TTS Generation Webui / gaita
Baixe o instalador || Instalação || Configuração do Docker || Relatórios de feedback / bug
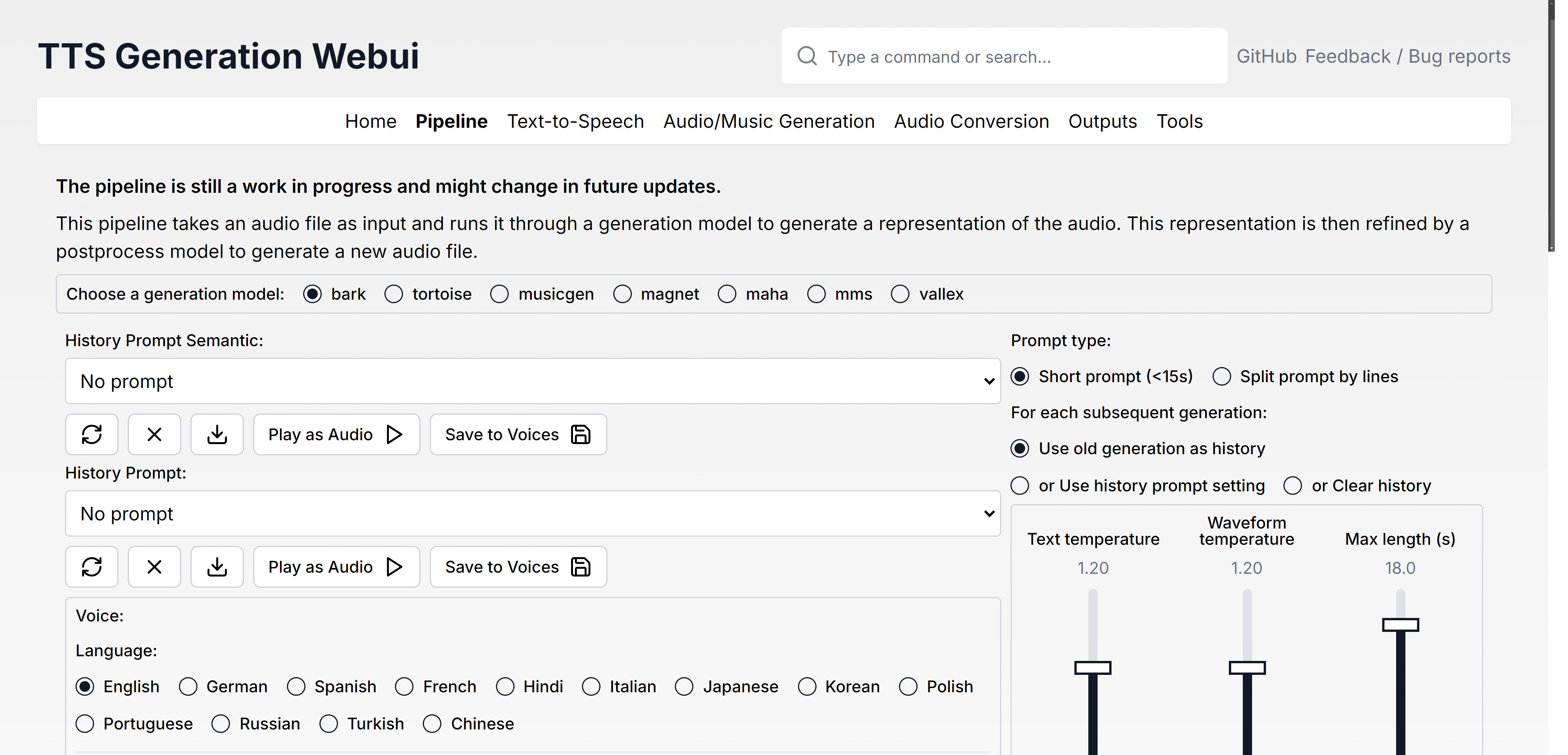
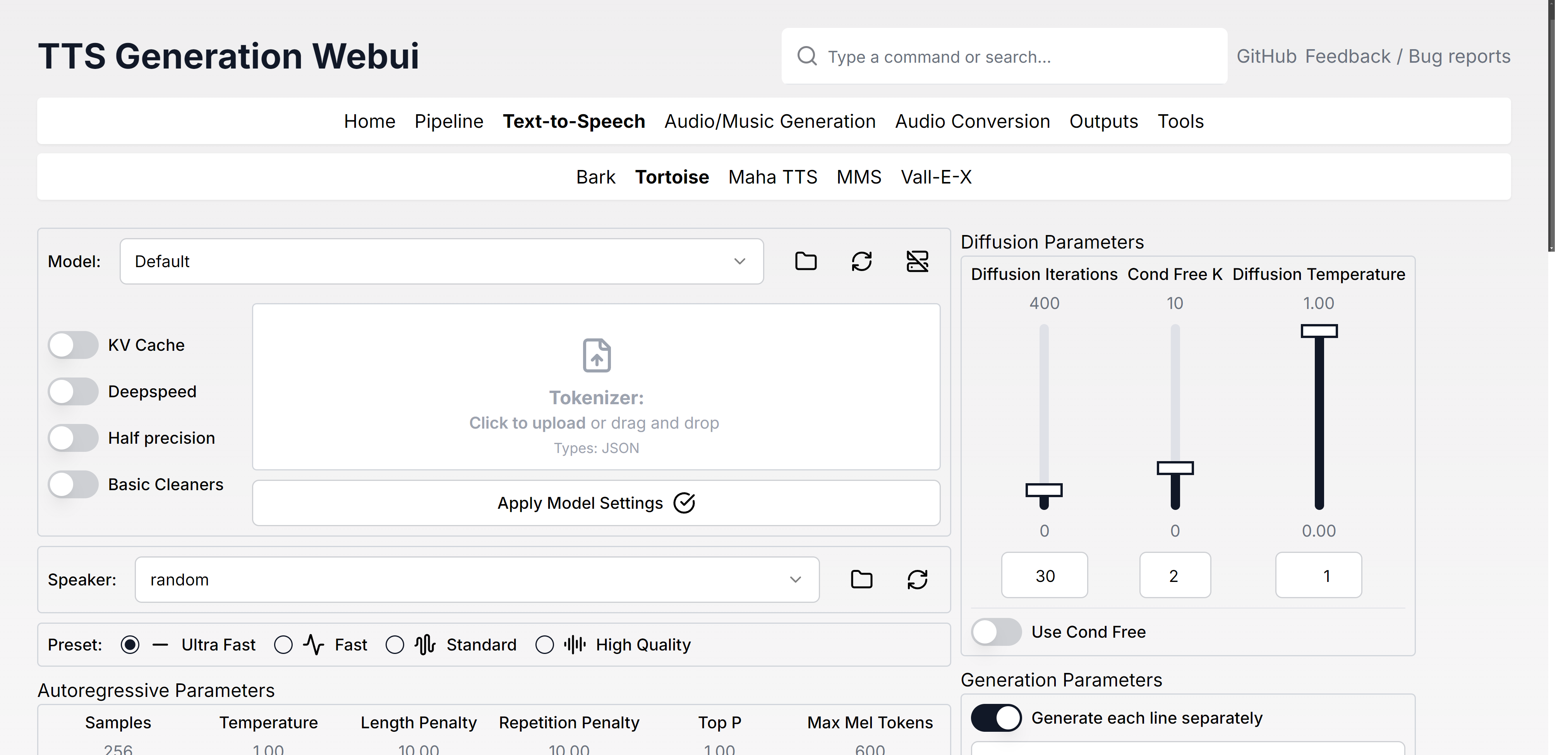
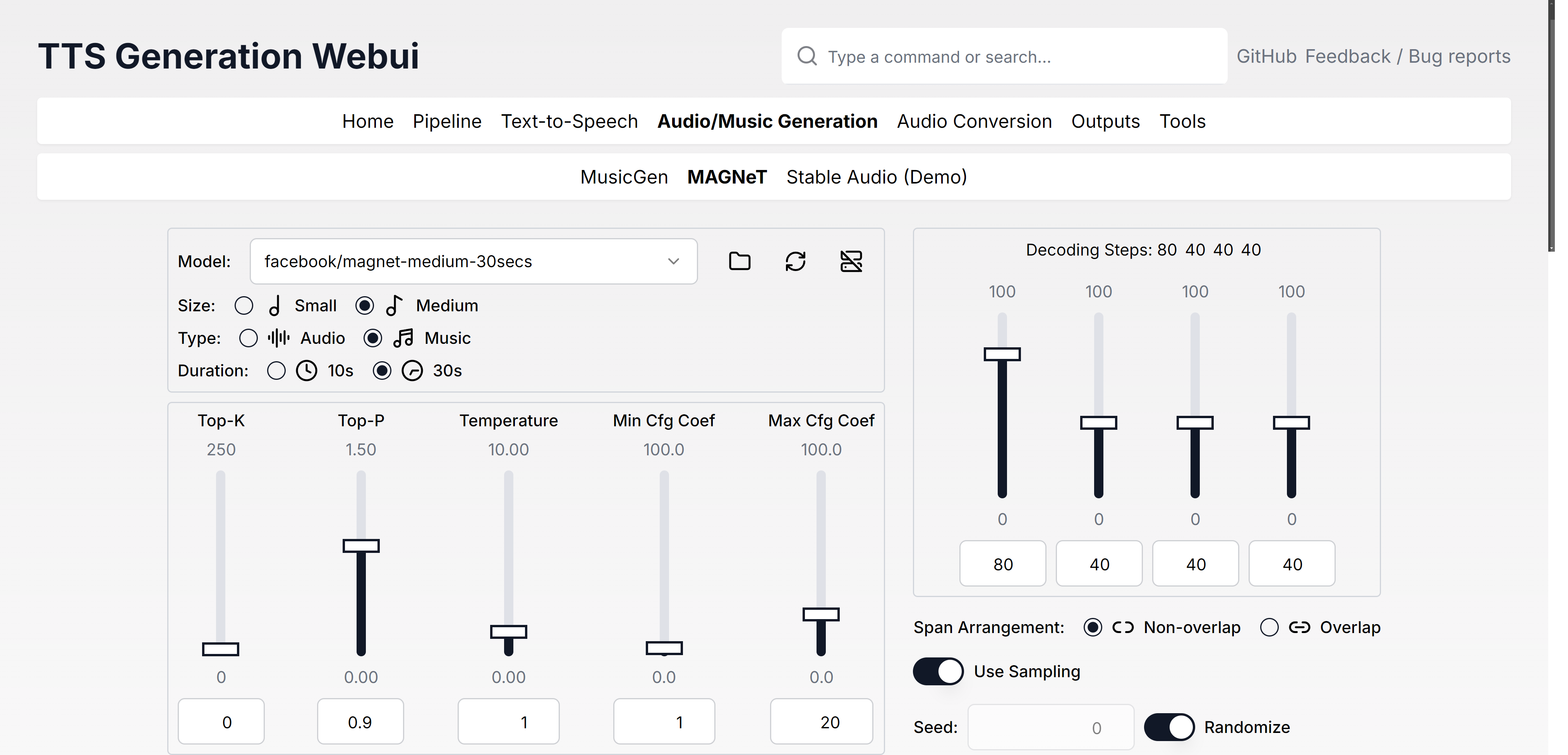
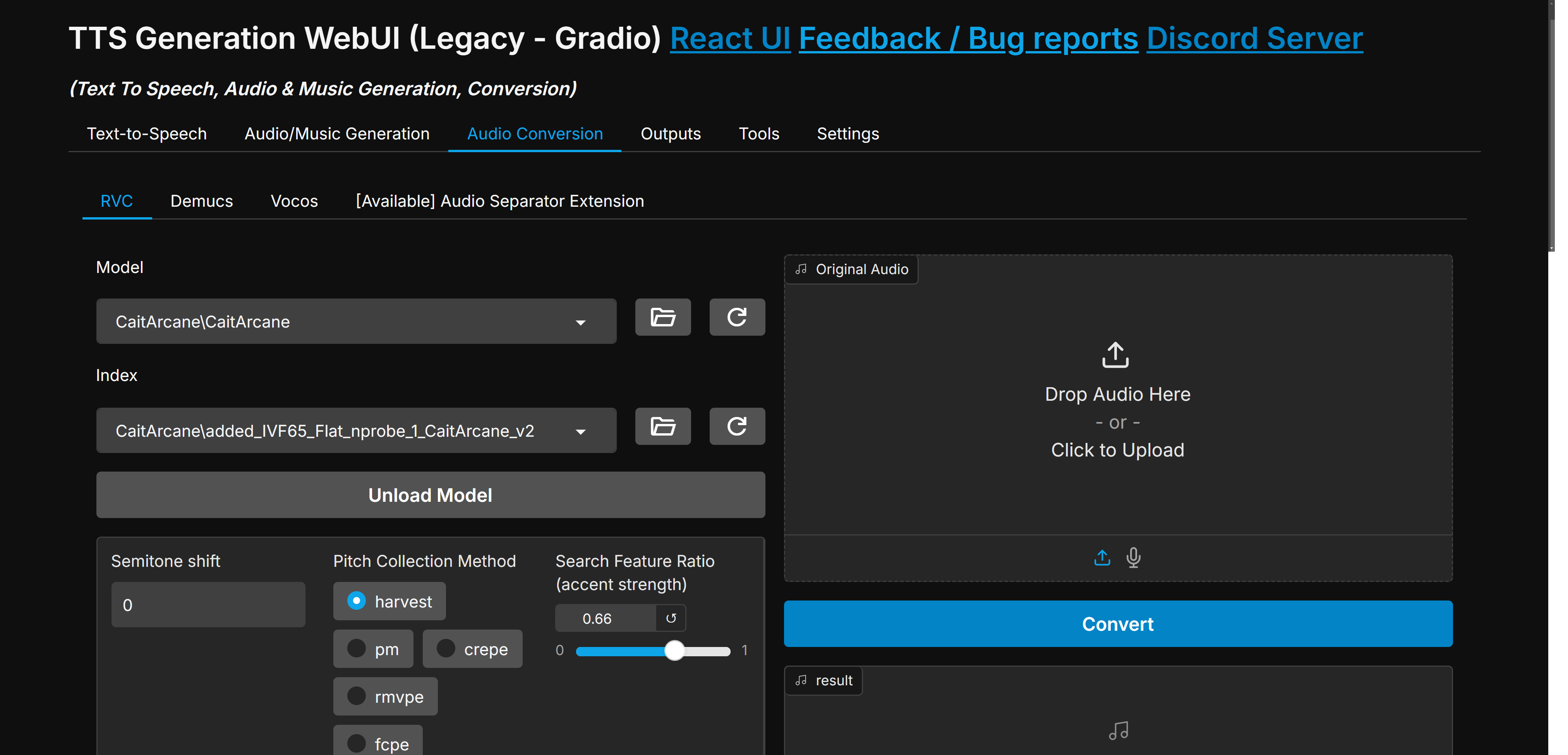
Modelos
| Texto para fala | Geração de áudio/música | Conversão de áudio/ferramentas |
|---|
| Latido | MusicGen | Rvc |
| Tartaruga | Ímã | Demucs |
| Maha tts | Áudio estável | Vocos |
| Mms | (Extensão) rifusão | Sussurrar |
| Vall-e x | (Extensão) Audiocraft Mac | |
| Styletts2 | (Extensão) Audiocraft Plus | |
| Seamlessm4t | | |
| (Extensão) XTTSV2 | | |
| (Extensão) Mars5 | | |
| (Extensão) F5-TTS | | |
| (Extensão) Parler TTS | | |
Bark.Narration.MP4 | Bark.Japanese.mp4 | MusicGen.MP4 |
|---|
Changelog
23 de novembro:
- Adicione a roda Linux Fairseq para melhor compatibilidade do PIP.
22 de novembro:
- Alterne para as rodas, adicione o prompt de instalação de um tiro.
15 de novembro:
- Atualize para o graduado 5.5.0, adicione a aparência de aprimoramento (#420)
14 de novembro:
- Adicione a roda experimental do Windows Deepspeed.
- Adicione mais idiomas ao clone de voz de casca.
11 de novembro:
- Mude para uma versão Fairseq fixa para o Windows reduzindo conflitos de instalação e acelerando as atualizações.
Outubro de 2024
28 de outubro:
- Testes de instalador adicionados, downloader modelo e opção PIP CPU apenas para tocha.
24 de outubro:
- Rebaixou graduio para 5.1.0 devido a um bug.
- Adicionados fluxos de trabalho de teste e corrigidos pequenos erros.
22 de outubro:
- Corrigidos problemas do Dockerfile para implantação mais suave.
21 de outubro:
- Readme redesenhado: extensão de sussurro aprimorada, alterações adicionadas para agosto, setembro e outubro, capturas de tela atualizadas e conteúdo reorganizado.
19 de outubro:
- Fixos de extensão fixa e adicionaram novas extensões.
18 de outubro:
- Melhorias do sistema: Projeto formatado, instalação fixa
xformers+cuda , sistema de log adicionado, botão de extensão de desinstalação e extensão F5 TTS.
16 de outubro:
- A primeira instalação agora usa
pip em vez de uv . - Versão principal bateu e corrigido o Google Colab.
- Adicionado pip fallback ao áudio estável.
- Demucs fixos, trocou a porta Postgres.
- Corrigido
huggingface_hub Instalar e Bark Model Loader. - Principais atualizações: mudou para o graduado 5, carregamento preguiçoso para guias, correções do docker, velocidade da interface do usuário otimizada, recurso adicionado .env.User, logs aprimorados e extensões de interface do UI do React atualizado.
3 de outubro:
- Corrigida a guia Informações da GPU e adicionou
nvidia-ml-py . - Criou uma solução alternativa para o Bug de instalação do Audiocraft.
- Corrigido o MSVC automático MSVC e defina servidor para
127.0.0.1 . - Caminho
.git_version corrigido e removeu iconv para eliminar o requisito node-gyp . - Manuseio de erro do instalador aprimorado, adicionou o log de hash de atualização.
- Node.js atualizado para 22.9.0, Adicionado suporte PostgreSQL, guias agrupadas na UI do React.
Setembro de 2024
Clique para expandir
23 de setembro:
- Use automaticamente CUDA para MMS.
22 de setembro:
- Adicionada extensão de metadados FFMPEG para reagir a interface do usuário.
- Adicionado aviso somente mono para Maha TTS.
- Hotfix para evitar o nó 20.17.0 Falha na instalação.
21 de setembro:
- Adicionado demonstração de áudio estável para reagir a interface do usuário.
- Layout da interface do usuário aprimorado.
19 de setembro:
- Atualizada React UI visual visual com novos controles deslizantes e melhor layout.
- Otimizado RVC UI, colab fixo e adicionou uma caixa de comando de pesquisa.
- Atualizar node.js para 20.17.0.
2 de setembro:
- Dockerfile corrigido e atualizado Docker-Compose.yml.
- Corrigido o bug no carregamento NPZ.
Agosto de 2024
Clique para expandir
31 de agosto:
- Upgrade Model Inference Framework para decoradores.
- Move os arquivos Python da pasta
src para tts_webui . - Reescreva a guia MusicGen e corrigiu erros relacionados.
20 de agosto:
- Atualizado para o Gradio 4 e Adicionado tema.
- Adicionado mensagens de carregamento de modelo para tartaruga.
- RVC do Reactui corrigido.
- REFATORADO HIPERPARAMETERS.
- Lista de gerenciamento às extensões adicional, Extensão XTTS-Simple.
5 de agosto:
- Corrija a casca na interface do usuário do React, adicione a duração da geração máxima.
- Altere o diretório de modelos de extensão Audiocraft Plus para ./data/models/audiocraft_plus/
- Melhore o descarregamento do modelo para MusicGen e Audiogen. Adicione o botão Modelos de descarga ao MusicGen e Audiogen.
- Adicione a extensão do HuggingFace Cache Manager.
4 de agosto:
- Adicione a extensão XTTS-RVC-UI, XTTS Extensão de demonstração de ajuste fino.
3 de agosto:
- Adicione a extensão da riffusão, a extensão do Audiocraft Mac, a extensão herdada da casca.
2 de agosto:
- Adicione aviso de depreciação ao antigo instalador.
- Unifique o manuseio de erros e simplifique o carregamento da guia.
1 de agosto:
- Adicione o botão "Tente Atualizar" para extensões externas.
- Skip Reinstalando os pacotes quando a versão pip_packages não é alterada.
- Sincronize a porta Gradio com a UI do React.
- Altere a porta graduada padrão para 7770 de 7860.
Julho de 2024
Clique para expandir
31 de julho:
- Corrija o React UI's MusicGen após a mudança de graduação.
- Adicione o botão de descarga à extensão do sussurro.
29 de julho:
- Altere o FFMPEG para 4.4.2 de Conde-Forge para suportar mais plataformas, incluindo o Mac M1.
- Desative a tartaruga cvvp.
26 de julho:
- Extensão do sussurro
- Suporte experimental de instalação da AMD ROCM. (Somente Linux)
25 de julho:
- Adicione scripts de diagnóstico para macOS e Linux.
- Adicione melhores detalhes de erro para guias.
- Corrija as permissões de execução de script .sh para os instaladores no Linux e MacOS.
21 de julho:
- Adicione a Extensão do Histórico da Galeria (adaptado da Visualização da Galeria antiga)
- Converter remixer simples em extensão
- Fix update.py para usar as versões mais recentes da tocha (update.py é apenas para fins herdados e provavelmente quebrará)
- Adicione o script de diagnóstico e a força reinstale os scripts para Windows.
20 de julho:
- Corrigir link de junção de discórdia
- Simplifique ainda mais a casca, removendo a complexidade excessiva no código.
- Adicione extensões de interface do usuário/modular, essas extensões permitem a instalação de novos modelos e recursos na interface do usuário. No futuro, os modelos começarão como extensões antes de serem adicionados com permaceres.
- Desativar a vista da galeria em saídas
- Problema conhecida: o Firefox falha ao mostrar saídas em Gradio, falha em buscá -las no back -end. Dentro do React UI, isso funciona bem.
15 de julho:
- Comentário - Como a interface do reacto está fora há muito tempo, a UI do graduação terá o papel de cumprir apenas as funções para o usuário, sem a interface do usuário extremamente complicada que não pode lidar. Há uma verdadeira escassez de tempo de desenvolvimento para adicionar novos modelos e recursos, mas o estilo antigo de integração não foi viável. Como as novas APIs e 'o papel do modelo' são definidas, será possível ter extensões para modelos inteiros, permitindo muito mais flexibilidade e instalações mais leves.
- Inicie a redução da complexidade da interface do graduação Gradio - Removido Enviar para os botões RVC/Demucs/Voice . (Remova o componente interno joutai).
- Adicionar versão.json para melhores atualizações no futuro.
- Reduza o número máximo de saídas da casca de graduação para 1.
- Adicione o botão de modelo de descarga à tartaruga, também descarregue o modelo antes de carregar os próximos parâmetros/alterações, portanto, a tartaruga não usa mais a memória do modelo 2x durante as configurações mudam.
14 de julho:
- Reagrupar as guias Gradio em grupos - texto para fala, conversão de áudio, geração de música, saídas e configurações
- Limpe o cabeçalho, adicione o link para feedback
- Adicione o controle de sementes ao áudio estável
- Corrija o bug estável de nome do arquivo de áudio com as novas linhas
- Desativar a guia Gradio "Remixer simples"
- Corrigir clone de voz de casca e RVC mais uma vez
- Adicione a guia "Pacotes instalados" para depuração
13 de julho:
- Atualização principal para a tocha 2.3.1 e Xformers 0.0.27
- Todos os usuários, incluindo Mac e CPU, agora terão a mesma versão Pytorch.
- Atualizar CUDA para 11,8
- Force Python a ser 3.10.11
- Modifique o instalador para permitir a atualização do Python e a tocha sem reinstalar (atualmente a maior versão 2)
- Corrigir parâmetros padrão do ímã para melhor qualidade
- Melhore as verificações de script do instalador para evitar bugs
- Atualizar Styletts2
11 de julho:
- Melhorar os nomes de arquivos de geração de áudio estáveis
- Adicionar força reinstalar ao reparo da tocha
- Faça do instalador atualizar automaticamente antes de executar
9 de julho:
- Corrija novas instruções de instalador e instalação graças a https://github.com/xeraster!
8 de julho:
- Altere o processo de instalação para reduzir os conflitos de pacotes e ativar a flexibilidade da versão da tocha.
6 de julho:
- Liberação inicial do novo instalador baseado em Mamba.
- Salve os resultados estáveis de áudio na pasta Saídas-RVC/StableAudio.
- Adicione um aviso à seleção estável do modelo de áudio e mostre melhores mensagens de erro quando os arquivos estiverem ausentes.
1 de julho:
- Otimize o uso estável da memória de áudio após a geração.
- Abra o React UI automaticamente apenas se Gradio também abrir automaticamente.
- Remova a reinstalação desnecessária do conda.
- Atualizar para o último áudio estável, que possui suporte de MPS (requer versões mais recentes da tocha).
Junho de 2024
Clique para expandir
22 de junho: * Adicione áudio estável ao Gradio. 21 de junho:
- Adicione a demonstração do Vall-Ex para reagir a interface do usuário.
- Abra o React UI automaticamente no navegador, corrija o link novamente.
- Adicione a divisão por comprimento para reagir/tartaruga.
- Corrija as pastas de demonstração UVR5.
- Defina a versão Fairseq como 0.12.2 para Linux e Mac. (#323)
- Melhore o histórico de geração para todas as guias da interface do reacto.
17 de maio:
- Fixar predefinições de tartaruga na interface do reação.
9 de maio:
- Adicione MMS para reagir a interface do usuário.
- Melhorar a interface do reacto e a base de código.
4 de maio:
Abril de 2024
Clique para expandir
28 de abril: * Adicione o maha tts para reagir a interface do usuário. * Adicione informações da GPU para reagir a interface do usuário. 6 de abril:
- Adicione a guia Demoção de geração Vall-Ex.
- Adicione a guia Demo MMS.
- Adicione a guia Demo Maha TTS.
- Adicione a guia Demo Styletts2.
5 de abril:
- Corrija o bug de instalação do RVC.
- Adicione a guia de demonstração básica do UVR5.
4 de abril:
- Atualize o RVC para incluir RVMPE e FCPE. Remova a entrada do arquivo direto para modelos e índices devido à duplicação de arquivos. Melhore a interface React UI para RVC.
Março de 2024
Clique para expandir
28 de março:
- Adicione a guia Informações da GPU
27 de março:
- Adicione informações sobre a clonagem de voz ao clone de voz da guia
26 de março:
- Adicionar notebook de demonstração Maha TTS
22 de março:
- Vall-e X Demo via notebook (#292)
- Adicionar react ui à imagem do docker
- Adicione o Isengurador de Instalação
16 de março:
- Atualizar vocos para 0,1.0
14 de março:
- Notebook de demonstração Styletts2
13 de março:
- Adicione oleoduto experimental (Bark / Tortoise / MusicGen / Audiogen / Magnet -> RVC / Demucs / Vocos) (#287)
- Corrija o bug RVC com o recarreamento do modelo em cada geração. Para insumos curtos que resultam em uma aceleração visível.
11 de março:
- Adicione a reprodução como áudio e salve às vozes para a casca (#286)
- Altere o UX para mostrar que os arquivos são excluídos dos favoritos
- Corrija imagens para vozes de casca que não mostram
- Corrija a reprodução de áudio em favoritos
10 de março:
- Adicione lotes ao React UI Magnet (#283)
- Adicione áudio à tradução de áudio ao SeamlessM4T (#284)
5 de março:
- Adicione lotes ao React UI MusicGen (#281), graças a https://github.com/aamir3d por solicitar isso e fornecer feedback
3 de março:
- Adicione a demonstração do MMS como um caderno
- Adicione a Isenção de Isenção de VRAM de MultiBandDiffusion High
Fevereiro de 2024
Clique para expandir
21 de fevereiro:
- Corrija as compilações de contêiner do Docker com o Docker-Audiocraft
8 de fevereiro:
- Corrija o MultiBandDiffusion para os modelos estéreo da MusicGen, obrigado https://github.com/mykeehu
- Corrija as etapas de instalação do Node.js no Google Colab, código por https://github.com/miaohf
6 de fevereiro:
- Adicionar extensão de geração de arquivos FLAC por https://github.com/Joachip
Janeiro de 2024
Clique para expandir
21 de janeiro:
- Adicione o script de reparo automático da CPU/M1 com cada atualização. Para desativar, editar check_cuda.py e alterar force_no_repair = true
16 de janeiro:
- Atualizar MusicGen, adicionando suporte para modelos estéreo e de melodia grandes
- Adicione ímã
15 de janeiro:
- Graduou Gradio para 3.48.0
- Vários bugs visuais apareceram, se forem críticos, denuncie -os ou downgrade Gradio.
- Gradio: suprimir avisos inúteis
- AVISOS SUPRESS TRITON
- Gradio-Bark: Fix "Use o comportamento da última geração como história", seleção vazia não mais erros
- Melhore a exibição do carregador de extensões
- Atualizar transformadores para 4.36.1 a partir de 4.31.0
- Adicione a demonstração sem costura
14 de janeiro:
- Reactar a interface do usuário: corrige erros de diretório ausentes
13 de janeiro:
- Reactar a interface do usuário: corrige a etapa de construção do NPM ausente na instalação automática
12 de janeiro:
- Reactar a interface do usuário: corrija nomes para ações de áudio
- Gradio: corrija vários avisos da API
- Integração - a react ui agora é lançada ao lado de Gradio, com um link para abri -lo
11 de janeiro:
- Reactar a interface do usuário: faça a construção funcionar sem erros
9 de janeiro:
- Reaja a interface do usuário
- Corrigir 404 manipulador para ondas
- Guias de casca de grupo juntas
8 de janeiro:
2023
Clique para expandir
Outubro de 2023
26 de outubro:
- Melhore a seleção de modelo UX para MusicGen
24 de outubro:
- Adicione a interface do reação inicial para MusicGen e Demucs (#202)
- Corrija Drifting de sementes de longa geração da casca (graças a https://github.com/520pig520)
Setembro de 2023
21 de setembro:
- Casca: adicione continue como botão de história semântica
- Mude para o armazenamento de imagem do Docker do Github, nova imagem do Docker:
-
docker pull ghcr.io/rsxdalv/tts-generation-webui:main
- Corrigir a opção Server_port na Config #168, graças a https://github.com/dartvauder
9 de setembro:
- Corrija a linha de comando XDG-Open, graças a https://github.com/jfronny
- Corrija gerações de casca de várias linhas, graças a https://github.com/slack-t e https://github.com/bkutasi
- Adicione o botão de modelo de descarga à casca, conforme solicitado por https://github.com/aamir3d
- Adicione detalhes da casca ao readme_bark.md, conforme solicitado por https://github.com/maki9009
- Adicione "Opcional" para queimar no prompt, graças a https://github.com/maki9009
5 de setembro:
- Adicione a mistura de voz à casca
- Adicione V1 Burn no prompt para latir (queima em avisos é para direcionar o modelo semântico sem gastar tempo para gerar o áudio. O V1 funciona gerando os tokens semânticos e depois usá -lo como um prompt para o modelo semântico.)
- Adicione o limitador de comprimento da geração à casca
Agosto de 2023
27 de agosto:
- Fix MusicGen Ignorando a melodia #153
26 de agosto:
- Adicione Enviar ao RVC, Demucs, Botões VOCOS para casca e vocos
24 de agosto:
- Adicione a data às saídas do RVC para corrigir #147
- Corrigir a roda do SafeTensors
- Adicione o botão Enviar para Demucs ao MusicGen
21 de agosto:
- Adicione a instalação do Torchvision ao colab para a correção de problemas de música
- Remova o log de arquivo rvc_tab
20 de agosto:
- Corrija o MBD reinstalando o Hydra-Core no final de uma atualização
18 de agosto:
- CI: Adicione uma ação do GitHub para publicar automaticamente a imagem do Docker.
16 de agosto:
- Adicionar "nome" aos parâmetros de geração de tartaruga
15 de agosto:
- Pin Torch a 2.0.0 em todos os requisitos.txt arquivos
- Bump Audiocraft e versões de casca
- Remova os transformadores de tartaruga do COLAB
- Atualize a tartaruga para 2.8.0
13 de agosto:
- Correção potencialmente grande para novas instalações de usuário que tiveram problemas com a GPU não sendo suportada
11 de agosto:
- Tortoise Hotfix obrigado a Manmay-Nakhashi
- Adicione a opção de tartaruga para alterar o tokenizer
8 de agosto:
- Atualize o Audiocraft, melhorando o desempenho multibanddiffusion
- Corrigir parâmetro de tartaruga 'cond_free' incompatibilidade com predefinição 'Ultra_fast'
7 de agosto:
- Adicione a correção de velocidade de tartaruga ao colab
6 de agosto:
- Corrija o erro Audiogen + MBD, adicione a correção de tartaruga para colab
4 de agosto:
- Adicione a opção MultiBandDiffusion to MusicGen #109
- MusicGen/Audiogen Salve tokens na geração como arquivos .npz.
3 de agosto:
2 de agosto:
- Corrija os locais dos modelos que não estão aparecendo após o reinício
Julho de 2023
26 de julho:
- Galeria de voz
- Cropping de voz
- Corrija o bug de renomeio de voz, renomear a imagem também, adicione uma caixa de texto de hash
- Download mais fácil de vozes (#98)
24 de julho:
- Altere o formato do arquivo de casca para incluir History Hash: ... continuação_generation ... -> ... de_3ea0d063 ...
23 de julho:
- Imagem do Docker graças a https://github.com/jonfairbanks
- Melhorias de nomeação de interface do usuário RVC
21 de julho:
- Fix Hubert não está trabalhando apenas com CPU (#87)
- Adicionar demonstração do Google Colab (#88)
- Guia Novas Configurações e Locais de Modelo (para Usuários Avançados) (#90)
19 de julho:
- Adicione otimizações de tartaruga, obrigado https://github.com/manmay-nakhashi #79 (implementos #18)
16 de julho:
- Demoção da foto de voz
- Adicione um diretório para armazenar modelos/índices de RVC e um suspensão
- Solução alternativa RVC não respeitando IS_HALF para a CPU #74
- Modelo de tartaruga e melhorias de seleção de voz #73
10 de julho:
9 de julho:
- RVC Demo + Tortoise, V6 Installer com script de atualização e tentativas automáticas de instalar módulos extras #66
5 de julho:
- Instalador V5 aprimorado - mais rápido e mais confiável #63
2 de julho:
- Atualizar configurações de casca #59
1 de julho:
Junho de 2023
29 de junho:
27 de junho:
- Corrija erros de carregamento ansioso, refactor #50
20 de junho
- Tartaruga: Arquivos de geração de formato longo adequado #46
19 de junho
18 de junho:
- Atualizar para o mais novo Audiocraft, adicione gerações mais longas
14 de junho:
- Adicionar vocos wav tab #42
5 de junho:
- Corrija o botão "Salvar aos favoritos" na página de geração da casca, limpe o console (v4.1.1)
- Adicione a guia "Coleções" para gerenciar vários conjuntos de dados diferentes e moeda mais fácil.
4 de junho:
- Atualização para V4.1 - Função de hash aprimorada, melhorias de código
3 de junho:
- ATUALIZAÇÃO PARA V4 - NOVA ESTRUTURA DE SAÍDA, Vista de Histórico Melhorada, Reorganização da Base Code
Maio de 2023
21 de maio:
- Atualização para V3 - Demonstração do clone de voz
17 de maio:
- ATUALIZAÇÃO PARA V2 - Gere resultados à medida que aparecem, visualize gerações de longa geração, peça por peça, ativando até 9 saídas, ajustes da interface do usuário
16 de maio:
- Adicione a guia Configurações de graduação, corrija erros graduados no console, melhore o log.
- Atualize o histórico e os favoritos com "Use como Voice" e "Salvar Voice" Botões
- Adicione a guia Voices
- Guia da casca: remova "ou use a última geração como história"
- Melhorar a organização de código
13 de maio:
- Habilite geração determinística e aprimorar logs gerados. Créditos para Suno-AI/Bark#175.
10 de maio:
- Habilite a possibilidade de reutilizar os avisos da história das gerações mais velhas. Salve gerações como arquivos NPZ. Adicione um método conveniente de reutilizar qualquer uma das últimas três gerações para os próximos avisos. Adicione um botão para salvar e coletar o histórico de avisos em /Voices. #10
4 de maio:
- Geração de formulários longos (créditos para https://github.com/suno-ai/bark/blob/main/notebooks/long_form_generation.ipynb e sudo-ai/bark#161)
- Adaptar -se ao INV VAR Bug fixo
3 de maio:
- UI de tartaruga aprimorada: configurações de voz, predefinição e CVVP, bem como capacidade de gerar 3 resultados (#6)
2 de maio:
- Adicionado suporte ao histórico de reciliscando para continuar com instruções mais longas manualmente
- Adicionado suporte para prompts V2
Antes:
- Apoio adicionado para TTS de tartaruga
Atualização (para instalações antigas)
Em caso de questões, sinta -se à vontade para entrar em contato com os desenvolvedores .
Clique para expandir
Atualizando do V6 para o novo instalador
Recomendado: instalação fresca
- Faça o download da nova versão e execute o start_tts_webui.bat (Windows) ou start_tts_webui.sh (macOS, Linux)
- Depois de terminar, feche o servidor.
- Recomendado: copie as gerações antigas para o novo diretório, como favoritos/ saídas/ saídas-rvc/ modelos/ coletções/ config.json
- Com cautela: você pode copiar todo o novo diretório TTS-Geração-Webui sobre o antigo, mas pode haver alguns arquivos antigos perdidos.
Atualização no local, pode excluir alguns arquivos, ajustes
- Atualize a instalação existente usando o script da plataforma Update_
- Após a atualização, execute o novo start_tts_webui.bat (Windows) ou start_tts_webui.sh (macOS, linux) dentro do diretório TTS-Geração-Webui
- Quando o servidor começar, verifique se funciona.
- Com cautela: se o novo servidor funcionar, dentro do diretório de um cliques, exclua o antigo instalador_files.
Existe alguma maneira mais ideal de fazer isso?
Não exatamente, as dependências entram em conflito, especialmente entre o conda e o python (e as dependências já estão em um estado crítico, movê -las para o conda está longe). Portanto, embora seja possível substituir o instalador antigo pelo novo e executando a atualização, os problemas são imprevisíveis e não acessíveis . Fazer uma atualização para o instalador requer muitos testes para que não seja feito de ânimo leve.
Instalação
- Faça o download da versão mais recente e extrai -a.
- Execute start_tts_webui.bat ou start_tts_webui.sh para iniciar o servidor. Ele solicitará que você selecione a GPU/Chip que você está usando. Depois que tudo estiver instalado, ele iniciará o servidor Gradio em http: // localhost: 7770 e a UI do React em http: // localhost: 3000.
- O log de saída estará disponível no arquivo instalador_scripts/output.log.
Instalação manual (não recomendada)
Essas instruções podem não refletir todas as correções e ajustes mais recentes, mas podem ser úteis como referência para depuração ou entender o que o instalador faz. Espero que eles possam ser uma base para apoiar novas plataformas, como AMD/Intel.
Instale o conda (https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html)
- (Windows) Instale o Visual Studio Compiler/Visual Studio Build Tools https://visualstudio.microsoft.com/visual-cpp-bp-build-tools/
Configure um ambiente: conda create -n venv
Instale o git, node.js conda install -y -c conda-forge git python=3.10.11 conda-forge::nodejs=22.9.0 conda pip==23.3.2 conda-forge::uv=0.4.17 conda-forge::vswhere
a) Continue com o script do instalador
- Ative o ambiente:
conda activate venv e -
(venv) node installer_scriptsinit_app.js - Em seguida, execute o servidor com
(venv) python server.py
b) ou instale os requisitos manualmente
- Configure pytorch com CUDA ou CPU (https://pytorch.org/audio/stable/build.windows.html#install-pytorch):
-
(venv) conda install -y -k conda-forge::uv=0.4.17 conda-forge::vswhere conda-forge::postgresql=16.4 conda-forge::nodejs=22.9.0 conda-forge::ffmpeg=4.4.2[build=lgpl*] pytorch=2.3.1 torchvision torchaudio cpuonly -c pytorch para CPU/MAC -
(venv) conda install -y -k conda-forge::uv=0.4.17 conda-forge::vswhere conda-forge::postgresql=16.4 conda-forge::nodejs=22.9.0 conda-forge::ffmpeg=4.4.2[build=lgpl*] pytorch[version=2.3.1,build=py3.10_cuda11.8*] pytorch-cuda=11.8 torchvision torchaudio cuda-toolkit ninja -c pytorch -c nvidia/label/cuda-11.8.0 -c nvidia para CUDA
- Clone the repo:
git clone https://github.com/rsxdalv/tts-generation-webui.git - Instale os requisitos:
- Instale todos os requisitos*.txt (esta lista pode não estar atualizada, verifique https://github.com/rsxdalv/tts-generação
-
(venv) pip install -r requirements.txt -
(venv) pip install -r requirements_audiocraft.txt -
(venv) pip install -r requirements_bark_hubert_quantizer.txt -
(venv) pip install -r requirements_rvc.txt -
(venv) pip install hydra-core==1.3.2 -
(venv) pip install -r requirements_styletts2.txt -
(venv) pip install -r requirements_vall_e.txt -
(venv) pip install -r requirements_maha_tts.txt -
(venv) pip install -r requirements_stable_audio.txt -
(venv) pip install soundfile==0.12.1 -
(venv) pip install nvidia-ml-py
- Construa o aplicativo React:
(venv) cd react-ui && npm install && npm run build
- (Opcional) Configure o banco de dados:
(venv) node installer_scripts/js/applyDatabaseConfig.js - Execute o servidor:
(venv) python server.py
Reaja a interface do usuário
- Instale o NodeJS (se ainda não estiver instalado com o CONDA)
- Instale as dependências do React:
npm install - Build React:
npm run build - Run React:
npm start - Execute também o servidor Python:
python server.py ou com script start_tts_webui
Configuração do Docker
TTS-GENERAÇÃO-Webui também pode ser executado dentro de um recipiente do docker. Para começar, puxe a imagem do GitHub Container Registry:
docker pull ghcr.io/rsxdalv/tts-generation-webui:main
Depois que a imagem for puxada, ela pode ser iniciada com o Docker Compose:
O contêiner levará algum tempo para gerar a primeira saída enquanto os modelos são baixados em segundo plano. O status deste download pode ser verificado verificando os logs do contêiner:
docker logs tts-generation-webui
Construindo a imagem você mesmo
Se você deseja construir seu próprio contêiner do Docker, pode usar o Dockerfile incluído:
docker build -t tts-generation-webui .
Observe que o Docker-Compose precisa ser editado para usar a imagem que você acabou de criar.
Vozes extras para casca, amostras rápidas
Casca Readme
Readme_bark.md
Informações sobre gerenciamento de modelos, caches e espaço do sistema para projetos de IA
#186 (Responder no tópico)
Bibliotecas de código aberto
Este projeto utiliza as seguintes bibliotecas de código aberto:
Licença SUNO -AI/LATA - MIT
- Descrição: Código de inferência para modelo de casca.
- Repositório: suno/casca
Tortoise-TTS -Licença Apache-2.0
- Descrição: Uma biblioteca de síntese flexível de texto em fala para várias plataformas.
- Repositório: Neonbjb/Tortoise-tts
FFMPEG - Licença LGPL
- Descrição: Uma solução completa e cruzada para processamento de vídeo e áudio.
- Repositório: ffmpeg
- Uso: codificando arquivos vorbis ogg
FFMPEG -Python - Licença Apache 2.0
- Descrição: Ligações de Python para biblioteca FFMPEG para lidar com arquivos multimídia.
- Repositório: Kkroening/ffmpeg-python
Audiocraft - MIT Licença
- Descrição: Uma biblioteca para geração de áudio e música.
- Repositório: FacebookResearch/Audiocraft
VOCOS - MIT Licença
- Descrição: Um decodificador aprimorado para amostras de codecos
- Repositório: Charactr-platform/vocos
RVC - MIT Licença
- Descrição: Uma estrutura de conversão de voz fácil de usar com base em Vits.
- Repositório: RVC-Projeto/Recuperação-Voice-Conversão-Webui
Uso ético e responsável
Essa tecnologia destina -se à capacitação e criatividade, não por danos.
Ao se envolver com esse modelo de IA, você reconhece e concorda em cumprir essas diretrizes, empregando o modelo de IA de maneira responsável, ética e legal.
- Intenção não maliciosa: não use esse modelo de IA para atividades maliciosas, prejudiciais ou ilegais. Ele deve ser usado apenas para fins legais e éticos que promovam engajamento positivo, compartilhamento de conhecimento e conversas construtivas.
- Sem representação: não use esse modelo de IA para se passar por se representar ou deturpar -se como outra pessoa, incluindo indivíduos, organizações ou entidades. Não deve ser usado para enganar, fraudar ou manipular outros.
- Não há atividades fraudulentas: este modelo de IA não deve ser usado para fins fraudulentos, como golpes financeiros, tentativas de phishing ou qualquer forma de práticas enganosas destinadas a adquirir informações confidenciais, ganho monetário ou acesso não autorizado a sistemas.
- Conformidade Legal: Garanta que seu uso deste modelo de IA esteja em conformidade com as leis, regulamentos e políticas aplicáveis sobre uso de IA, proteção de dados, privacidade, propriedade intelectual e quaisquer outras obrigações legais relevantes em sua jurisdição.
- Reconhecimento: Ao se envolver com esse modelo de IA, você reconhece e concorda em cumprir essas diretrizes, usando o modelo de IA de maneira responsável, ética e legal.
Licença
Base de código e dependências
A base de código está licenciada no MIT. No entanto, é importante observar que, ao instalar as dependências, você também estará sujeito às suas respectivas licenças. Embora a maioria dessas licenças seja permissiva, pode haver algumas que não são. Portanto, é essencial entender que a licença permissiva se aplica apenas à própria base de código, não ao projeto inteiro.
Dito isto, o objetivo é manter a compatibilidade do MIT ao longo do projeto. Se você se deparar com uma dependência que não é compatível com a licença do MIT, sinta -se à vontade para abrir um problema e trazê -lo à nossa atenção.
Dependências não Permissivas conhecidas:
| Biblioteca | Licença | Notas |
|---|
| Encodec | CC BY-NC 4.0 | Versões mais recentes são MIT, mas precisam ser instaladas manualmente |
| DIFFQ | CC BY-NC 4.0 | Opcional no futuro, não é necessário executar, pode ser desinstalado, deve ser atualizado com Demucs |
| Lamenc | Licença GPL | Versões futuras farão com que o LGPL, mas precisará ser instalado manualmente |
| unidecode | Licença GPL | Não é a missão crítica, pode ser substituída por outra biblioteca, edição: neonbjb/tartoise-tts#494 |
Pesos do modelo
Os pesos do modelo têm licenças diferentes, preste atenção à licença do modelo que você está usando.
Mais notavelmente:
- Casca: MIT
- Tartaruga: Desconhecido (Apache-2.0 De acordo com o Repo, mas nenhum arquivo de licença no Huggingface)
- MusicGen: CC BY-NC 4.0
- Audiogen: CC BY-NC 4.0
Compatibilidade / erros
Atualmente, o Audiocraft é compatível apenas com Linux e Windows. O suporte a MacOS ainda não chegou, embora possa ser possível instalar manualmente.
Tocha sendo reinstalada
Devido às limitações do Python Package Manager (PIP), a tocha pode ser reinstalada várias vezes. Esta é uma grande questão de Pip e Torch.
Mensagens vermelhas no console
Essas mensagens:
---- requires ----, but you have ---- which is incompatible.
São completamente normais. É uma limitação do PIP e porque esta interface da web combina muitos projetos de IA diferentes. Como os projetos nem sempre são compatíveis entre si, eles reclamarão sobre os outros projetos que estão sendo instalados. Isso é normal e esperado. E no final, apesar dos avisos/erros, os projetos funcionarão juntos. Não está claro se essa situação será resolvida, mas essa é a esperança.