kubeai
helm-chart-models-0.9.0
Obtenha o inferno de corrida em Kubernetes: LLMS, incorporação, fala para texto.
✅️ Substituição de entrega para o OpenAI pela compatibilidade da API
⚖️ Escala de zero, autocale com base na carga
? Sirva modelos de geração de texto (LLMS, VLMS, etc.)
API de fala para texto
? API de incorporação/vetor
Multi-plataforma: somente CPU, GPU, TPU
? Modelo em cache com sistemas de arquivos compartilhados (EFS, FileStore, etc.)
Zero dependências (não depende de Istio, Knative, etc.)
Interface de chat incluída (OpenWebui)
? Opera os servidores de modelos OSS (VLLM, Ollama, mais rápido, infinito)
✉ Inferência de fluxo/lote através de integrações de mensagens (Kafka, Pubsub, etc.)
Citações da comunidade:
Solução reutilizável e bem abstraída para executar o LLMS - Mike Ensor
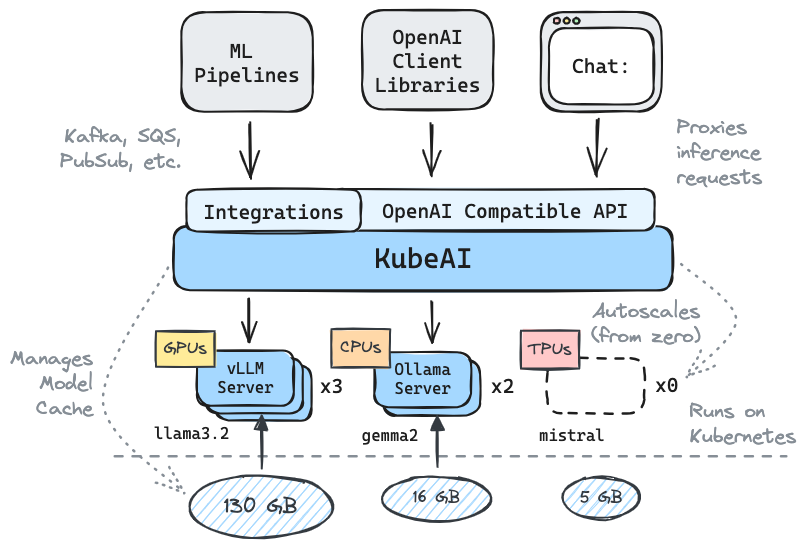
O KUBEAI serve uma API HTTP compatível com o OpenAI. Os administradores podem configurar os modelos ML via kind: Model Kubernetes Recursos personalizados. O KUBEAI pode ser considerado um operador de modelo (consulte o padrão do operador) que gerencia servidores VLLM e Ollama.
Crie um cluster local usando gentil ou minikube.
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startAdicione o repositório Kubeai Helm.
helm repo add kubeai https://www.kubeai.org
helm repo updateInstale o Kubeai e aguarde que todos os componentes estejam prontos (pode levar um minuto).
helm install kubeai kubeai/kubeai --wait --timeout 10mInstale alguns modelos predefinidos.
cat << EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yamlAntes de progredir para as próximas etapas, inicie um relógio nos pods em um terminal independente para ver como o Kubeai implanta modelos.
kubectl get pods --watch Porque definimos minReplicas: 1 Para o modelo Gemma, você deve ver uma cápsula de modelo já chegando.
Comece uma porta de porta local para a interface do usuário de bate-papo.
kubectl port-forward svc/openwebui 8000:80Agora abra seu navegador para localhost: 8000 e selecione o modelo Gemma para começar a conversar.
Se você voltar ao navegador e iniciar um bate -papo com o QWEN2, notará que levará um tempo para responder primeiro. Isso ocorre porque definimos minReplicas: 0 para este modelo e o Kubeii precisa aumentar uma nova pod (você pode verificar com kubectl get models -oyaml qwen2-500m-cpu ).
Confira nossa documentação no kubeii.org para encontrar informações sobre:
Lista de adotantes conhecidos:
| Nome | Descrição | Link |
|---|---|---|
| Telescópio | O Telescope usa o Kubeii para inferência de lote de grande escala em grande escala LLM. | TRYTELESCOPE.AI |
| Google Cloud Distributed Edge | Kubeai é incluído como uma arquitetura de referência para inferir na borda. | LinkedIn, Gitlab |
| Lambda | Você pode experimentar o Kubeai na nuvem de desenvolvedores da Lambda AI. Veja o tutorial e o vídeo de Lambda. | Lambda |
Se você estiver usando o Kubeai e gostaria de ser listado como adotante, faça um PR.
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/* NOTA: Kubeai nasceu de um projeto chamado Lingo, que era um proxy simples da Kubernetes LLM com autoscaling básico. Reiniciamos o projeto como Kubaii (final de agosto de 2024) e expandimos o roteiro para o que é hoje.
? Não se esqueça de nos deixar uma estrela no Github e siga o repositório para se manter atualizado!
Informe -nos sobre os recursos que você está interessado em ver ou procurar perguntas. Visite nosso canal Discord para participar da discussão!
Ou basta entrar em contato no LinkedIn se você quiser se conectar:


