multi model server
v1.1.11 - Extra error logging and new timeout config
| Ubuntu/Python-2.7 | Ubuntu/Python-3.6 |
|---|---|
O Multi Model Server (MMS) é uma ferramenta flexível e fácil de usar para servir modelos de aprendizado profundo treinados usando qualquer estrutura ML/DL.
Use a CLI do servidor MMS, ou as imagens do Docker pré-configurado, para iniciar um serviço que configure pontos de extremidade HTTP para lidar com solicitações de inferência do modelo.
Uma visão geral rápida e exemplos para porção e embalagem são fornecidos abaixo. Documentação e exemplos detalhados são fornecidos na pasta Docs.
Junte -se ao nosso Slack Channel para entrar em contato com a equipe de desenvolvimento, fazer perguntas, descobrir o que está cozinhando e muito mais!
Slack Channel para entrar em contato com a equipe de desenvolvimento, fazer perguntas, descobrir o que está cozinhando e muito mais!
Antes de prosseguir com este documento, verifique se você possui os seguintes pré -requisitos.
Ubuntu, Centos ou MacOS. O suporte ao Windows é experimental. As seguintes instruções se concentrarão apenas no Linux e no MacOS.
Python - o Multi Model Server exige que Python administre os trabalhadores.
PIP - PIP é um sistema de gerenciamento de pacotes Python.
Java 8 - O servidor de modelos multi requer que o Java 8 inicie. Você tem as seguintes opções para instalar o Java 8:
Para Ubuntu:
sudo apt-get install openjdk-8-jre-headlessPara o CentOS:
sudo yum install java-1.8.0-openjdkPara macOS:
brew tap homebrew/cask-versions
brew update
brew cask install adoptopenjdk8Etapa 1: Configure um ambiente virtual
Recomendamos instalar e executar o servidor multi -model em um ambiente virtual. É uma boa prática executar e instalar todas as dependências do Python em ambientes virtuais. Isso fornecerá isolamento das dependências e facilitará o gerenciamento de dependência.
Uma opção é usar o VirtualEnv. Isso é usado para criar ambientes virtuais de Python. Você pode instalar e ativar um VirtualEnv para o Python 2.7 da seguinte forma:
pip install virtualenvEm seguida, crie um ambiente virtual:
# Assuming we want to run python2.7 in /usr/local/bin/python2.7
virtualenv -p /usr/local/bin/python2.7 /tmp/pyenv2
# Enter this virtual environment as follows
source /tmp/pyenv2/bin/activateConsulte a documentação VirtualEnv para obter mais informações.
Etapa 2: Instale o MXNET MMS não instale o mecanismo MXNET por padrão. Se ainda não estiver instalado em seu ambiente virtual, você deve instalar um dos pacotes MXNET PIP.
Para inferência da CPU, recomenda-se mxnet-mkl . Instale o seguinte:
# Recommended for running Multi Model Server on CPU hosts
pip install mxnet-mkl Para inferência de GPU, recomenda-se mxnet-cu92mkl . Instale o seguinte:
# Recommended for running Multi Model Server on GPU hosts
pip install mxnet-cu92mklEtapa 3: Instale ou atualize o MMS da seguinte forma:
# Install latest released version of multi-model-server
pip install multi-model-server Para atualizar a partir de uma versão anterior do multi-model-server , consulte o documento de referência de migração.
Notas:
model-archiver será instalada com MMS como dependência. Consulte Model-Archiver para obter mais opções e detalhes. Depois de instalado, você pode colocar o MMS Model Server e funcionando muito rapidamente. Experimente --help para ver todas as opções da CLI disponíveis.
multi-model-server --helpPara esse início rápido, ignoraremos a maioria dos recursos, mas não deixe de dar uma olhada nos documentos do servidor completo quando estiver pronto.
Aqui está um exemplo fácil para servir um modelo de classificação de objetos:
multi-model-server --start --models squeezenet=https://s3.amazonaws.com/model-server/model_archive_1.0/squeezenet_v1.1.marCom o comando acima executado, você tem MMS em execução em seu host, ouvindo solicitações de inferência. Observe que, se você especificar modelos durante o início do MMS - ele aumentará automaticamente os trabalhadores de back -end para o número igual ao VCPUS disponível (se você executar na instância da CPU) ou ao número de GPUs disponíveis (se você executar na instância da GPU ). No caso de hosts poderosos com muitos recursos de computação (VCPUs ou GPUs), esse processo de inicialização e caráter automático pode levar um tempo considerável. Se você deseja minimizar o tempo de inicialização do MMS, tente evitar o registro e dimensionar o modelo durante o horário de início e movê -lo para um ponto posterior usando chamadas de API de gerenciamento correspondentes (isso permite o controle de grãos mais finos de quantos recursos são alocados para qualquer modelo específico).
Para testá -lo, você pode abrir uma nova janela de terminal ao lado da MMS em execução. Em seguida, você pode usar curl para baixar uma dessas fotos fofas de um gatinho e a bandeira -o de Curl vai nomear kitten.jpg para você. Em seguida, você curl uma POST para o MMS prever o terminal com a imagem do gatinho.

No exemplo abaixo, fornecemos um atalho para essas etapas.
curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpg
curl -X POST http://127.0.0.1:8080/predictions/squeezenet -T kitten.jpgO endpoint previsto retornará uma resposta de previsão no JSON. Parecerá algo como o seguinte resultado:
[
{
"probability" : 0.8582232594490051 ,
"class" : " n02124075 Egyptian cat "
},
{
"probability" : 0.09159987419843674 ,
"class" : " n02123045 tabby, tabby cat "
},
{
"probability" : 0.0374876894056797 ,
"class" : " n02123159 tiger cat "
},
{
"probability" : 0.006165083032101393 ,
"class" : " n02128385 leopard, Panthera pardus "
},
{
"probability" : 0.0031716004014015198 ,
"class" : " n02127052 lynx, catamount "
}
] Você verá esse resultado na resposta à sua chamada curl para o terminal de previsão e, no servidor, registra a janela do terminal executando o MMS. Também está sendo registrado localmente com métricas.
Outros modelos podem ser baixados do zoológico do modelo, então experimente alguns deles também.
Agora você viu como pode ser fácil servir um modelo de aprendizado profundo com MMS! Você gostaria de saber mais?
Para interromper a instância atual do servidor modelo em execução, execute o seguinte comando:
$ multi-model-server --stopVocê veria a saída especificando que o servidor multi-modelo parou.
O MMS permite que você empacote todos os seus artefatos de modelo em um único arquivo de modelo. Isso facilita o compartilhamento e implantação de seus modelos. Para embalar um modelo, confira a documentação do arquiver do modelo
Navegue até o Docs Readme para obter o índice completo de documentação. Isso inclui mais exemplos, como personalizar o serviço da API, detalhes do terminal da API e muito mais.
Aqui estão alguns exemplos de demos de aplicativos de aprendizado profundo, alimentados pelo MMS:
Classificação de revisão de produtos 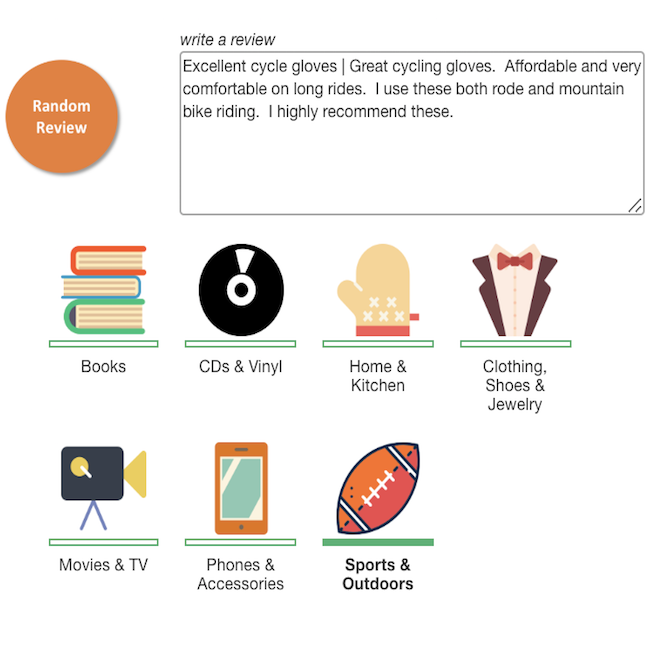 | Pesquisa visual 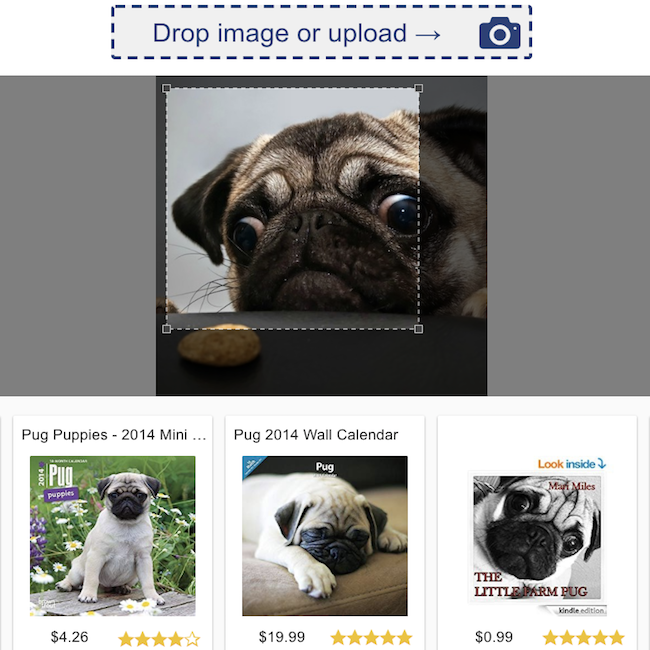 |
Reconhecimento de emoção facial  | Transferência de estilo neural  |
Congratulamo -nos com todas as contribuições!
Para arquivar um bug ou solicitar um recurso, arquive um problema do GitHub. Solicitações de tração são bem -vindas.


