ator-crítico. Esta é uma tarefa muito difícil de alcançar, no entanto, também criamos um repositório para esse fim: https://github.com/kochlisgit/deep-rl-frameworks


