scratchplot story generation
1.0.0
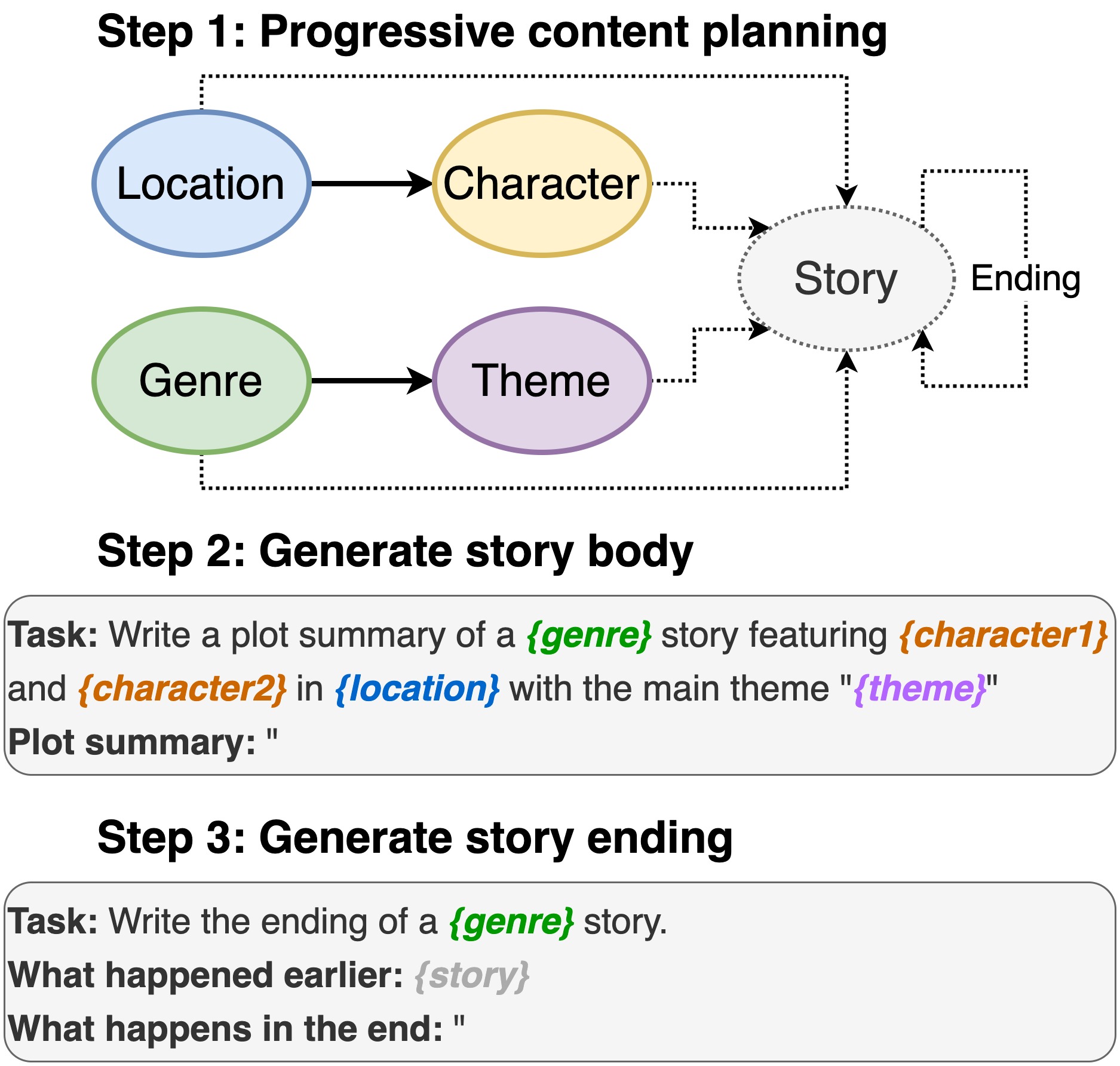
Esse repositório contém o código para a redação de plotagem a partir de modelos de idiomas pré-treinados , para aparecer no INLG 2022. O artigo apresenta um método para primeiro solicitar um PLM a compor um plano de conteúdo. Em seguida, geramos o corpo da história e o fim condicionado ao plano de conteúdo. Além disso, adotamos uma abordagem de gerar e rank usando PLMs adicionais para classificar os pares gerados (histórias, terminando).
Este repo depende muito do Dino. Como fizemos algumas pequenas alterações, incluímos o código completo para facilitar o uso.
Incluindo localização, elenco, gênero e tema.
sh run_plot_static_gpu.shOs elementos do plano de conteúdo são gerados uma vez e armazenados. Ao gerar as histórias, o sistema amostra dos elementos da plotagem gerada offline.
sh run_plot_dynamic_gpu_single.shsh run_plot_dynamic_gpu_batch.sh--no_cuda a todos os comandos que chamam dino.pyRequer python3. Testado no Python 3.6 e 3.8.
pip3 install -r requirements.txt import nltk
nltk . download ( 'punkt' )
nltk . download ( 'stopwords' )Se você usar o código neste repositório, cite o seguinte artigo:
@inproceedings{jin-le-2022-plot,
title = "Plot Writing From Pre-Trained Language Models",
author = "Jin, Yiping and Kadam, Vishakha and Wanvarie, Dittaya",
booktitle = "Proceedings of the 15th International Natural Language Generation conference",
year = "2022",
address = "Maine, USA",
publisher = "Association for Computational Linguistics"
}
Se você usar o DINO para outras tarefas, cite também o seguinte artigo:
@article{schick2020generating,
title={Generating Datasets with Pretrained Language Models},
author={Timo Schick and Hinrich Schütze},
journal={Computing Research Repository},
volume={arXiv:2104.07540},
url={https://arxiv.org/abs/2104.07540},
year={2021}
}


