rlcard
RLCard 1.0.7
中文文档
O RLCARD é um kit de ferramentas para aprendizado de reforço (RL) em jogos de cartas. Ele suporta vários ambientes de cartões com interfaces fáceis de usar para implementar vários algoritmos de aprendizado de reforço e pesquisa. O objetivo do RLCARD é preencher a aprendizagem de reforço e os jogos de informação imperfeitos. O RLCARD é desenvolvido pelo Data Lab na Rice e na Texas A&M University e colaboradores da comunidade.
Comunidade:
Notícias:
Os jogos a seguir são desenvolvidos e mantidos principalmente pelos colaboradores da comunidade. Obrigado!
Agradeça a todos os colaboradores!




























Se você achar esse repositório útil, pode citar:
Zha, Daochen, et al. "RLCARD: uma plataforma para aprendizado de reforço em jogos de cartas". Ijcai. 2020.
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
} Certifique -se de ter o Python 3.6+ e o PIP instalado. Recomendamos instalar a versão estável do rlcard com pip :
pip3 install rlcard
A instalação padrão incluirá apenas os ambientes de cartão. Para usar a implementação de Pytorch dos algoritmos de treinamento, execute
pip3 install rlcard[torch]
Se você estiver na China e o comando acima é muito lento, pode usar o espelho fornecido pela Universidade de Tsinghua:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
Como alternativa, você pode clonar a versão mais recente com (se estiver na China e o Github é lento, você pode usar o espelho em Gitee):
git clone https://github.com/datamllab/rlcard.git
ou apenas clone um ramo para torná -lo mais rápido:
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
Em seguida, instale com
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
Também fornecemos o método de instalação do CONDA :
conda install -c toubun rlcard
A instalação do CONDA fornece apenas os ambientes de cartão, você precisa instalar manualmente o Pytorch em suas demandas.
Um pequeno exemplo é o abaixo.
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()O RLCARD pode ser conectado com flexibilidade a vários algoritmos. Veja os seguintes exemplos:
Execute examples/human/leduc_holdem_human.py para brincar com o modelo Leduc Hold'em pré-treinado. Leduc Hold'em é uma versão simplificada do Texas Hold'em. As regras podem ser encontradas aqui.
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
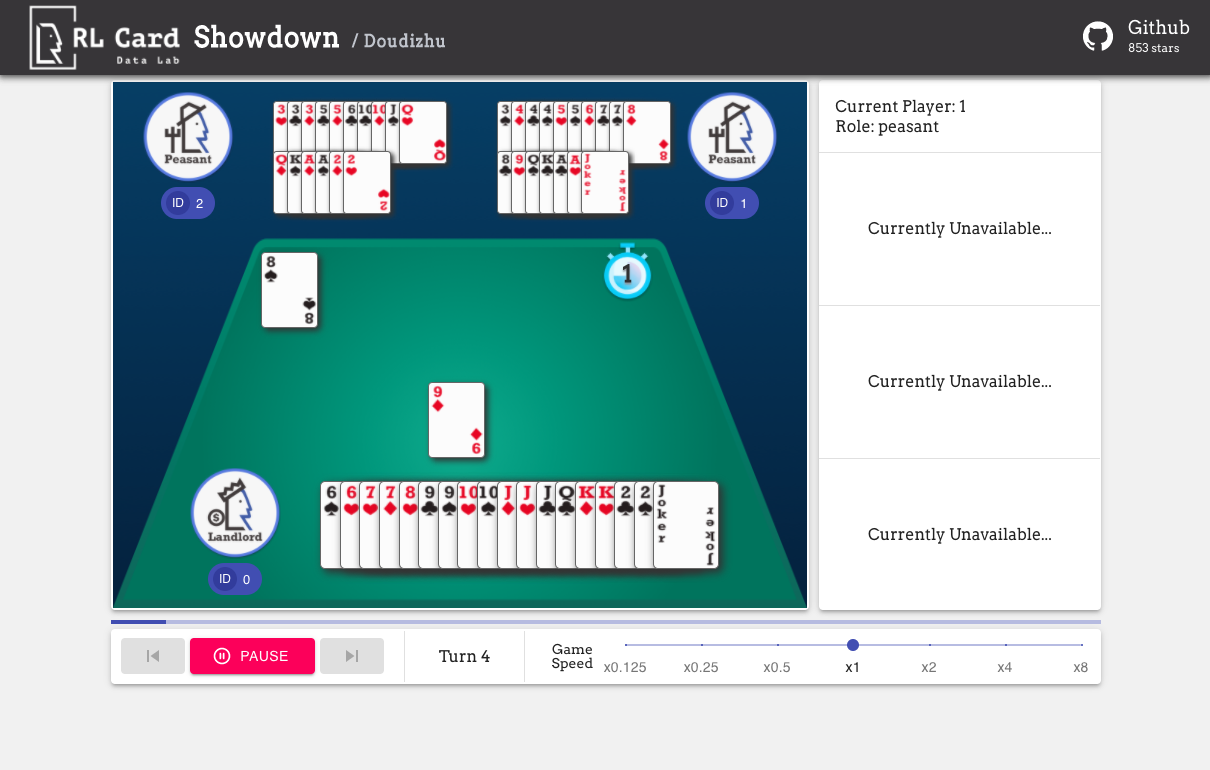
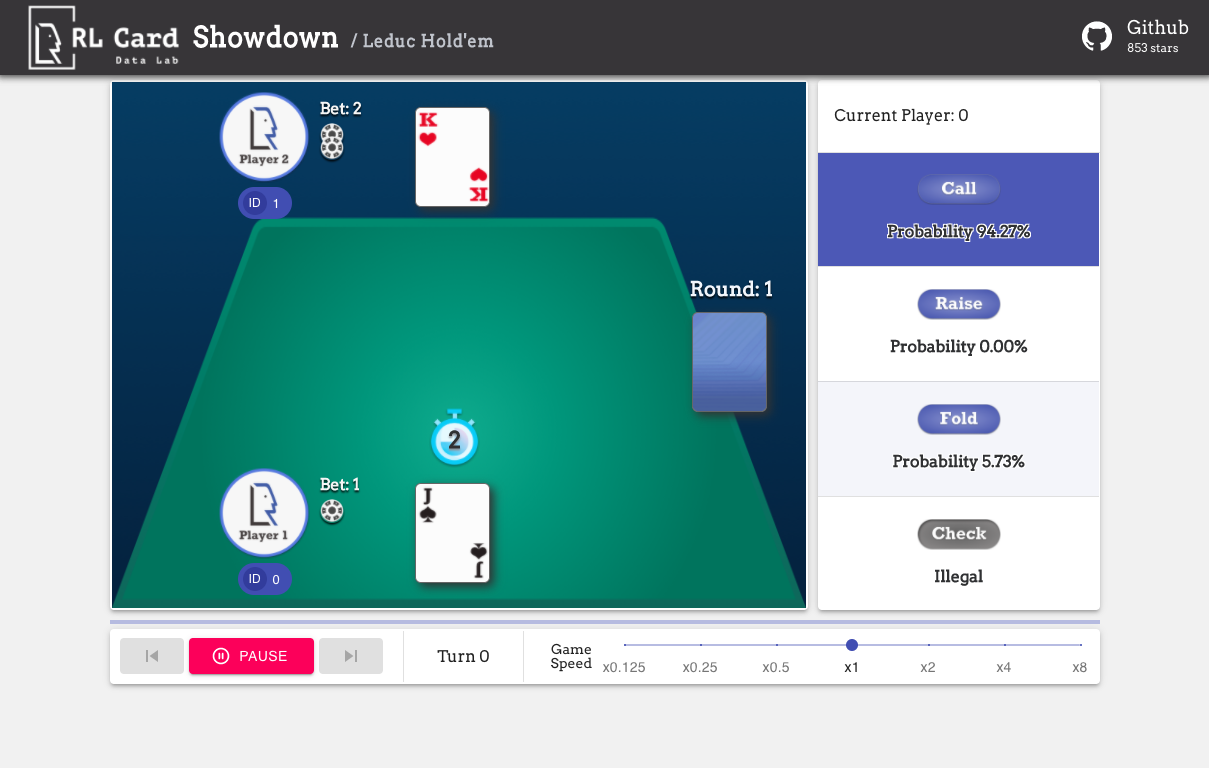
Também fornecemos uma GUI para facilitar a depuração. Por favor, verifique aqui. Algumas demos:
Fornecemos uma estimativa de complexidade para os jogos em vários aspectos. Número do InfoSet: o número de conjuntos de informações; Tamanho do InfoSet: o número médio de estados em um único conjunto de informações; Tamanho da ação: o tamanho do espaço de ação. Nome: O nome que deve ser passado para rlcard.make para criar o ambiente do jogo. Também fornecemos o link para a documentação e o exemplo aleatório.
| Jogo | Número do InfoSet | Tamanho do InfoSet | Tamanho da ação | Nome | Uso |
|---|---|---|---|---|---|
| Blackjack (Wiki, Baike) | 10^3 | 10^1 | 10^0 | Blackjack | Doc, exemplo |
| Leduc Hold'em (papel) | 10^2 | 10^2 | 10^0 | Leduc-Holdem | Doc, exemplo |
| Limite Texas Hold'em (Wiki, Baike) | 10^14 | 10^3 | 10^0 | Limite-Holdem | Doc, exemplo |
| Dou Dizhu (Wiki, Baike) | 10^53 ~ 10^83 | 10^23 | 10^4 | Doudizhu | Doc, exemplo |
| Mahjong (Wiki, Baike) | 10^121 | 10^48 | 10^2 | Mahjong | Doc, exemplo |
| No-limite Texas Hold'em (Wiki, Baike) | 10^162 | 10^3 | 10^4 | sem limite-holdem | Doc, exemplo |
| Uno (Wiki, Baike) | 10^163 | 10^10 | 10^1 | Uno | Doc, exemplo |
| Gin Rummy (Wiki, Baike) | 10^52 | - | - | gin-rummy | Doc, exemplo |
| Ponte (wiki, Baike) | - | - | ponte | Doc, exemplo |
| Algoritmo | exemplo | referência |
|---|---|---|
| Deep Monte-Carlo (DMC) | Exemplos/run_dmc.py | [papel] |
| Deep Q-Learning (DQN) | Exemplos/run_rl.py | [papel] |
| Auto-jogada fictícia neural (NFSP) | Exemplos/run_rl.py | [papel] |
| Minimização de arrependimento contrafactual (CFR) | Exemplos/run_cfr.py | [papel] |
Fornecemos um zoológico modelo para servir como linhas de base.
| Modelo | Explicação |
|---|---|
| Leduc-Holdem-CFR | Modelo de CFR (Chance Sampling) pré-treinado no Leduc Hold'em |
| Leduc-Holdem-Rule-V1 | Modelo baseado em regras para leduc hold'em, v1 |
| Leduc-Holdem-Rule-V2 | Modelo baseado em regras para Leduc Hold'em, v2 |
| UNO-RULE-V1 | Modelo baseado em regras para Uno, v1 |
| Limite-Holdem-Rule-V1 | Modelo baseado em regras para limite Texas Hold'em, v1 |
| DOUDIZHU-RULE-V1 | Modelo baseado em regras para Dou Dizhu, v1 |
| Gin-rummy-novice-regra | Modelo de regra iniciante em gin rummy |
Você pode usar a interface a seguir para criar um ambiente. Opcionalmente, você pode especificar algumas configurações com um dicionário.
env_id é uma sequência de um ambiente; config é um dicionário que especifica algumas configurações de ambiente, que são as seguintes.seed : Padrão None . Defina um ambiente semente aleatória local para reproduzir os resultados.allow_step_back : padrão False . True se permitir que a função step_back atravesse para trás na árvore.game_ . Atualmente, apoiamos apenas game_num_players no Blackjack ,.Depois que o ambiente é feito, podemos acessar algumas informações do jogo.
Estado é um dicionário de Python. Consiste em state['obs'] , ações legais state['legal_actions'] , state['raw_obs'] e ações legais brutas state['raw_legal_actions'] .
As interfaces a seguir fornecem um uso básico. É fácil de usar, mas tem supostas no agente. O agente deve seguir o modelo do agente.
agents é uma lista de objeto Agent . A duração da lista deve ser igual ao número de jogadores do jogo.set_agents . Se is_training for True , ele usará a função step no agente para jogar o jogo. Se is_training for False , eval_step será chamado.Para uso avançado, as interfaces a seguir permitem operações flexíveis na árvore de jogos. Essas interfaces não fazem nenhuma suposição sobre o agente.
action pode ser ação bruta ou número inteiro; raw_action deve ser True se a ação for a ação bruta (string).allow_step_back é True . Dê um passo para trás. Isso pode ser usado para algoritmos que operam na árvore de jogos, como CFR (Chance Sampling).True se o jogo atual terminar. Otherewise, retornar False .player_id .Os propósitos dos módulos principais estão listados como abaixo:
Para mais documentação, consulte os documentos para apresentações gerais. Os documentos da API estão disponíveis em nosso site.
A contribuição para este projeto é muito apreciada! Crie um problema para feedbacks/bugs. Se você deseja contribuir com códigos, consulte o guia contribuinte. Se você tiver alguma dúvida, entre em contato com Daochen Zha com [email protected].
Gostaríamos de agradecer à JJ World Network Technology Co., Ltd pelo apoio generoso e a todas as contribuições dos colaboradores da comunidade.


