paper2slides
1.0.0
Transforme quaisquer papéis ARXIV em slides usando grandes modelos de linguagem (LLMS)! Esta ferramenta é útil para entender rapidamente as principais idéias dos trabalhos de pesquisa.
Alguns exemplos de lâminas geradas são: Word2vec, GaN, Transformer, Vit, Cadeia de pensamento, estrela, DPO e cientista da IA. Veja muitos outros exemplos de slides gerados na demonstração.
O script baixará arquivos da Internet (ARXIV), enviará informações para a API OpenAI e compilar localmente. Por favor, seja cauteloso sobre o conteúdo compartilhado e os riscos potenciais. Se você tiver um ID ARXIV específico no qual está interessado e não deseja executar o código sozinho, informe -me em "Discussões" e ficaria feliz em adicionar os slides à lista de demonstrações.
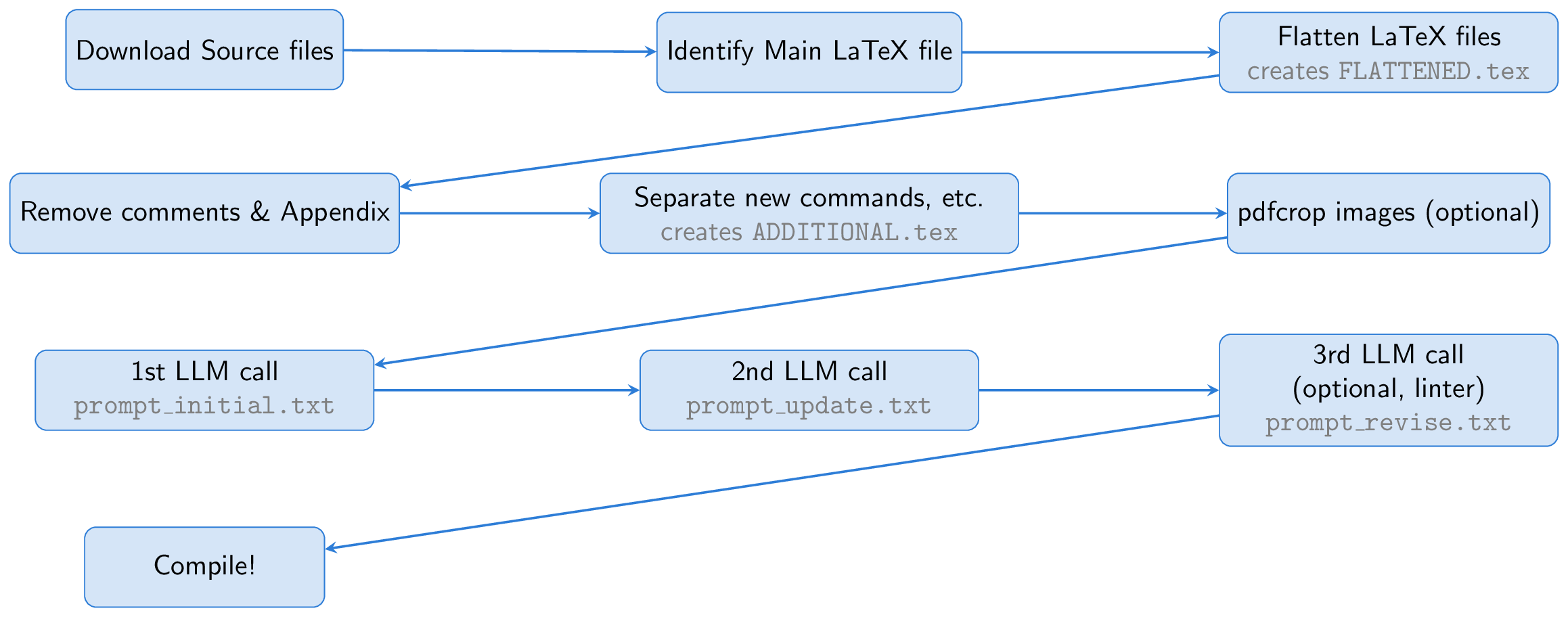
O processo começa baixando os arquivos de origem de um artigo ARXIV. O arquivo de látex principal é identificado e achatado, mesclando todos os arquivos de entrada em um único documento ( FLATTENED.tex ). Pré -processo esse arquivo mesclado removendo comentários e o apêndice. Este arquivo pré -processado, juntamente com as instruções para criar bons slides, forma a base do nosso prompt.
Uma idéia importante é usar o Beamer para a criação de slides, permitindo que permaneçamos inteiramente dentro do ecossistema de látex. Essa abordagem transforma essencialmente a tarefa em um exercício de resumo: converter um papel de látex longo em látex conciso. O LLM pode inferir o conteúdo das figuras de suas legendas e incluí -las nos slides, eliminando a necessidade de recursos de visão.
Para ajudar o LLM, criamos um arquivo chamado ADDITIONAL.tex , que contém todos os pacotes necessários, definições newCommand e outras configurações de látex usadas no papel. A inclusão deste arquivo com input{ADDITIONAL.tex} no prompt a diminui e torna os slides de geração mais confiáveis, principalmente para trabalhos teóricos com muitos comandos personalizados.
O LLM gera código Beamer a partir da fonte do LaTex, mas como a primeira execução pode ter problemas, pedimos ao LLM que se auto-inspecione e refine a saída. Opcionalmente, uma terceira etapa envolve o uso de um linhador para verificar o código gerado, com os resultados de volta ao LLM para correções adicionais (essa etapa do Linter foi inspirada pelo cientista da IA). Finalmente, o código Beamer é compilado em uma apresentação em PDF usando PDFlateX.
O script all.zsh automatiza todo o processo, normalmente concluindo em menos de alguns minutos com o GPT-4O para um único papel.
Os requisitos são:
requestsarxivopenaiarxiv-latex-cleanerpdflatexEtapas para instalação:
Clone este repositório:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slidesInstale os pacotes Python necessários:
pip install requests arxiv openai arxiv-latex-cleaner Verifique se pdflatex está instalado e disponível no caminho do seu sistema. Opcionalmente, verifique se você pode compilar o exemplo de test.tex por pdflatex test.tex . Verifique se test.pdf é generalizado corretamente. Opcionalmente, verifique chktex e pdfcrop estão funcionando.
Configure sua chave de API do OpenAI:
export OPENAI_API_KEY= ' your-api-key ' all.shEste script automatiza o processo de download de um papel Arxiv, processando -o e convertendo -o em uma apresentação de Beamer.
bash all.sh < arxiv_id > Substitua <arxiv_id> pelo ID de papel Arxiv desejado. O ID pode ser identificado no URL: o ID para https://arxiv.org/abs/xxxx.xxxx é xxxx.xxxx .
Você também pode executar os scripts do Python individualmente para obter mais controle.
Baixe e processe arquivos de origem Arxiv Arxiv
python arxiv2tex.py < arxiv_id > Esse script baixa os arquivos de origem do papel arxiv especificado, os extrai e processa o arquivo de látex principal. Os resultados serão salvos na source/<arxiv_id>/FLATTENED.tex e source/<arxiv_id>/ADDITIONAL.tex .
Converter látex em Beamer
python tex2beamer.py --arxiv_id < arxiv_id > Este script lê os arquivos de látex processados e prepara slides de Beamer. É aqui que estamos usando a API OpenAI. Ligamos duas vezes, primeiro para gerar o código Beamer e depois para se auto-inspecionar o código Beamer. Opcionalmente, use os seguintes sinalizadores: --use_linter e --use_pdfcrop . Os avisos enviados para o LLM e a resposta do LLM serão salvos no tex2beamer.log . O log do Linter será salvo na source/<arxiv_id>/linter.log .
Converta Beamer em PDF
python beamer2pdf.py < arxiv_id >Esse script compila o arquivo Beamer em uma apresentação em PDF.
Os avisos são salvos em prompt_initial.txt , prompt_update.txt e prompt_revise.txt , mas fique à vontade para ajustá -los às suas necessidades. Eles contêm um espaço reservado chamado PLACEHOLDER_FOR_FIGURE_PATHS . Isso será substituído pelos caminhos da figura usados no papel. Queremos garantir que os caminhos sejam usados corretamente no código Beamer. O LLM geralmente comete erros, por isso incluímos explicitamente isso no prompt.
A taxa de sucesso é de cerca de 90 % na minha experiência (a compilação pode falhar ou o caminho da imagem pode estar errado em alguns casos). Se você encontrar algum problema ou tiver alguma sugestão de melhorias, sinta -se à vontade para me avisar!


