awesome RLHF
1.0.0
Esta é uma coleção de trabalhos de pesquisa para aprendizado de reforço com feedback humano (RLHF). E o repositório será atualizado continuamente para rastrear a fronteira do RLHF.
Bem -vindo a seguir e estrelar!
RLHF incrível (RL com feedback humano)
2024
2023
2022
2021
2020 e antes
Explicação detalhada
Índice
Visão geral do RLHF
Papéis
Bases de código
Conjunto de dados
Blogs
Outro suporte de linguagem
Contribuindo
Licença
A idéia do RLHF é usar os métodos do Aprendizagem de reforço para otimizar diretamente um modelo de idioma com feedback humano. O RLHF permitiu que os modelos de idiomas comecem a alinhar um modelo treinado em um corpus geral de dados de texto aos de valores humanos complexos.
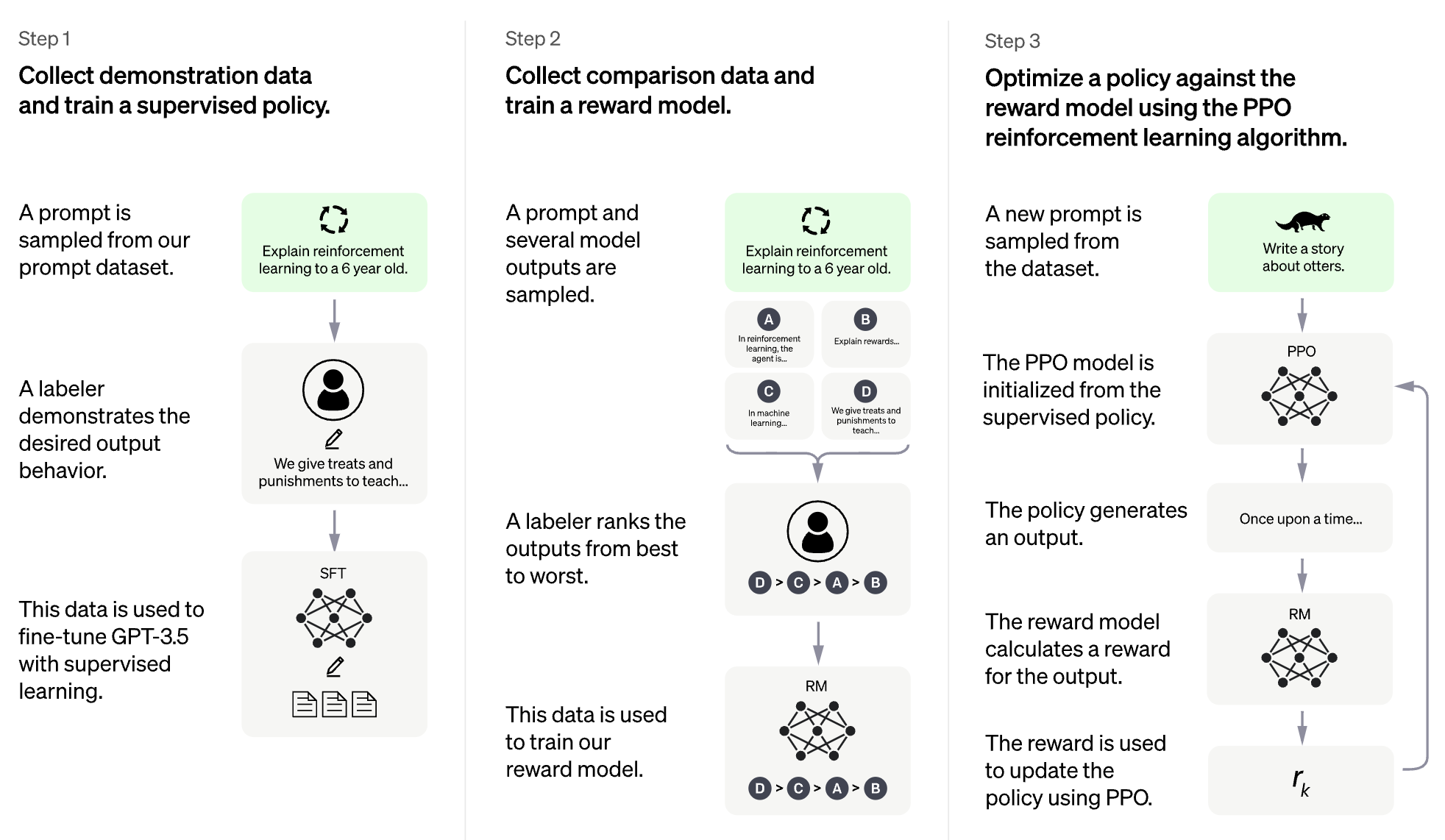
RLHF para Modelo de Linguagem Grande (LLM)
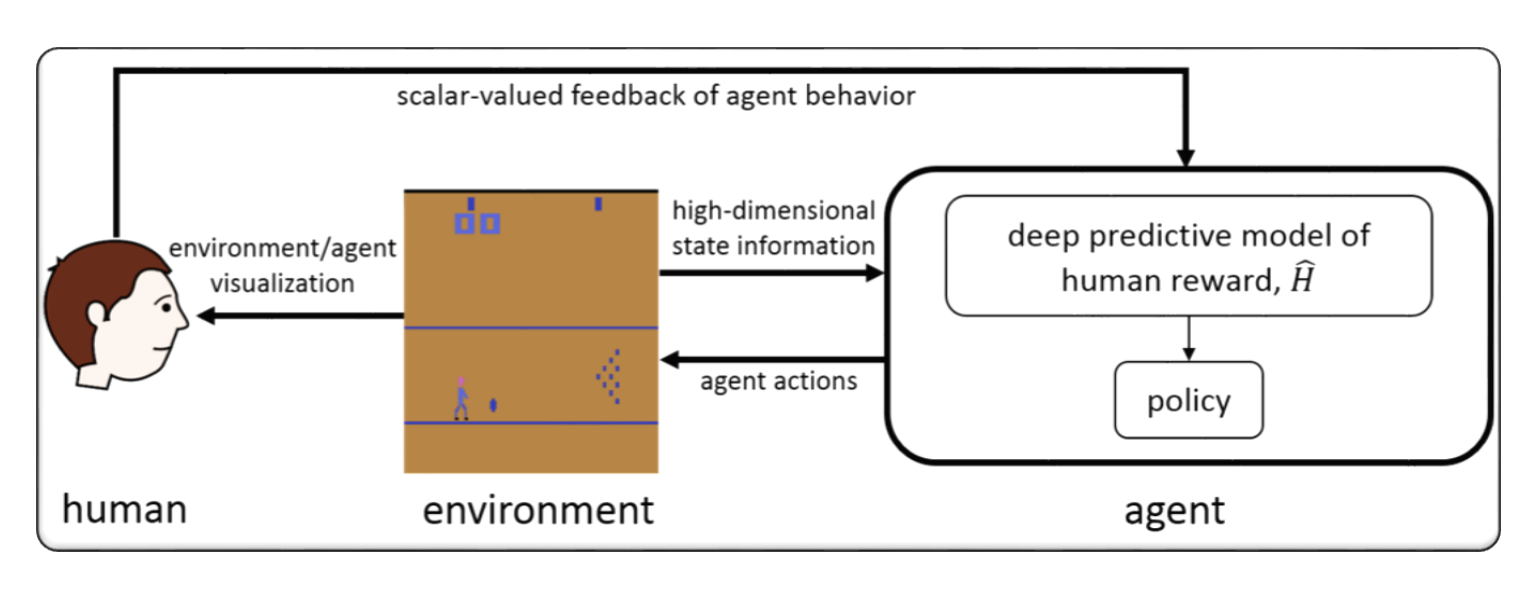
RLHF para videogame (por exemplo, Atari)
(A seção a seguir foi gerada automaticamente pelo ChatGPT)
O RLHF normalmente se refere ao "aprendizado de reforço com feedback humano". A aprendizagem de reforço (RL) é um tipo de aprendizado de máquina que envolve o treinamento de um agente para tomar decisões com base no feedback de seu ambiente. No RLHF, o agente também recebe feedback de humanos na forma de classificações ou avaliações de suas ações, o que pode ajudá -lo a aprender com mais rapidez e precisão.
O RLHF é uma área de pesquisa ativa em inteligência artificial, com aplicações em áreas como robótica, jogos e sistemas de recomendação personalizados. Ele procura enfrentar os desafios da RL em cenários em que o agente tem acesso limitado ao feedback do ambiente e requer informações humanas para melhorar seu desempenho.
A aprendizagem de reforço com feedback humano (RLHF) é uma área de pesquisa em rápido desenvolvimento em inteligência artificial, e existem várias técnicas avançadas que foram desenvolvidas para melhorar o desempenho dos sistemas RLHF. Aqui estão alguns exemplos:
Inverse Reinforcement Learning (IRL) : IRL é uma técnica que permite ao agente aprender uma função de recompensa com o feedback humano, em vez de depender de funções de recompensa predefinidas. Isso torna possível para o agente aprender com sinais de feedback mais complexos, como demonstrações de comportamento desejado.
Apprenticeship Learning : Aprendizagem de aprendizagem é uma técnica que combina o IRL com o aprendizado supervisionado para permitir que o agente aprenda com o feedback humano e as demonstrações de especialistas. Isso pode ajudar o agente a aprender de maneira mais rápida e eficaz, pois é capaz de aprender com feedback positivo e negativo.
Interactive Machine Learning (IML) : IML é uma técnica que envolve interação ativa entre o agente e o especialista humano, permitindo que o especialista forneça feedback sobre as ações do agente em tempo real. Isso pode ajudar o agente a aprender com mais rapidez e eficiência, pois pode receber feedback sobre suas ações em cada etapa do processo de aprendizado.
Human-in-the-Loop Reinforcement Learning (HITLRL) : Hitlrl é uma técnica que envolve integrar o feedback humano ao processo de RL em vários níveis, como modelagem de recompensa, seleção de ação e otimização de políticas. Isso pode ajudar a melhorar a eficiência e a eficácia do sistema RLHF, aproveitando os pontos fortes de humanos e máquinas.
Aqui estão alguns exemplos de aprendizado de reforço com feedback humano (RLHF):
Game Playing : No jogo, o feedback humano pode ajudar o agente a aprender estratégias e táticas que são eficazes em diferentes cenários de jogos. Por exemplo, no jogo popular do GO, os especialistas humanos podem fornecer feedback ao agente em seus movimentos, ajudando-o a melhorar sua jogabilidade e tomada de decisão.
Personalized Recommendation Systems : em sistemas de recomendação, o feedback humano pode ajudar o agente a aprender as preferências de usuários individuais, possibilitando fornecer recomendações personalizadas. Por exemplo, o agente pode usar o feedback dos usuários sobre produtos recomendados para saber quais recursos são mais importantes para eles.
Robotics : Na robótica, o feedback humano pode ajudar o agente a aprender a interagir com o ambiente físico de maneira segura e eficiente. Por exemplo, um robô poderia aprender a navegar em um novo ambiente mais rapidamente com o feedback de um operador humano no melhor caminho a seguir ou quais objetos evitar.
Education : Na educação, o feedback humano pode ajudar o agente a aprender a ensinar os alunos com mais eficiência. Por exemplo, um tutor baseado em IA pode usar o feedback dos professores sobre quais estratégias de ensino funcionam melhor com diferentes alunos, ajudando a personalizar a experiência de aprendizado.
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
HybridFlow: uma estrutura RLHF flexível e eficiente
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Palavra -chave: estrutura flexível, eficiente, RLHF
Código: Oficial
Alarme: alinhar modelos de linguagem por meio de modelagem hierárquica de recompensas
Yuhang Lai, Siyuan Wang, Shujun Liu, Xuanjing Huang, Zhongyu Wei
Palavra -chave: recompensa hierárquica, tarefas de geração de texto aberto
Código: Oficial
TLCR: Recompensa contínua no nível do token pelo aprendizado de reforço de granulação fina com o feedback humano
Eunseoop Yoon, Hee Suk Yoon, Soohwan Eom, Gunsoo Han, Daniel Wontae Nam, Daejin Jo, Kyoung-Woon ON, Mark A. Hasegawa-Johnson, Sungwoong Kim, Chang D. Yoo
Palavra-chave: recompensa contínua no nível do token, rlHF
Código: Oficial
Alinhando grandes modelos multimodais com RLHF aumentado de fato
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, Trevor Darrell
Palavra -chave: RLHF, visão e idioma aumentados de fato, conjunto de dados de preferência humana
Código: Oficial
Alinhamento de modelo de linguagem grande direta por meio de destilação imediata contrastiva de auto-recompensa
Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, Lijie Wen
Palavra-chave: sem dados de preferência humana, auto-recompensa, DPO
Código: Oficial
Controle aritmético de LLMs para diversas preferências do usuário: alinhamento de preferência direcional com recompensas multi-objetivas
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, Tong Zhang
Palavra-chave: preferência do usuário, modelo de recompensa multi-objetiva, amostragem de rejeição Finetuning
Código: Oficial
Voltar ao básico: revisitando a otimização de estilo de reforço para aprender com o feedback humano no LLMS
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet üstün, Sara Hooker
Palavra -chave: otimização online de RL, baixo custo computacional
Código: Oficial
Melhorando os grandes modelos de linguagem por meio de aprendizado de reforço de granulação fina com restrição de edição mínima
Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, Ji-Rong Wen
Palavra-chave: recompensa de nível de token, LLM
Código: Oficial
RLAIF vs. RLHF: Escalando o aprendizado de reforço com o feedback humano com feedback da IA
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, Sushant Prakash
Palavra -chave: RL do feedback da IA
Código: Oficial
Métodos baseados em penalidades de princípios para aprendizado de reforço de Bilevel e RLHF
Han Shen, Zhuoran Yang, Tianyi Chen
Palavra -chave: otimização do bilevel
Código: Oficial
Recompensa densa de graça no aprendizado de reforço com o feedback humano
Alex James Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Palavra -chave: Moldura de recompensa, RLHF
Código: Oficial
Uma abordagem minimalista para reforçar o aprendizado do feedback humano
Gokul Swamy, Christoph Dann, Rahul Kidambi, Steven Wu, Alekh Agarwal
Palavra-chave: Minimax Winner, Otimização de preferência de auto-jogo
Código: Oficial
RLHF-V: em direção a MLLMs confiáveis por meio de alinhamento de comportamento de feedback humano correcional de granulação fina
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua
Palavra -chave: modelos de linguagem grande multimodal, problema de alucinação, aprendizado de reforço com feedback humano
Código: Oficial
RLHF Fluxo de trabalho: da modelagem de recompensa ao RLHF online
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
Palavra -chave: RLHF iterativo online, modelagem de preferências, modelos de idiomas grandes
Código: Oficial
Maxmin-rlHf: Rumo ao alinhamento equitativo de grandes modelos de linguagem com diversas preferências humanas
Souadip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Singh Bedi, Mengdi Wang
Palavra -chave: mistura de distribuições de preferência, objetivo do alinhamento maxmin
Código: Oficial
Otimização da política de redefinição do conjunto de dados para RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kianté Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
Palavra -chave: otimização da política de redefinição do conjunto de dados
Código: Oficial
Uma visão densa de recompensa sobre o alinhamento da difusão de texto à imagem com a preferência
Shentao Yang, Tianqi Chen, Mingyuan Zhou
Palavra-chave: RLHF para geração de texto para imagem, melhoria de recompensa densa do DPO, alinhamento eficiente
Código: Oficial
Ajuste de auto-jogo converte modelos de linguagem fracos em modelos de linguagem fortes
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan Gu
Palavra-chave: ajuste fino de auto-jogo
Código: Oficial
RLHF decifrado: uma análise crítica do aprendizado de reforço com o feedback humano para o LLMS
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
Palavra -chave: RLHF, recompensa oracular, análise de modelo de recompensa, pesquisa
Confrontando a otimização da recompensa para modelos de difusão: uma perspectiva de preconceitos indutivos e de primazia
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
Palavra -chave: modelos de difusão, alinhamento, aprendizado de reforço, RLHF, otimização de recompensa, viés de primazia
Código: Oficial
Sobre preferências diversificadas de grande alinhamento do modelo de linguagem
Dun Zeng, Yong Dai, Pengyu Cheng, Tianhao Hu, Wanshun Chen, Nan Du, Zenglin Xu
Palavra -chave: alinhando a preferência compartilhada, métricas de modelagem de recompensa, LLM
Código: Oficial
Alinhando o feedback da multidão por meio de modelagem de recompensa de preferência distributiva
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, arruinando Tang, Yong Liu
Palavra -chave: RLHF, Distribuição de Preferências, Alinhamento, LLM
Além de um alinhamento de uma preferência: otimização de preferência direta multi-objetiva
ZanHui Zhou, Jie Liu, Chao Yang, Jing Shao, Yu Liu, Xiangyu Yue, Wanli Ouyang, Yu Qiao
Palavra-chave: RLHF multi-objetiva sem modelagem de recompensa, DPO
Código: Oficial
Desalinhamento emulado: o alinhamento de segurança para grandes modelos de idiomas pode sair pela culatra!
ZanHui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
Palavra-chave: ataque de tempo de inferência LLM, DPO, produzindo LLMs prejudiciais sem treinamento
Código: Oficial
Uma análise teórica do aprendizado de Nash com o feedback humano sob a preferência general de KL regulada
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
Palavra-chave: RLHF baseado em jogos, aprendizado de Nash, alinhamento sob o Oracle sem modelos de recompensa
Mitigando o imposto de alinhamento do RLHF
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie Pi, Han Zhao, Nan Jiang, Heng Ji, Yuan Yao, Tong Zhang
Palavra -chave: RLHF, imposto sobre alinhamento, esquecimento catastrófico
Modelos de difusão de treinamento com aprendizado de reforço
Kevin Black, Michael Janner, Yilun du, Ilya Kostrikov, Sergey Levine
Palavra -chave: aprendizado de reforço, RLHF, modelos de difusão
Código: Oficial
Aligndiff: alinhando diversas preferências humanas por meio do Modelo de Difusão Customisível de Comportamento
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
Palavra -chave: aprendizado de reforço; Modelos de difusão; RlHf; Alinhamento de preferência
Código: Oficial
Recompensa densa de graça no aprendizado de reforço com o feedback humano
Alex J. Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Palavra -chave: RLHF
Código: Oficial
Transformando e combinando recompensas para alinhar grandes modelos de linguagem
Zihao Wang, Chirag Nagpal, Jonathan Berant, Jacob Eisenstein, Alex D'Amour, Sanmi Koyejo, Victor Veitch
Palavra -chave: RLHF, Alinhing, LLM
Aprendizagem de reforço eficiente do parâmetro com feedback humano
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christiane Ahlheim, Yonghao Zhu, Bowen Li, Saravanan Ganesh, Bill Byrne, Jessica Hoffmann, Hassan Mansoor, Wei Li , Abhinav Rastogi, Lucas Dixon
Palavras -chave: RLHF, Método eficiente do parâmetro, baixo custo computacional, LLM, VLM
Melhorando o aprendizado de reforço com o feedback humano com um conjunto de modelos de recompensa eficiente
Shun Zhang, Zhenfang Chen, Sunli Chen, Yikang Shen, Zhiqing Sun, Chuang Gan
Palavras -chave: RLHF, Ensemble de recompensa, método eficiente de conjunto
Um paradigma teórico geral para entender o aprendizado das preferências humanas
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, Rémi Munos
Palavras -chave: RLHF, preferência em pares
O feedback humano de granulação fina oferece melhores recompensas para o treinamento de modelos de idiomas
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
Palavra-chave: RLHF, recompensa no nível da sentença, LLM
Código: Oficial
Orientação em nível de token em aterramento de preferência para o modelo de ajuste do modelo de idioma
Shentao Yang, Shujian Zhang, Congying Xia, Yihao Feng, Caiming Xiong, Mingyuan Zhou
Palavra-chave: RLHF, orientação de treinamento em nível de token, estrutura de treinamento alternativa/online, objetivos de treinamento minimalista
Código: Oficial
Recompensas fantásticas e como domesticá-las: um estudo de caso sobre aprendizado de recompensa para sistemas de diálogo orientados a tarefas
Yihao Feng*, Shentao Yang*, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, Huan Wang
Palavra-chave: RLHF, Aprendizagem da Função de Recompensa genralizada, Utilização de funções de recompensa, sistema de diálogo orientado a tarefas, Sistema de Diálogo, Aprendizagem para Rank
Código: Oficial
Aprendizagem de preferência inversa: RL baseado em preferências sem uma função de recompensa
Joey Hejna, Dorsa Sadigh
Palavra -chave: aprendizado de preferência inversa, sem modelo de recompensa
Código: Oficial
ALPACAFARM: Uma estrutura de simulação para métodos que aprendem com o feedback humano
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy BA, Carlos Guestrin, Percy S. Liang, Tatsunori B. Hashimoto
Palavra -chave: RLHF, estrutura de simulação
Código: Oficial
Otimização de classificação de preferência para alinhamento humano
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, Houfeng Wang
Palavra -chave: otimização de classificação de preferência
Código: Oficial
Otimização de preferência adversária
Pengyu Cheng, Yifan Yang, Jian Li, Yong Dai, Nan Du
Palavra -chave: RLHF, GaN, jogos adversários
Código: Oficial
Aprendizagem de preferência iterativa com o feedback humano: teoria e prática de ponte para o RLHF sob a restrição de KL
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
Palavra -chave: RLHF, DPO iterativo, Fundação Matemática
Amostra um aprendizado eficiente de reforço com o feedback humano via exploração ativa
Viraj Mehta, Vikramjeet Das, Ojash Nepane, Yijia Dai, Ilija Bogunovic, Jeff Schneider, Willie Neiswanger
Palavra -chave: RLHF, eficácia da amostra, exploração
Aprendizagem de reforço com feedback estatístico: a jornada do teste AB para o teste de formigas
Feiyang Han, Yimin Wei, Zhaofeng Liu, Yanxing Qi
Palavra -chave: RLHF, AB Testing, RLSF
Uma análise de linha de base da capacidade dos modelos de recompensa de analisar com precisão os modelos de fundação em mudança de distribuição
Ben Pikus, Will Levine, Tony Chen, Sean Hendryx
Palavra -chave: RLHF, Ood, mudança de distribuição
Alinhamento com eficiência de dados de grandes modelos de linguagem com feedback humano através da linguagem natural
Di Jin, Shikib Mehri, Devamanyu Hazarika, Aishwarya Padmakumar, Sungjin Lee, Yang Liu, Mahdi Namazifar
Palavra-chave: RLHF, eficiente de dados, alinhamento
Vamos reforçar passo a passo
Sarah Pan, Vladislav Lialin, Sherin Muckatira, Anna Rumshisky
Palavra -chave: RLHF, raciocínio
Otimização de políticas baseadas em preferências diretas sem modelagem de recompensa
Gaon An, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-Min Kim, Hyun Oh Song
Palavra -chave: RLHF sem modelagem de recompensa, aprendizado contrastivo, aprendizado offline de refinforamento
Aligndiff: alinhando diversas preferências humanas por meio do Modelo de Difusão Customisível de Comportamento
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
Palavra -chave: RLHF, alinhamento, modelo de difusão
Eureka: design de recompensa em nível humano através de codificação de grandes modelos de linguagem
Yecheng Jason MA, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, fã de Linxi, Anima Anandkumar
Palavra -chave: LLM Baseado, Design de funções de recompensa
RLHF seguro: aprendizado seguro de reforço com feedback humano
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
Palavra-chave: Sale RL, LLM Fine-Ture
Diversidade de qualidade através do feedback humano
Li Ding, Jenny Zhang, Jeff Clune, Lee Spector, Joel Lehman
Palavra -chave: diversidade de qualidade, modelo de difusão
Remax: um método de aprendizado de reforço simples, eficaz e eficiente para alinhar modelos de linguagem grandes
Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
Palavra-chave: eficiência computacional, técnica de redução de variância
Ajustando modelos de visão computacional com recompensas de tarefas
André Susano Pinto, Alexander Kolesnikov, Yuge Shi, Lucas Beyer, Xiaohua Zhai
Palavra -chave: Ajuste da recompensa na visão computacional
A sabedoria da retrospectiva faz dos modelos de idiomas melhores seguidores de instruções
Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, Joseph E. Gonzalez
Palavra -chave: Relabeling para Instrução Hindsight, sistema RLHF, nenhuma rede de valor necessária
Código: Oficial
O idioma instruiu o aprendizado de reforço para a coordenação humana-AI
Hengyuan Hu, Dorsa Sadigh
Palavra-chave: Coordenação Humana-AI, Alinhamento de Preferência Humana, Instrução Condicionada RL
Alinhando modelos de linguagem com aprendizado de reforço offline com o feedback humano
Jian Hu, Li Tao, June Yang, Chandler Zhou
Palavra-chave: Alinhamento baseado em Decision Transformer, aprendizado de reforço offline, sistema RLHF
Otimização de classificação de preferência para alinhamento humano
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li e Houfeng Wang
Palavra -chave: alinhamento de preferência humana supervisionada, extensão de classificação de preferência
Código: Oficial
Ponte a lacuna: uma pesquisa sobre integração (humano) feedback para geração de linguagem natural
Patrick Fernandes, Aman Madaan, Emmy Liu, António Farinhas, Pedro Henrique Martins, Amanda Bertsch, José GC de Souza, Shuyan Zhou, Tongshuang Wu, Graham Neubig, André Ft Martins
Palavra-chave: geração de linguagem natural, integração de feedback humano, formalização de feedback e taxonomia, feedback da IA e julgamentos baseados em princípios
Relatório Técnico GPT-4
Openai
Palavra-chave: um modelo multimodal em larga escala, modelo baseado em transformador, RLHF usado com ajuste fino
Código: Oficial
DataSet: Drop, Winogrande, Hellaswag, ARC, Humaneval, GSM8K, MMLU, Verinfulqa
RATA: Recompensa classificada na Finetuning para alinhamento generativo do modelo de fundação
Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, Tong Zhang
Palavra -chave: amostragem de rejeição Finetuning, alternativa ao PPO, modelo de difusão
Código: Oficial
RRHF: respostas de classificação para alinhar modelos de linguagem com feedback humano sem lágrimas
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
Palavra -chave: novo paradigma para RLHF
Código: Oficial
Aprendizagem de preferência de poucas fotos para o RL humano no loop
Joey Hejna, Dorsa Sadigh
Palavra-chave: aprendizado de preferência, aprendizado interativo, aprendizado de várias tarefas, expandindo o pool de dados disponíveis, visualizando o RL humano no loop
Código: Oficial
Melhor alinhar modelos de texto à imagem com preferência humana
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li
Palavra-chave: modelo de difusão, texto a imagem, estética
Código: Oficial
Imagereward: aprendendo e avaliando as preferências humanas para geração de texto para imagem
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
Palavra-chave: preferência humana de texto para imagem de uso geral RM, avaliando modelos generativos de texto para imagem
Código: Oficial
Conjunto de dados: coco, difusãodb
Alinhando modelos de texto à imagem usando feedback humano
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing DU, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu Gu
Palavra-chave: modelo de difusão estável de texto para imagem, função de recompensa que prevê feedback humano
Visual Chatgpt: conversando, desenhando e editando com modelos de fundação visual
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
Palavra -chave: modelos visuais de fundação, chatgpt visual
Código: Oficial
Modelos de idiomas pré -treinamento com preferências humanas (PHF)
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Jason Phang, Samuel R. Bowman, Ethan Perez
Palavra -chave: pré -treinamento, RL offline, transformador de decisão
Código: Oficial
Alinhando modelos de linguagem com preferências através da minimização da divergência F (F-DPG)
Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
Palavra-chave: Divergência F, RL com Penalidades KL
Aprendizagem de reforço de princípios com feedback humano de comparações em pares ou k-wise
Banghua Zhu, Jiantao Jiao, Michael I. Jordan
Palavra-chave: mle pessimista, max-entropia IRL
A capacidade de autocorreção moral em grandes modelos de linguagem
Antrópico
Palavra-chave: melhorar a capacidade de autocorreção moral, aumentando o treinamento do RLHF
Conjunto de dados; Churrasco
A aprendizagem de reforço (não) para o processamento de linguagem natural?: Benchmarks, linhas de base e blocos de construção para otimização de políticas de linguagem natural (NLPO)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Palavra -chave: otimizando geradores de linguagem com RL, benchmark, algoritmo RL Performant
Código: Oficial
DataSet: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (EN-DE), Narrativeqa, DailyDialog
Salonamento de leis para o otimização do modelo de recompensa
Leo Gao, John Schulman, Jacob Hilton
Palavra -chave: Modelo de recompensa de ouro modelo de recompensa de proxy, tamanho do conjunto de dados, tamanho do parâmetro de política, Bon, PPO
Melhorando o alinhamento de agentes de diálogo por meio de julgamentos humanos direcionados (pardal)
Amelia Glaese, Nat McAleese, Maja Trębacz, et al.
Palavra-chave: agente de diálogo em busca de informações, divide o bom diálogo em regras de linguagem natural, DPC, interaja com o modelo para obter violação de uma regra específica (sondagem adversária)
Conjunto de dados: questões naturais, eli5, qualidade, triviaqa, winobias, churrasco
Modelos de idiomas em equipes vermelhas para reduzir os danos: métodos, comportamentos de escala e lições aprendidas
Deep Gangus, Liane Lovitt, Jackson Kernion, et al.
Palavra -chave: Modelo de idioma da equipe Red, investigar comportamentos de escala, leitura do conjunto de dados de equipes
Código: Oficial
Planejamento dinâmico em diálogo aberto usando aprendizado de reforço
Deborah Cohen, Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpektor, Craig Boutilier, Gal Elidan
Palavra-chave: sistema de diálogo em tempo real, em tempo real, combina a incorporação sucinta do estado de conversa por modelos de idiomas, CAQL, CQL, BERT
Quark: geração de texto controlável com desaprecitação reforçada
Ximing Lu, Sean Welkeck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
Palavra-chave: ajuste o modelo de idioma em sinais do que não fazer, Decision Transformer, LLM Tuning com PPO
Código: Oficial
DataSet: WritingPrompts, SST-2, Wikitext-103
Treinar um assistente útil e inofensivo com o aprendizado de reforço com o feedback humano
Yuntao Bai, Andy Jones, Kamal Nndouse, et al.
Palavra -chave: assistentes inofensivos, modo online, robustez do treinamento RLHF, detecção de OOD.
Código: Oficial
DataSet: Triviaqa, Hellaswag, ARC, OpenBookqa, Lambada, Humaneval, Mmlu, Verinfulqa
Ensinar modelos de linguagem para apoiar respostas com citações verificadas (gophercite)
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, Nat Mcalese
Palavra -chave: gerar respostas que citando evidências específicas, abster -se de responder quando não tiverem certeza
DataSet: Perguntas naturais, ELI5, Qualidade, Siginfulqa
Modelos de idiomas de treinamento para seguir as instruções com feedback humano (InstructGPT)
Long Ouyang, Jeff Wu, Xu Jiang, et al.
Palavra -chave: Modelo de linguagem grande, alinhamento do modelo de linguagem com intenção humana
Código: Oficial
DataSet: SiginfulQa, RealtoxicityPROMPTS
Ai constitucional: inofensibilidade do feedback da IA
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, et al.
Palavra-chave: RL da IA Feedback (RLAIF), treinando um assistente de IA inofensivo por meio de auto-aperfeiçoamento, estilo de cadeia de pensamento, controle a IA comportamento com mais precisão
Código: Oficial
Descobrindo comportamentos do modelo de linguagem com avaliações escrivas de modelo
Ethan Perez, Sam Ringer, Kamilė Lukošiūtė, Karina Nguyen, Edwin Chen, et al.
Palavra-chave: gerar avaliações automaticamente com LMS, mais RLHF piora o LMS, as avaliações escradas por LM são de alta qualidade
Código: Oficial
Conjunto de dados: churrasco, esquemas Winogender
Modelagem de recompensa não-markoviana de rótulos de trajetória por meio de aprendizado interpretável de múltiplas instâncias
Joseph Early, Tom Bewley, Christine Evers, Sarvapali Ramchurn
Palavra-chave: Modelagem de Recompensa (RLHF), não-Markovian, Aprendizagem de Instância Múltipla, Interpretabilidade
Código: Oficial
WebGPT: Pergunta assistida por navegador-Responsando com feedback humano (WebGPT)
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, et al.
Palavra -chave: Pesquise de modelo na Web e forneça referência , Imitação de aprendizado , aC, pergunta longa
DataSet: Eli5, Triviaqa, Siginfulqa
Resumindo recursivamente livros com feedback humano
Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Like, Paul Christiano
Palavra -chave: Modelo treinado em pequena tarefa para ajudar a avaliar a tarefa mais ampla, BC
DataSet: Booksum, NarrativeQa
Revisitando as fraquezas do aprendizado de reforço para tradução para a máquina neural
Samuel Kiegeland, Julia Kreutzer
Palavra -chave: o sucesso do gradiente de políticas é por causa da recompensa e não da forma da distribuição de saída, tradução da máquina, NMT, adaptação de domínio
Código: Oficial
DataSet: WMT15, IWSLT14
Aprendendo a resumir do feedback humano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano
Palavra -chave: preocupe -se com a qualidade do resumo, a perda de treinamento afeta o comportamento do modelo, o modelo de recompensa generaliza para novos conjuntos de dados
Código: Oficial
Conjunto de dados: tl; dr, cnn/dm
Modelos de linguagem de ajuste fino de preferências humanas
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Palavra -chave: Aprendizagem de recompensa para a linguagem, texto contínuo com sentimento positivo, tarefa de resumo, descritivo físico
Código: Oficial
Conjunto de dados: tl; dr, cnn/dm
Alinhamento de agente escalável via modelagem de recompensa: uma direção de pesquisa
Jan Like, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, Shane Legg
Palavra -chave: problema de alinhamento do agente, aprenda recompensa com a interação, otimize a recompensa com a RL, modelagem de recompensa recursiva
Código: Oficial
Env: Atari
Recompense o aprendizado de preferências e demonstrações humanas em Atari
Borja Ibarz, Jan Like, Tobias Pohlen, Geoffrey Irving, Shane Legg, Dario Amodei
Palavra -chave: Preferências de trajetória de demonstração especializadas Recompensa problema de hackers, ruído no rótulo humano
Código: Oficial
Env: Atari
Tamer profundo: modelagem de agentes interativos em espaços de estado de alta dimensão
Garrett Warnell, Nicholas Waytowich, Vernon Lawhern, Peter Stone
Palavra -chave: Estado de alta dimensão, alavancar a entrada do treinador humano
Código: terceiros
Env: Atari
Aprendizando profundo de reforço com as preferências humanas
Paul Christono, Jan Like, Tom B. Brown, Miljan Magtic, Shane Legg, Dario Amodei
Palavra -chave: explorar metas definidas nas preferências humanas entre pares de trajetórias segmentação, aprenda mais complexo do que feedback humano
Código: Oficial
Env: Atari, Mujoco
Aprendizagem interativa com feedback humano dependente da política
James MacGlashan, Mark K Ho, Robert Loftin, Bei Peng, Guan Wang, David Roberts, Matthew E. Taylor, Michael L. Littman
Palavra -chave: a decisão é influenciada pela política atual e não pelo feedback humano, aprenda com o feedback dependente da política que converge para um ideal local ideal
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
Verl: Aprendizagem de reforço do motor do vulcão para LLM
Bytedance Seed Mlsys Team & Hku: Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Palavra -chave: estrutura flexível, eficiente, RLHF
Tarefas: RLHF, tarefas de raciocínio, incluindo matemática e código.
Openrlhf
Openrlhf
Palavra -chave: 70B, RLHF, DeepSpeed, Ray, Vllm
Tarefa: Uma estrutura RLHF fácil de usar, escalável e de alto desempenho (suporta 70b+ ajuste completo & lora & mixtral & kto).
Palm + rlhf - pytorch
Phil Wang, Yachine Zahidi, Ikko Eltociear Ashimine, Eric Alcaide
Palavra -chave: Transformers, Palm Architecture
Conjunto de dados: enwik8
Presferências LM-Human
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Palavra -chave: Aprendizagem de recompensa para a linguagem, texto contínuo com sentimento positivo, tarefa de resumo, descritivo físico
Conjunto de dados: tl; dr, cnn/dm
A seguir, inseguros-feedback
Long Ouyang, Jeff Wu, Xu Jiang, et al.
Palavra -chave: Modelo de linguagem grande, alinhamento do modelo de linguagem com intenção humana
DataSet: SiginfulQa RealToxicityPROMPTS
Aprendizagem de reforço do transformador (TRL)
Leandro von Werra, Younes Belkada, Lewis Tunstall, et al.
Palavra -chave: Train LLM com RL, PPO, Transformer
Tarefa: IMDB Sentimento
Aprendizagem de reforço do transformador x (TRLX)
Jonathan Tow, Leandro von Werra, et al.
Palavra-chave: estrutura de treinamento distribuída, modelos de idiomas baseados em T5, Train LLM com RL, PPO, ILQL
Tarefa: Fine Tuning LLM com RL usando a função de recompensa fornecida ou conjunto de dados marcado com recompensa
RL4LMS (uma biblioteca RL modular para modelos de linguagem ajustados para preferências humanas)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Palavra -chave: otimizando geradores de linguagem com RL, benchmark, algoritmo RL Performant
DataSet: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (EN-DE), Narrativeqa, DailyDialog
Lamda-rlhf-pytorch
Phil Wang
Palavra-chave: Lamda, mecanismo de atenção
Tarefa: Implementação de pré-treinamento de código aberto do papel de pesquisa Lamda do Google em Pytorch
Textrl
Eric Lam
Palavra -chave: Transformador do Huggingface
Tarefa: geração de texto
Env: pfrl, academia
Minrlhf
Thomfoster
Palavra -chave: PPO, biblioteca mínima
Tarefa: fins educacionais
DeepSpeed-Chat
Microsoft
Palavra -chave: treinamento RLHF acessível
Dromedário
IBM
Palavra-chave: supervisão humana mínima, alinhada
Tarefa: Modelo de linguagem auto-alinhada treinada com supervisão humana mínima
FG-RLHF
Zeqiu Wu, Yushi Hu, Weijia Shi, et al.
Palavra-chave: RLHF de grão fino, fornecendo uma recompensa após cada segmento, incorporando vários RMs associados a diferentes tipos de feedback
Tarefa: Uma estrutura que permite o treinamento e o aprendizado com as funções de recompensa que são finas em densidade e múltiplos rms -Safe-rlhf
Xuehai Pan, Ruiyang Sun, Jiaming Ji, et al.
Palavra-chave: suporta modelos pré-treinados populares, grandes conjuntos de dados marcados por humanos, métricas em várias escalas para verificação de restrições de segurança, parâmetros personalizados
Tarefa: LLM restrito alinhado ao valor via RLHF seguro
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
Ben Mann, Ganguli Deep
Palavra-chave: conjunto de dados de preferência humana, dados de equipes vermelhas, escrita por máquina
Tarefa: conjunto de dados de fonte aberta para dados de preferência humana sobre utilidade e falta de falta
Conjunto de dados de preferências humanas de Stanford (SHP)
Etayarajh, Kawin e Zhang, Heidi e Wang, Yizhong e Jurafsky, Dan
Palavra-chave: DataSet de ocorrência natural e escrita humana, 18 áreas diferentes de assuntos
Tarefa: destinado a ser usado para treinar modelos de recompensa RLHF
PromptSource
Stephen H. Bach, Victor Sanh, Zheng-Xin Yong et al.
Palavra -chave: conjuntos de dados em inglês solicitado, mapeando um exemplo de dados para a linguagem natural
Tarefa: Kit de ferramentas para criar, compartilhar e usar prompts de linguagem natural
Coleções de Recursos de Conhecimento Estruturado (SKG)
Tianbao Xie, Chen Henry Wu, Peng Shi et al.
Palavra -chave: aterramento de conhecimento estruturado
Tarefa: a coleta de conjuntos de dados está relacionada ao aterramento de conhecimento estruturado
A coleção de flan
Longpre Shayne, Hou Le, Vu Tu et al.
Tarefa: coleção compila conjuntos de dados do Flan 2021, P3, instruções super-naturais
RLHF-RECWARW-DataSets
Yiting Xie
Palavra-chave: conjunto de dados escrito por máquina
webgpt_comparisons
Openai
Palavra-chave: conjunto de dados escrito por humanos, resposta de perguntas de forma longa
Tarefa: Treine um modelo de resposta de perguntas de forma longa para se alinhar com as preferências humanas
Summarize_from_feedback
Openai
Palavra-chave: conjunto de dados escrito por humanos, resumo
Tarefa: Treine um modelo de resumo para se alinhar com as preferências humanas
Dahoas/Instrução Sintética-Gptj-Parwise
Dahoas
Palavra-chave: conjunto de dados escrito por humanos, conjunto de dados sintéticos
Alinhamento estável - Aprendizagem de alinhamento em jogos sociais
Ruibo Liu, Ruixin (Ray) Yang, Qiang Peng
Palavra -chave: Dados de interação usados para treinamento de alinhamento, executados na Sandbox
Tarefa: Treine os dados de interação gravados em jogos sociais simulados
Lima
Meta ai
Palavra -chave: sem nenhum RLHF, poucas instruções e respostas cuidadosamente selecionadas
Tarefa: conjunto de dados usado para treinar o modelo LIMA
[OpenAI] chatgpt: otimizando modelos de linguagem para diálogo
[Abraçando o rosto] ilustrando o aprendizado de reforço com o feedback humano (RLHF)
[Zhihu] 通向 agi 之路 : : 大型语言模型 (llm) 技术精要
[Zhihu] 大语言模型的涌现能力 : :
[Zhihu] 中文 hh-rlhf 数据集上的 ppo 实践
[W&B totalmente conectado] Entendendo o aprendizado de reforço com o feedback humano (RLHF)
[DeepMind] Aprendendo através do feedback humano
[Noção] 深入理解语言模型的突现能力
[Noção] 拆解追溯 GPT-3.5 各项能力的起源
[GIST] Aprendizagem de reforço para modelos de idiomas
[YouTube] John Schulman - Aprendizagem de reforço com o feedback humano: progresso e desafios
[Openai / arize] OpenAI sobre aprendizado de reforço com feedback humano
[Encord] Guia para reforçar o aprendizado do feedback humano (RLHF) para visão computacional
[Weixun Wang] Visão geral de RL (HF)+LLM
turco
Nosso objetivo é tornar esse repo ainda melhor. Se você estiver interessado em contribuir, consulte aqui para obter instruções em contribuição.
O Awesome RLHF é lançado sob a licença Apache 2.0.


