IP Adapter
1.0.0
Apresentamos o adaptador IP, um adaptador eficaz e leve para alcançar a capacidade de prompt de imagem para os modelos de difusão de texto para imagem pré-treinados. Um adaptador IP com apenas 22M parâmetros pode obter um desempenho comparável ou ainda melhor com um modelo de prompt de imagem ajustado. O adaptador IP pode ser generalizado não apenas para outros modelos personalizados ajustados do mesmo modelo básico, mas também para geração controlável usando ferramentas controláveis existentes. Além disso, o prompt de imagem também pode funcionar bem com o prompt de texto para realizar a geração de imagens multimodais.
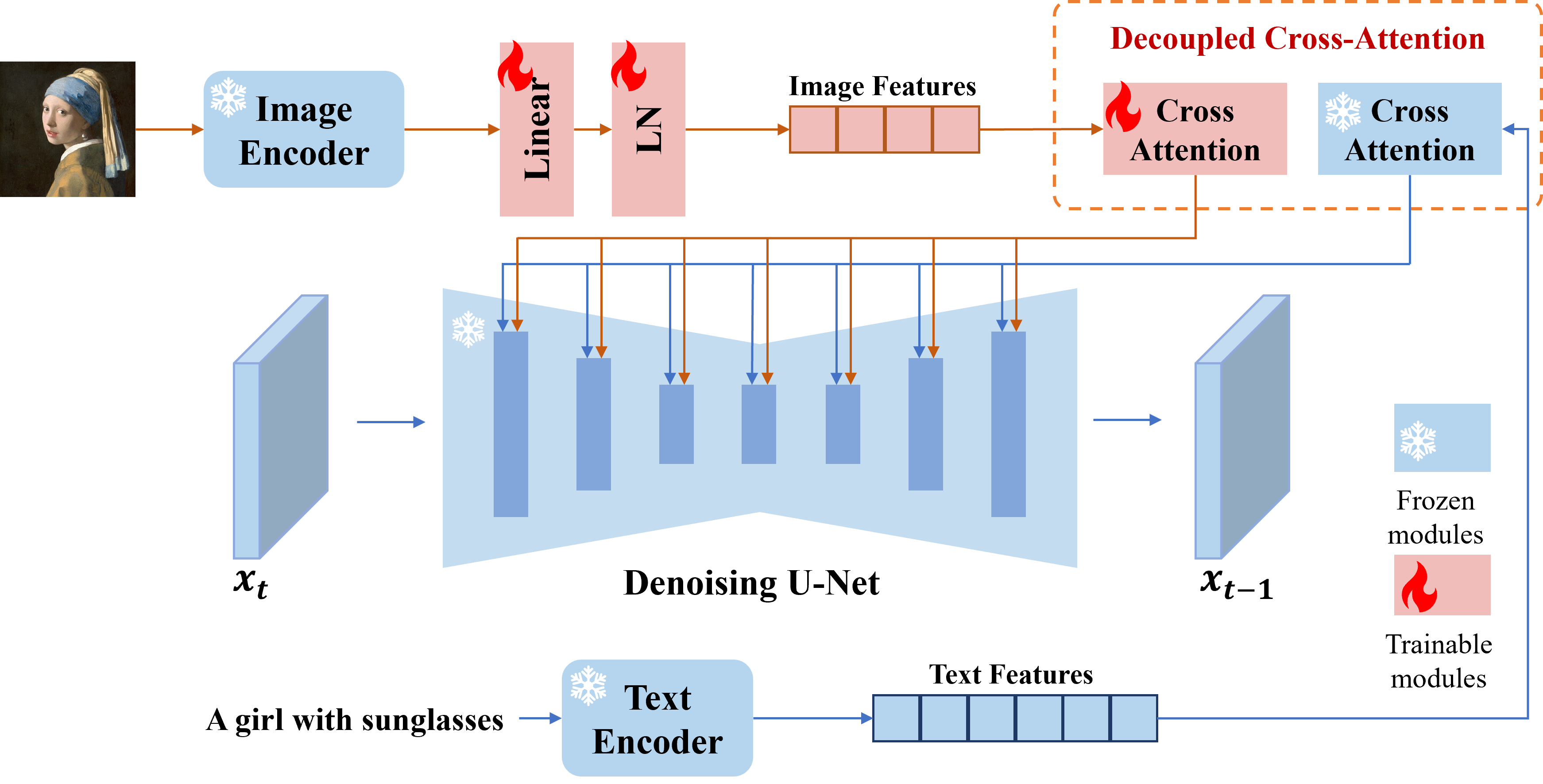
# install latest diffusers
pip install diffusers==0.22.1
# install ip-adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git
# download the models
cd IP-Adapter
git lfs install
git clone https://huggingface.co/h94/IP-Adapter
mv IP-Adapter/models models
mv IP-Adapter/sdxl_models sdxl_models
# then you can use the notebook
Você pode baixar modelos aqui. Para executar a demonstração, você também deve baixar os seguintes modelos:









Prática recomendada
scale=1.0 e text_prompt="" (ou alguns prompts genéricos de texto, por exemplo, "melhor qualidade", você também pode usar qualquer prompt de texto negativo). Se você diminuir a scale , imagens mais diversas podem ser geradas, mas elas podem não ser tão consistentes com o prompt de imagem.scale para obter os melhores resultados. Na maioria dos casos, a definição scale=0.5 pode obter bons resultados. Para a versão do SD 1.5, recomendamos o uso de modelos comunitários para gerar boas imagens.Adaptador IP para imagens não quadradas
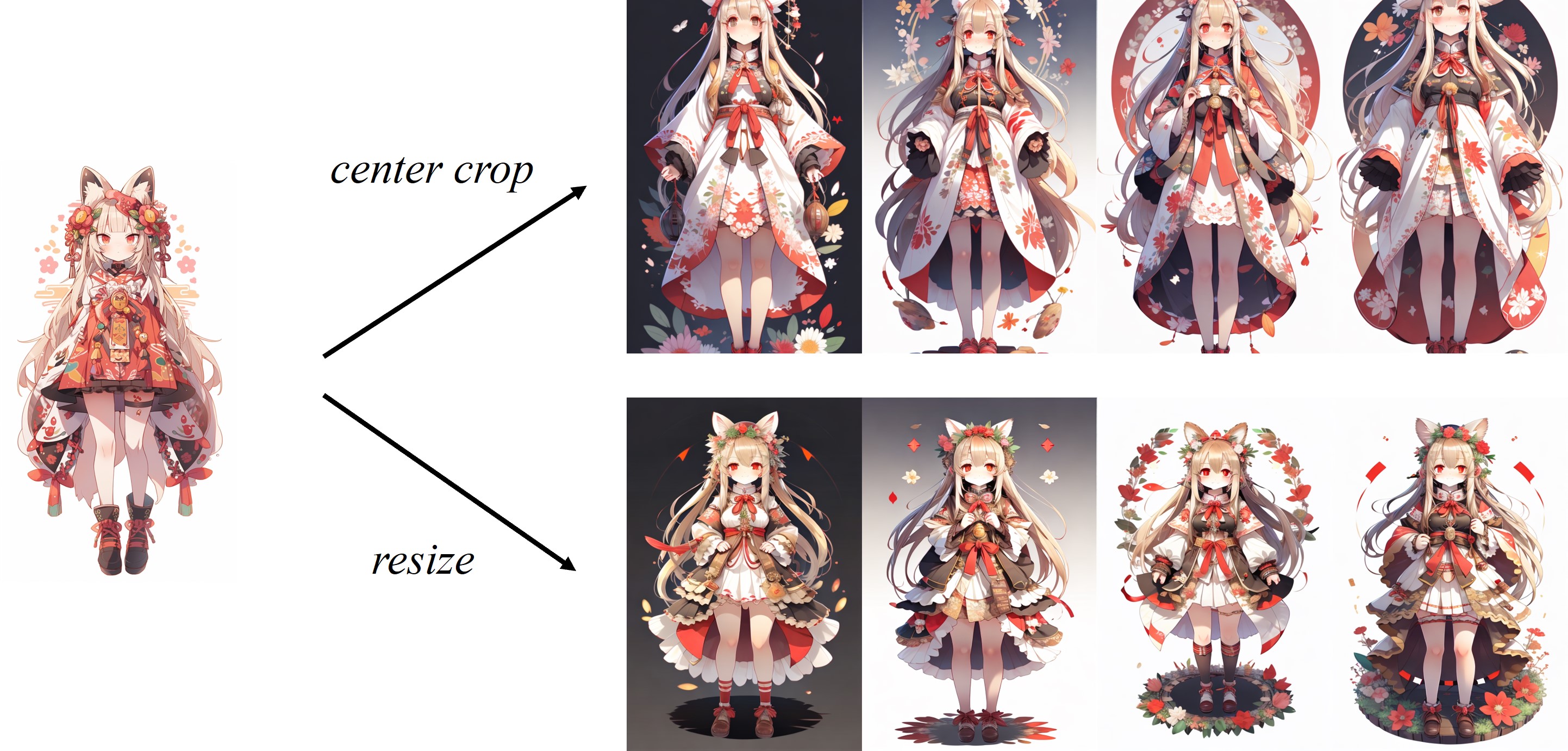
À medida que a imagem é centrada no processador de imagem padrão do clipe, o IP-Adaption funciona melhor para imagens quadradas. Para as imagens não quadradas, perderá as informações fora do centro. Mas você pode apenas redimensionar para 224x224 para imagens não quadradas, a comparação é a seguinte:
A comparação de ip-adapter_xl com a reimagina XL é mostrada da seguinte maneira:

Melhorias na nova versão (2023.9.8) :
Para treinamento, você deve instalar acelerar e transformar seu próprio conjunto de dados em um arquivo json.
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16"
tutorial_train.py
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/"
--image_encoder_path="{image_encoder_path}"
--data_json_file="{data.json}"
--data_root_path="{image_path}"
--mixed_precision="fp16"
--resolution=512
--train_batch_size=8
--dataloader_num_workers=4
--learning_rate=1e-04
--weight_decay=0.01
--output_dir="{output_dir}"
--save_steps=10000
Depois que o treinamento estiver concluído, você pode converter os pesos com o seguinte código:
import torch
ckpt = "checkpoint-50000/pytorch_model.bin"
sd = torch . load ( ckpt , map_location = "cpu" )
image_proj_sd = {}
ip_sd = {}
for k in sd :
if k . startswith ( "unet" ):
pass
elif k . startswith ( "image_proj_model" ):
image_proj_sd [ k . replace ( "image_proj_model." , "" )] = sd [ k ]
elif k . startswith ( "adapter_modules" ):
ip_sd [ k . replace ( "adapter_modules." , "" )] = sd [ k ]
torch . save ({ "image_proj" : image_proj_sd , "ip_adapter" : ip_sd }, "ip_adapter.bin" )Este projeto se esforça para impactar positivamente o domínio da geração de imagens acionada por IA. Os usuários têm a liberdade de criar imagens usando essa ferramenta, mas espera -se que cumpram as leis locais e a utilizem de maneira responsável. Os desenvolvedores não assumem nenhuma responsabilidade pelo uso indevido em potencial pelos usuários.
Se você achar o adaptador IP útil para sua pesquisa e aplicativos, cite usando este Bibtex:
@article { ye2023ip-adapter ,
title = { IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models } ,
author = { Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei } ,
booktitle = { arXiv preprint arxiv:2308.06721 } ,
year = { 2023 }
}

