rl 6 nimmt
1.0.0
6 Nimmt! é um jogo de cartas premiado para dois a dez jogadores de 1994. Citando a Wikipedia:
O jogo tem 104 cartas, cada uma com um número e um a sete símbolos de cabeças de touro que representam pontos de penalidade. Uma rodada de dez voltas é jogada, onde todos os jogadores colocam uma carta de sua escolha na mesa. Os cartões colocados são organizados em quatro linhas de acordo com as regras fixas. Se colocado em uma linha que já possui cinco cartas, o jogador recebe essas cinco cartas, que contam como pontos de penalidade que são totalizados no final da rodada.
6 Nimmt! é um jogo competitivo de informações incompletas e uma grande quantidade de estocasticidade. Jogar bem requer um pouco de planejamento. O jogo simultâneo se presta aos jogos e blefando, enquanto alguma estratégia de longo prazo é necessária para evitar acabar em posições difíceis no final do jogo.
Implementamos uma versão ligeiramente simplificada do 6 NIMMT! Como um ambiente de academia Openai. Ao contrário do jogo original, ao jogar uma carta mais baixa do que a última carta em todas as pilhas, o jogador não pode escolher livremente qual pilha para substituir, mas sempre levará a pilha com o menor número de pontos de penalidade.
Até agora, implementamos os seguintes agentes:
Como primeiro teste, realizamos um simples torneio de auto-jogo. Começando com cinco agentes não treinados, jogamos 4000 jogos no total. Para cada jogo, selecionamos aleatoriamente dois, três ou quatro agentes para jogar (e aprender). A cada 400 jogos, clonávamos o agente de melhor desempenho e expulsaram alguns dos pobres com desempenho. No final, mantivemos a melhor instância de cada tipo de agente.
Resultados em todos os jogos:
| Agente | Jogos jogados | Pontuação média | Ganhar fração | Elo |
|---|---|---|---|---|
| Alpha0.5 | 2246 | -7,79 | 0,42 | 1806 |
| MCS | 2314 | -8,06 | 0,40 | 1745 |
| Acer | 1408 | -12.28 | 0,18 | 1629 |
| D3qn | 1151 | -13.32 | 0,17 | 1577 |
| Aleatório | 1382 | -13,49 | 0,19 | 1556 |
É assim que o desempenho (medido no ELO) dos modelos desenvolvidos durante o curso do torneio:
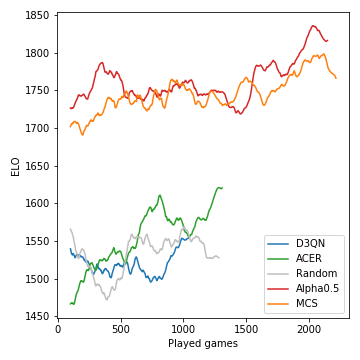
A busca de árvores de Monte-Carlo é crucial e leva a jogadores fortes. Os agentes de RL sem modelo, por outro lado, lutam para superar claramente a linha de base aleatória. Devido à natureza estocástica do jogo, as probabilidades de vitória e as diferenças ELO não são tão drásticas quanto poderiam ser, digamos, para o xadrez. Observe que não sintonizamos nenhum dos muitos hiperparâmetros.
Após esta fase de auto-jogo, o agente Alpha0.5 enfrentou Merle, um dos melhores 6 NIMMT! Jogadores em nosso grupo de amigos, por 5 jogos. Estas são as pontuações:
| Jogo | 1 | 2 | 3 | 4 | 5 | Soma |
|---|---|---|---|---|---|---|
| Merle | -10 | -16 | -11 | -3 | -4 | -44 |
| Alpha0.5 | -1 | -3 | -14 | -8 | -6 | -32 |
Supondo que você tenha instalado a Anaconda, clone o repo com
git clone [email protected]:johannbrehmer/rl-6nimmt.git
e criar um ambiente virtual com
conda env create -f environment.yml
conda activate rl
Tanto o agente se auto-jogam quanto os jogos entre um jogador humano e agentes treinados são demonstrados em simples_tournament.ipynb.
Juntos por Johann Brehmer e Marcel Gutsche.


