l2p
1.0.0
Esta base de código contém a implementação de dois métodos de aprendizado contínuo:
O L2P é uma nova técnica de aprendizado contínuo que aprende a solicitar dinamicamente um modelo pré-treinado a aprender tarefas sequencialmente sob diferentes transições de tarefas. Diferente dos métodos baseados em ensaios ou arquitetura baseados em ensaios, o L2P não requer um buffer de ensaio nem a identidade da tarefa de tempo de teste. O L2P pode ser generalizado para várias configurações de aprendizado contínuo, incluindo a configuração mais desafiadora e realista da tarefa. O L2P supera consistentemente os métodos anteriores de última geração. Surpreendentemente, o L2P alcança resultados competitivos contra métodos baseados em ensaios, mesmo sem um buffer de ensaio.
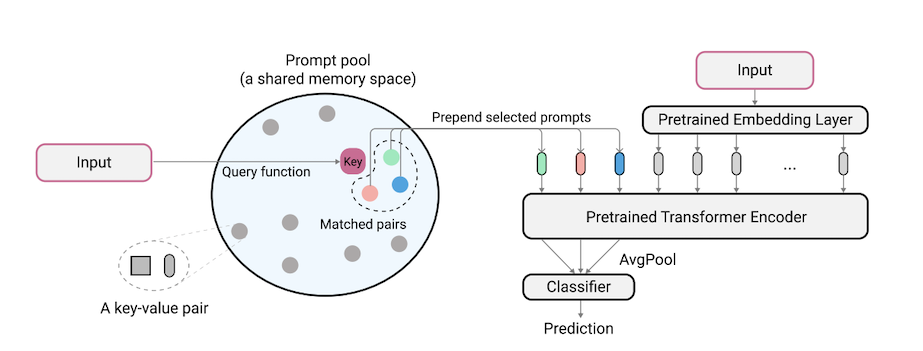
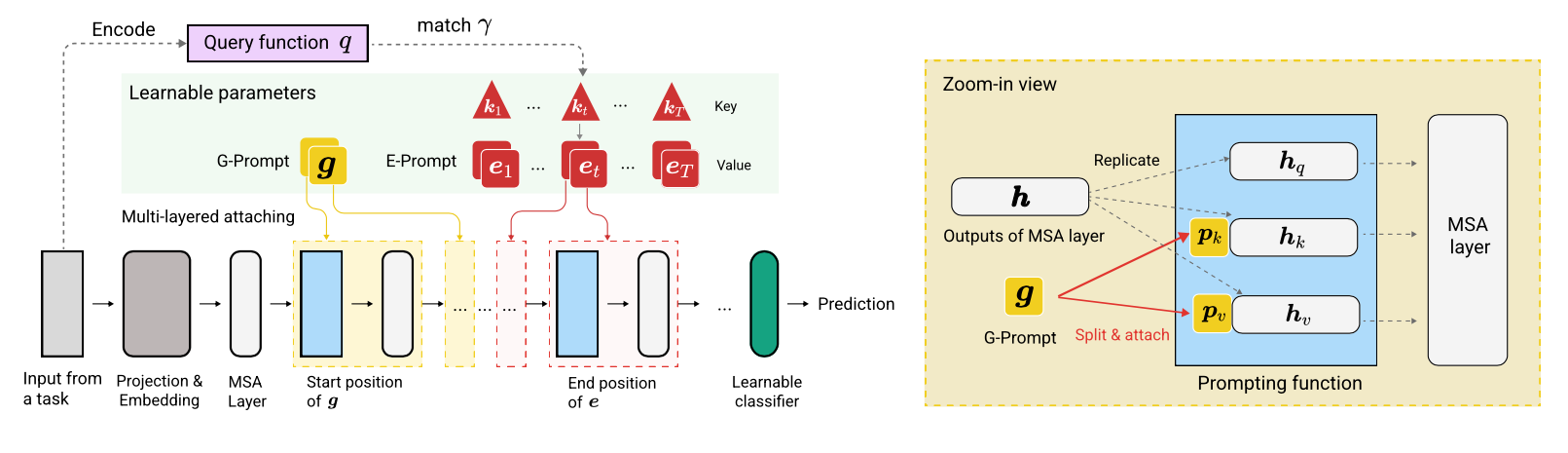
O código é escrito por Zifeng Wang. Reconhecimento em https://github.com/google-research/nested-transformer.
Este não é um produto do Google oficialmente suportado.
O benchmark Split ImageNet-R é construído no ImageNet-R, dividindo as 200 classes em 10 tarefas com 20 classes por tarefa, consulte Libml/input_piPeline.py para obter detalhes. Acreditamos que o Split ImageNet-R é de grande importância para a comunidade de aprendizagem contínua, pelos seguintes motivos:
A base de código foi reimplementada em Pytorch por Jaeho Lee em L2P-Pytorch e DualPrompt-Pytorch.
pip install -r requirements.txt
Depois disso, pode ser necessário ajustar sua versão JAX de acordo com a versão do driver CUDA, para que o JAX identifique corretamente suas GPUs (consulte este problema para obter mais detalhes).
NOTA: A base de código foi testada no TPU Enviroment usando a versão Jax mais recente. Atualmente, estamos trabalhando para verificar ainda mais o ambiente da GPU.
Antes de executar experimentos para 5-Datasets e Core50, a etapa adicional de preparação do conjunto de dados deve ser realizada da seguinte forma:
"PATH_TO_CORE50" e "PATH_TO_NOT_MNIST" em libml/input_pipeline.py pelos caminhos de destino na etapa 2 O modelo Vit-B/16 usado neste artigo pode ser baixado aqui. Nota: Nossa base de código realmente suporta vários tamanhos de VITs. Se você deseja experimentar variações de VITs, sinta -se à vontade para alterar o config.model_name nos arquivos de configuração, seguindo as opções válidas definidas em modelos/vit.py.
Fornecemos o arquivo de configuração para treinar e avaliar o L2P e o DualPrompt em vários benchmarks em configurações.
Para executar L2P em conjuntos de dados de benchmark:
python main.py --my_config configs/$L2P_CONFIG --workdir=./l2p --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
Onde $L2P_CONFIG pode ser um dos seguintes: [cifar100_l2p.py, five_datasets_l2p.py, core50_l2p.py, cifar100_gaussian_l2p.py] .
Nota: Executamos nossos experimentos usando 8 GPUs V100 ou 4 TPUs e especificamos um tamanho de lotes por dispositivo de 16 nos arquivos de configuração. Isso indica que usamos um tamanho total em lote de 128.
Para executar o DualPrompt nos conjuntos de dados de benchmark:
python main.py --my_config configs/$DUALPROMPT_CONFIG --workdir=./dualprompt --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
Onde $DUALPROMPT_CONFIG pode ser um dos seguintes: [imr_dualprompt.py, cifar100_dualprompt.py] .
Usamos o Tensorboard para visualizar o resultado. Por exemplo, se o diretório de trabalho especificado para executar o L2P for workdir=./cifar100_l2p , o comando para verificar o resultado é o seguinte:
tensorboard --logdir ./cifar100_l2p
Aqui estão as métricas importantes para acompanhar e seus significados correspondentes:
| Métrica | Descrição |
|---|---|
| precisão_n | Precisão da n-ésola |
| esquecendo | Esquecendo médio até a tarefa atual |
| avg_acc | Precisão de avaliação média até a tarefa atual |
@inproceedings{wang2022learning,
title={Learning to prompt for continual learning},
author={Wang, Zifeng and Zhang, Zizhao and Lee, Chen-Yu and Zhang, Han and Sun, Ruoxi and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and Pfister, Tomas},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={139--149},
year={2022}
}
@article{wang2022dualprompt,
title={DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning},
author={Wang, Zifeng and Zhang, Zizhao and Ebrahimi, Sayna and Sun, Ruoxi and Zhang, Han and Lee, Chen-Yu and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and others},
journal={European Conference on Computer Vision},
year={2022}
}


