ChatIE
1.0.0
Repositório oficial do artigo "Extração de informações zero-tiro via bate-papo com chatgpt". Por favor, estrela, assista e bifurque nosso repositório para as atualizações ativas!
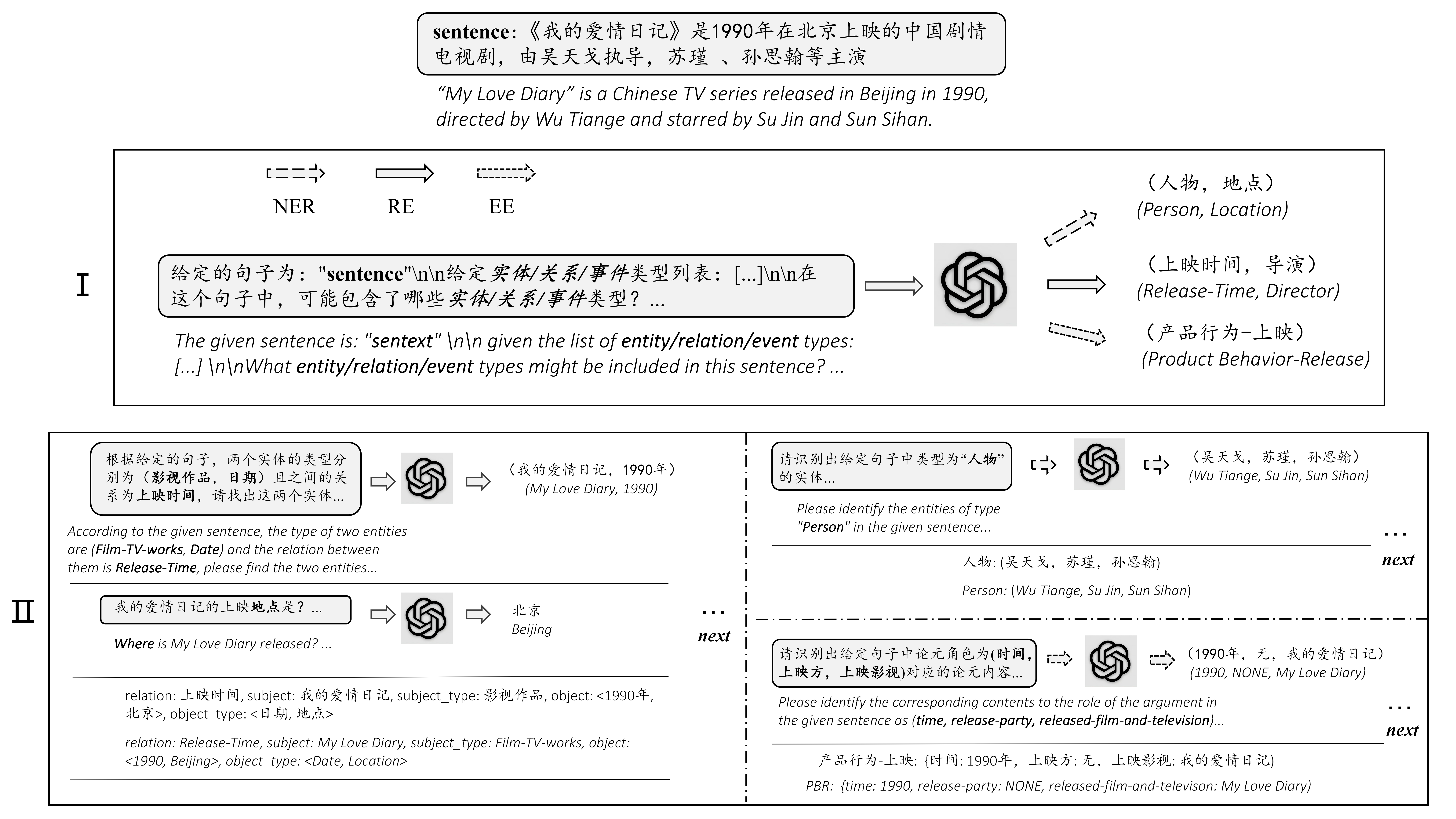
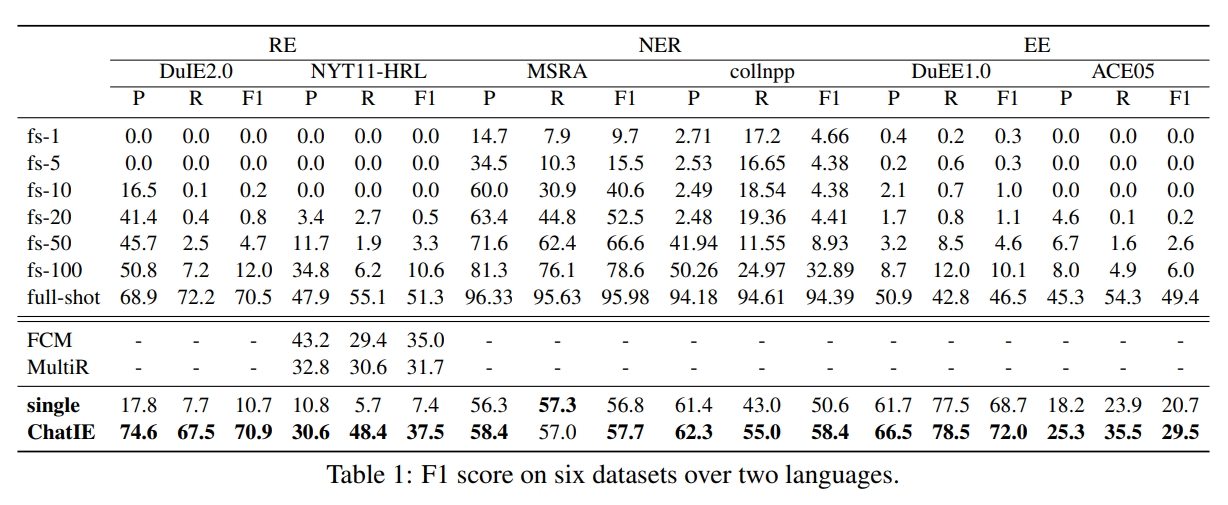
A extração de informações zero-tiro (IE) pretende criar sistemas do IE a partir do texto não anotado. É um desafio devido ao envolvimento de pouca intervenção humana. Desafiador, mas vale a pena, o Zero Shot, ou seja, reduz o tempo e o esforço que a rotulagem de dados leva. Esforços recentes em grandes modelos de idiomas (LLMS, por exemplo, GPT3, ChatGPT) mostram desempenho promissor em configurações de tiro zero, inspirando-nos a explorar métodos rápidos. Neste trabalho, perguntamos se os modelos fortes do IE podem ser construídos diretamente solicitando LLMs. Especificamente, transformamos a tarefa do IE zero em um problema de resposta a perguntas de várias turnos com uma estrutura de dois estágios (Chatie). Com o poder do ChatGPT, avaliamos extensivamente nossa estrutura em três tarefas do IE: extrato triplo de correção EntityRelation, reconhecimento de entidade denominado e extração de eventos. Os resultados empíricos em seis conjuntos de dados em dois idiomas mostram que o Chatie alcança um desempenho impressionante e até supera alguns modelos de tiro completo em vários conjuntos de dados (por exemplo, NYT11-HRL). Acreditamos que nosso trabalho pode esclarecer a construção de modelos, ou seja, modelos com recursos limitados.
零样本信息抽取 (Extração de informação , isto é) 旨在从无标注文本中建立 旨在从无标注文本中建立 系统 , 因为很少涉及人为干预 , 该问题非常具有挑战性。但零样本 ie 不再需要标注数据时耗费的时间和人力, (例如 例如 Gpt-3 , bate-papo gpt) 在零样本设置下取得了很好的表现 , 这启发我们探索基于提示的方法来解决零样本 ie 任务。我们提出一个问题 : 不经过训练来实现零样本信息抽取是否可行?我们将零样本 ie 任务转变为一个两阶段框架的多轮问答问题 (bate -papo ie), 并在三个 ie 任务中广泛评估了该框架 : : 实体关系三元组抽取、命名实体识别和事件抽取。在两个语言的 6 个数据集上的实验结果表明 , Chat Ou seja, 取得了非常好的效果 甚至在几个数据集上 (例如 例如 nyt11-hrl) 上超过了全监督模型的表现。我们的工作能够为有限资源下 ie 系统的建立奠定基础。
Atualização : Usamos a API oficial, a ferramenta se torna mais rápida !!! Se a chave exceder os limites, por favor, diga -nos.
Aviso : A velocidade da resposta depende da API oficial do OpenAI Chatgpt. (Às vezes, o funcionário está muito lotado e a velocidade será lenta ou o chatgpt será sobrecarregado.) Além disso, você usa melhor sua própria chave OpenAI, porque se nossa conta padrão for usada por várias pessoas ao mesmo tempo, a conta pode ser sobrecarregado.
AVISO: Como a API oficial não está disponível no doméstico, usamos a API da versão RevchatGPT e V1. Mas é muito lento , então aconselhamos que você use a ferramenta offline para estudo. Atualizaremos ainda mais a API no futuro ( TODO ).
Também fornecemos uma ferramenta do IE baseada no GPT3.5, você pode ver no GPT4ie
Chatie (extração de informações com tiro zero via bate-papo com ChatGPT) é uma demonstração de ferramentas de código aberto e poderosa. Aprimorada pelo ChatGPT e pela solicitação, ele visa extrair automaticamente informações estruturadas de uma frase bruta e fazer uma análise aprofundada valiosa da frase de entrada. Aproveitar informações estruturadas valiosas ajuda as empresas a tomar decisões incisivas e de negócios. 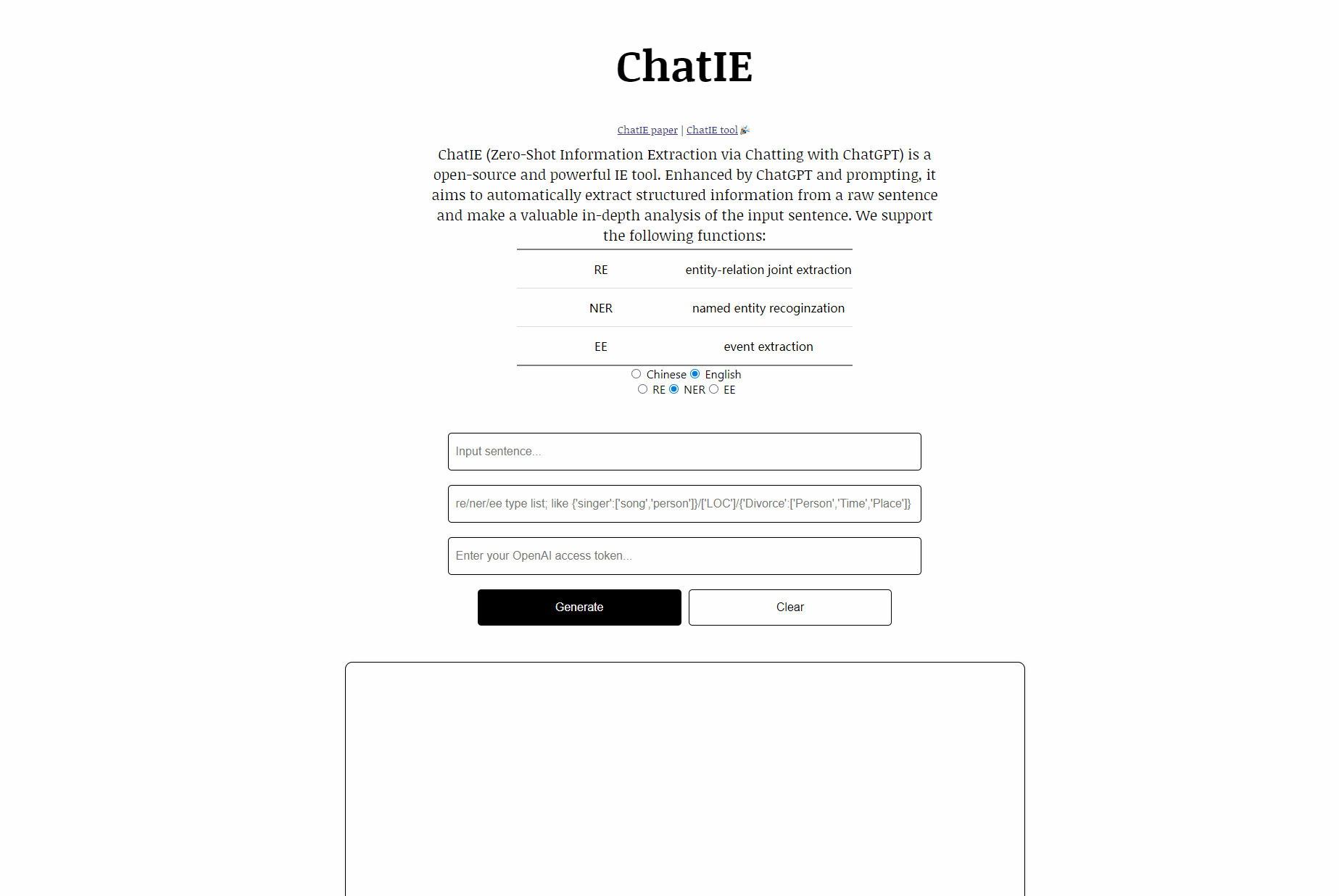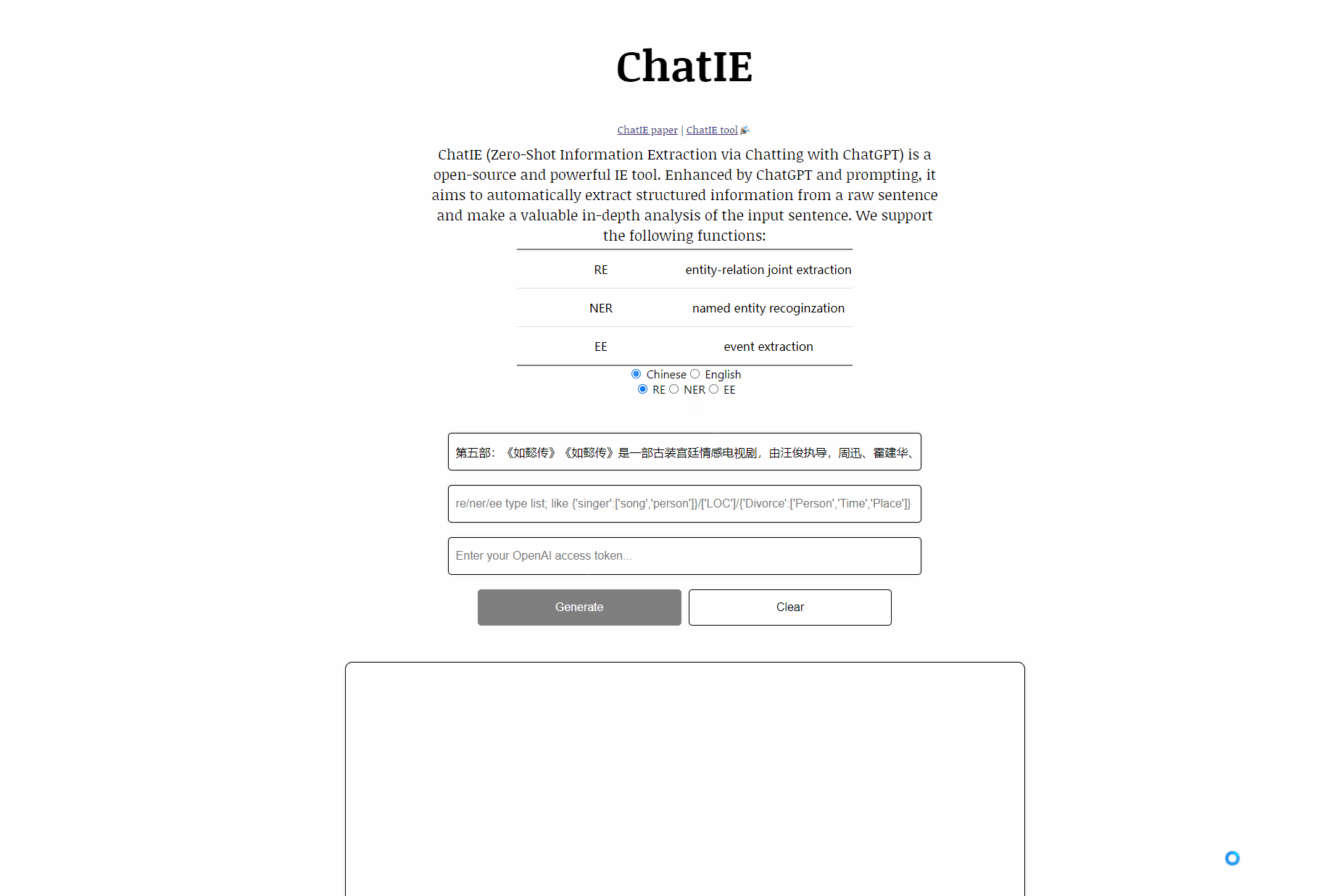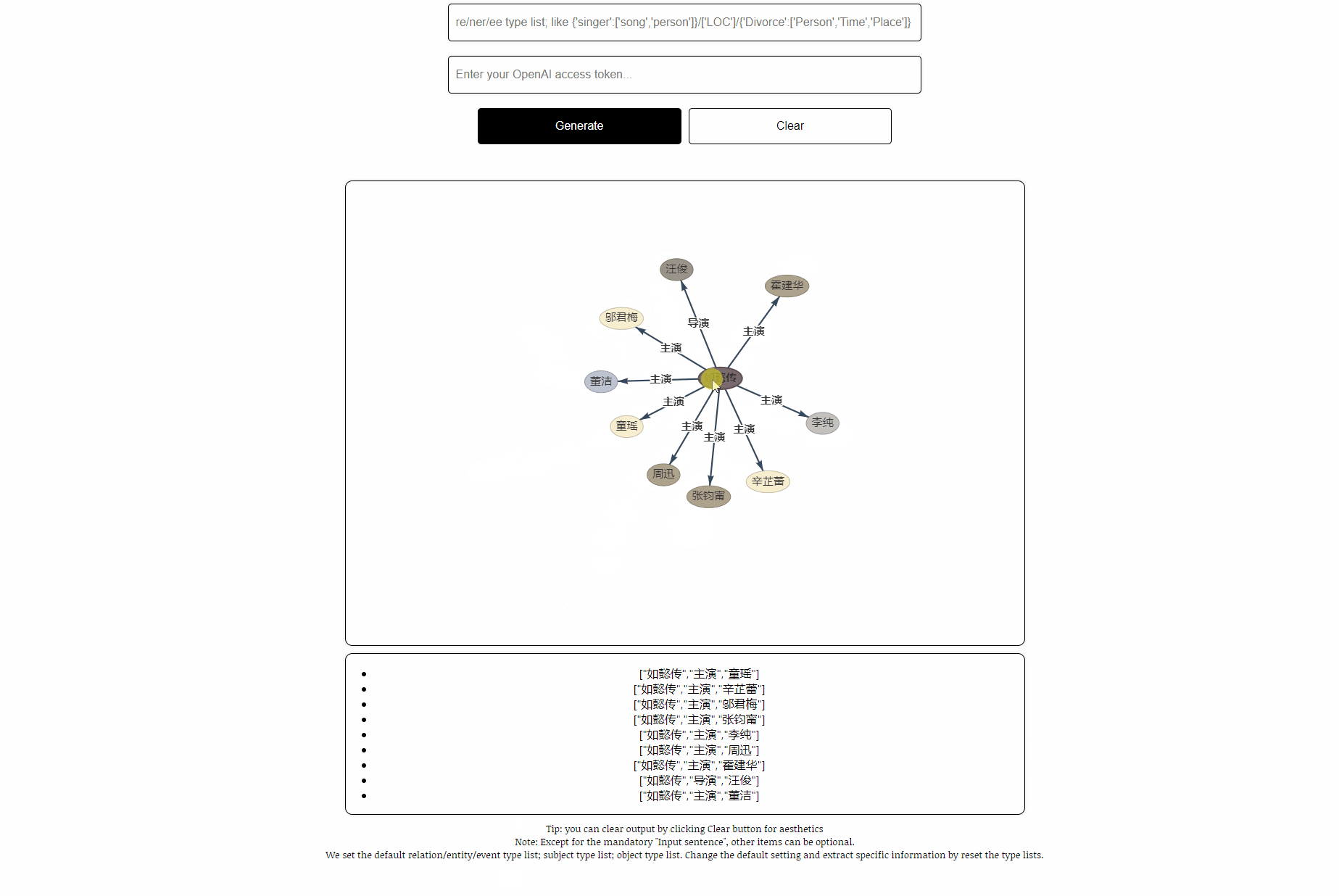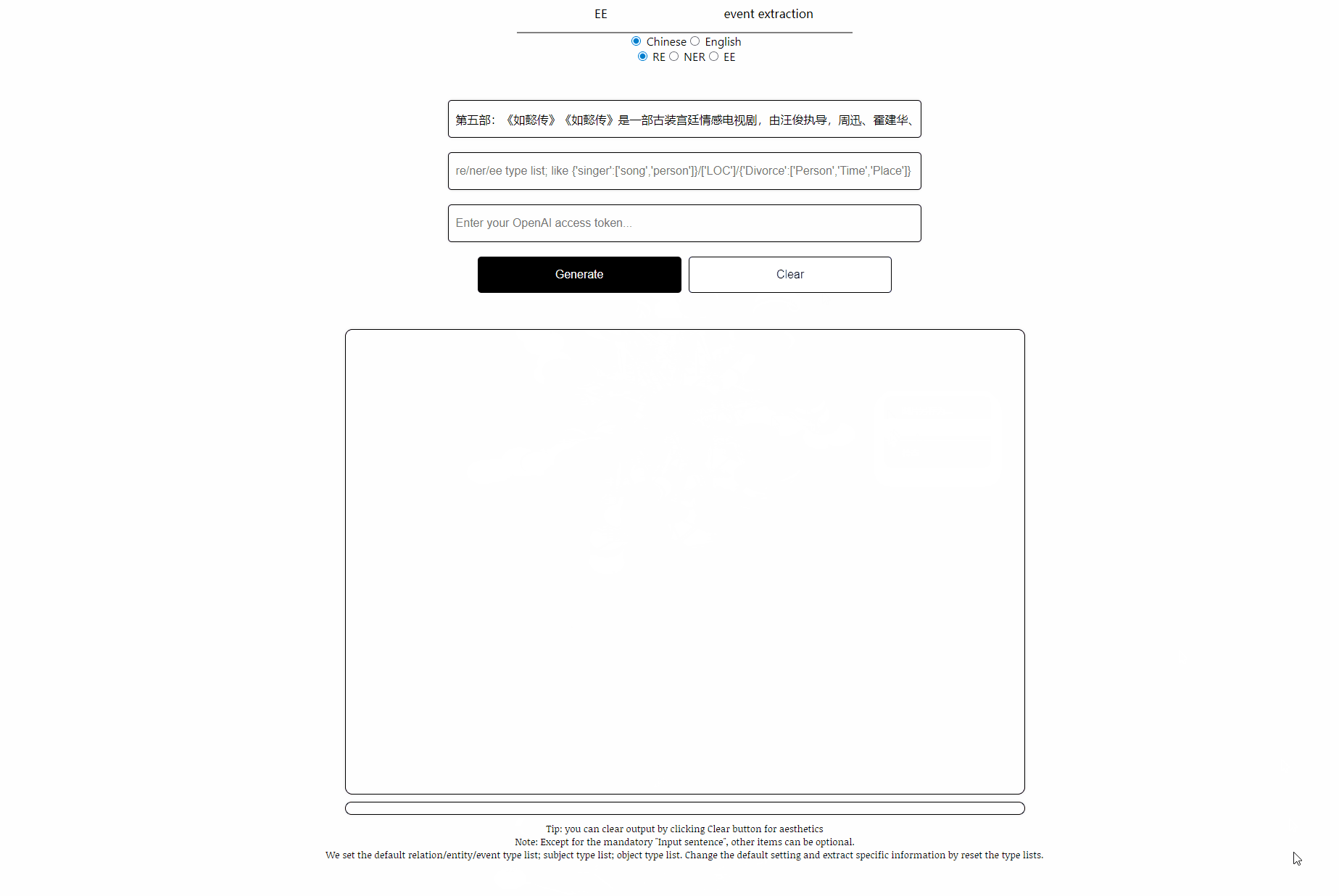
Apoiamos as seguintes funções:
| Tarefa | Nome | Lauguages |
|---|---|---|
| RÉ | Extração articular da entidade-relação | Chinês, inglês |
| Ner | Recompiante de entidade nomeada | Chinês, inglês |
| Ee | Extração de eventos | Chinês, inglês |
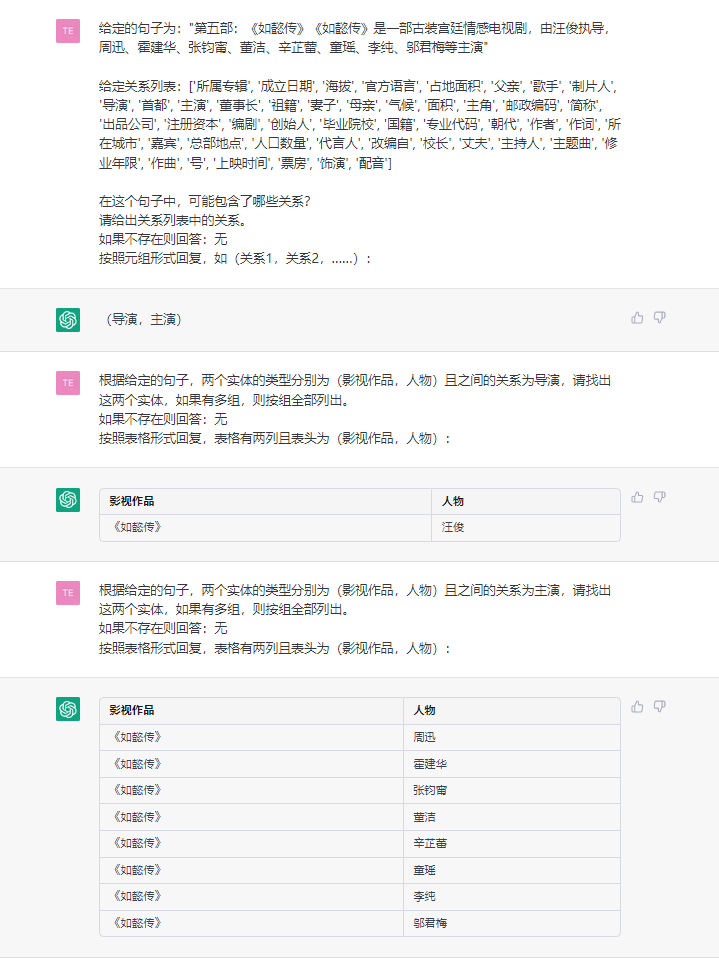
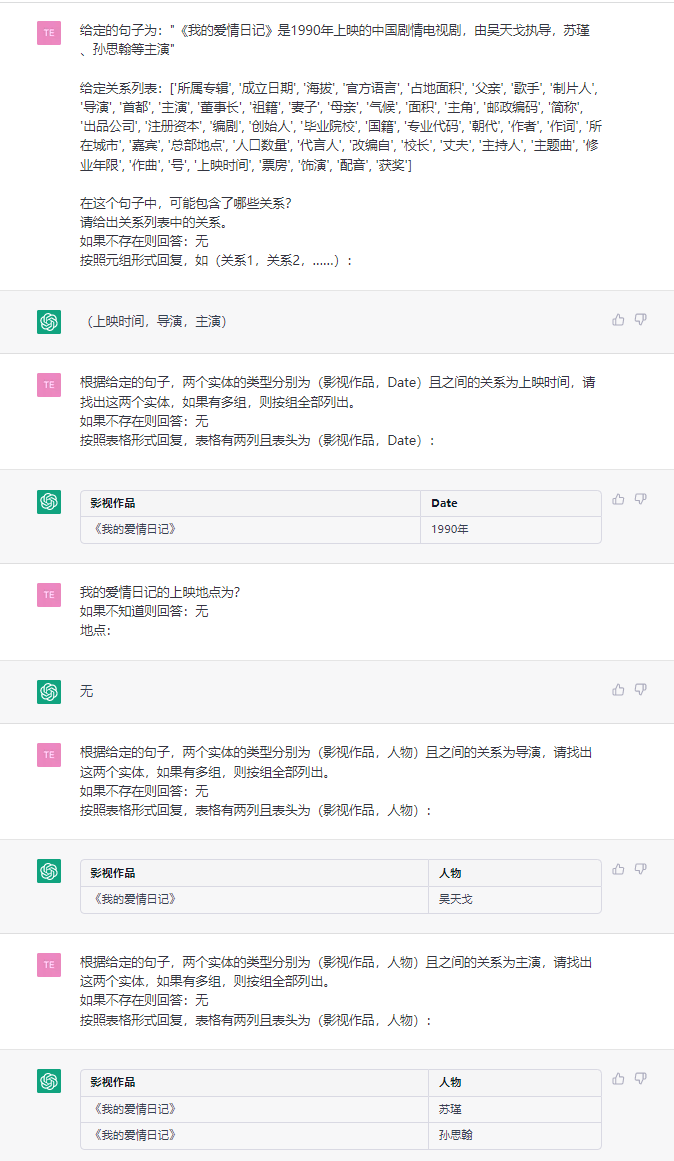
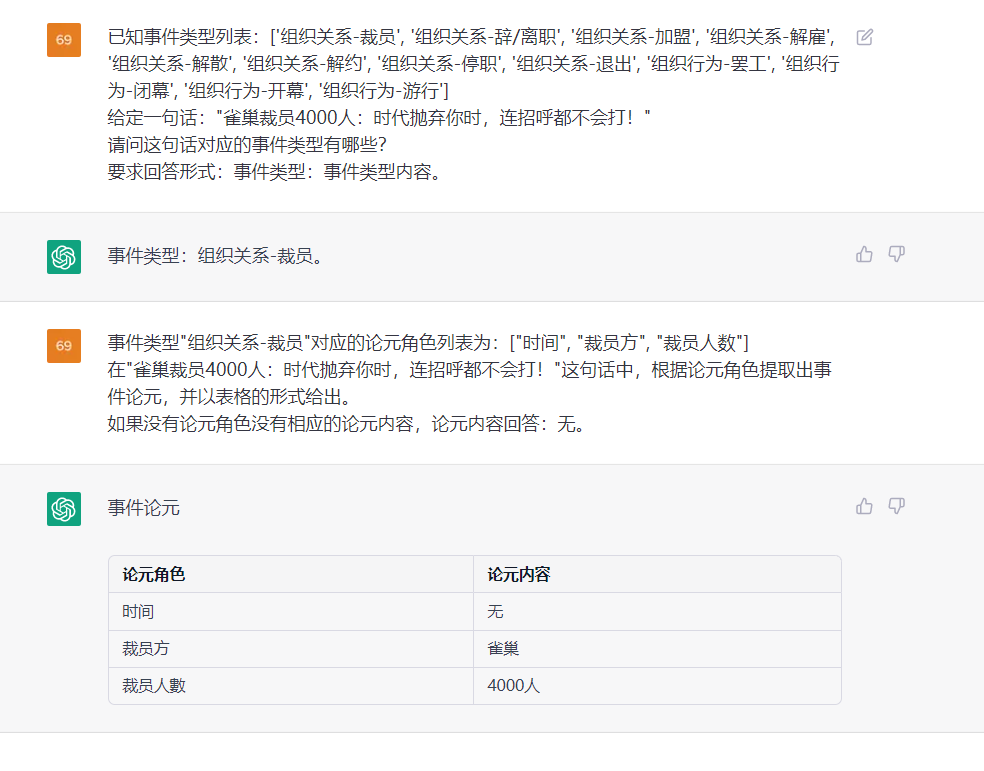
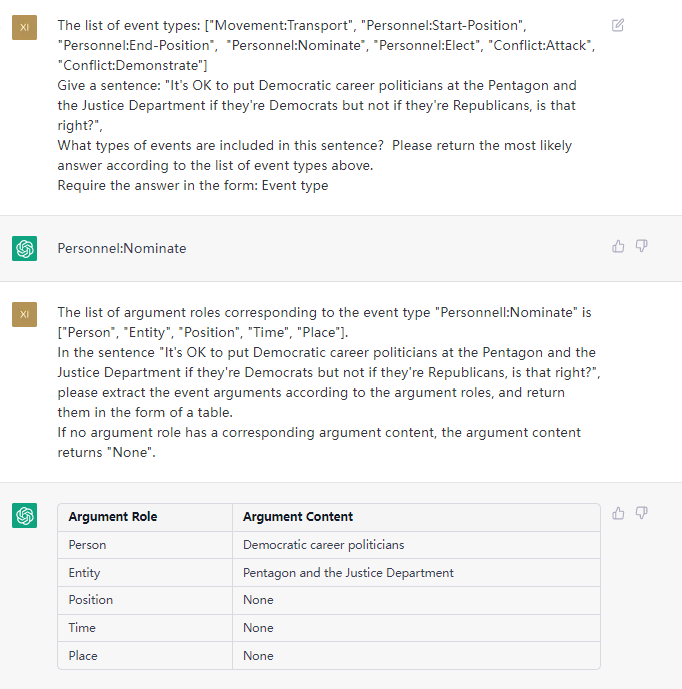
Esta tarefa visa extrair triplos de textos simples, como (China, capital, Pequim) , (《如懿传》, 主演, 周迅 周迅) .
PS: * denotar opcional, definimos o valor padrão para eles. Mas, para melhor extração, você deve especificar a lista de três de acordo com os cenários de aplicativos.
sentença: quatro outros executivos do Google, o diretor financeiro, George Reyes; o vice -presidente sênior de operações comerciais, Shona Brown; o diretor jurídico, David Drummond; e vice -presidente sênior de gerenciamento de produtos, Jonathan Rosenberg ganhou salários de US $ 250.000 cada.
RTL: Padrão, consulte o arquivo "Tipo de padrão"
Ouptut: 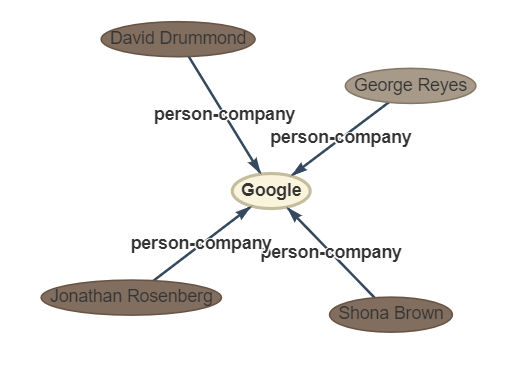
Sentença:第五部 : 《如懿传》《如懿传》是一部古装宫廷情感电视剧 , 由汪俊执导 , 周迅、霍建华、张钧甯、董洁、辛芷蕾、童瑶、李纯、邬君梅等主演。 周迅、霍建华、张钧甯、董洁、辛芷蕾、童瑶、李纯、邬君梅等主演。
RTL: Padrão, consulte o arquivo "Tipo de padrão"
Ouptut: 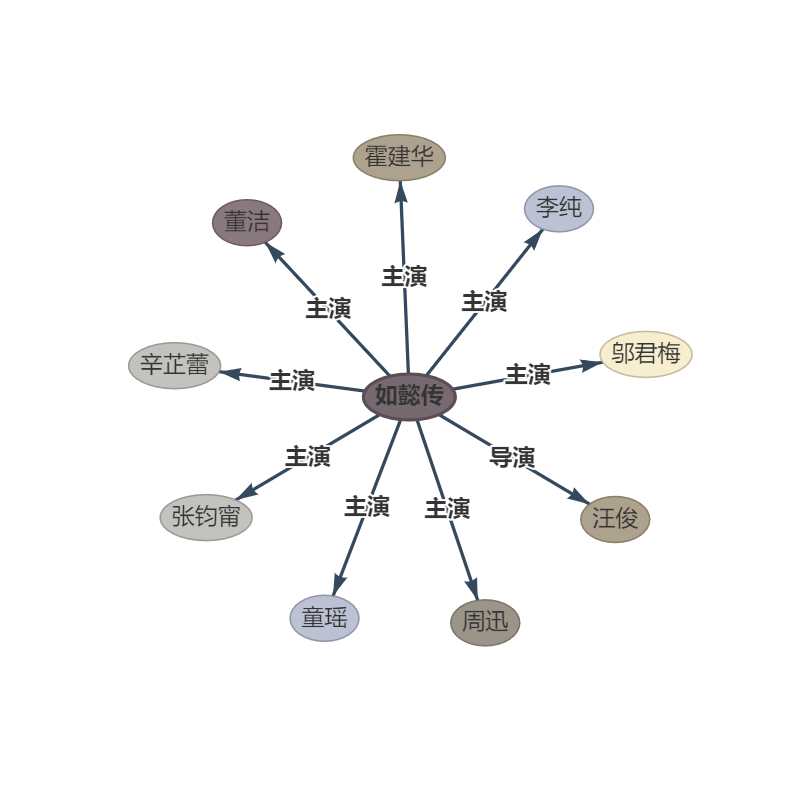
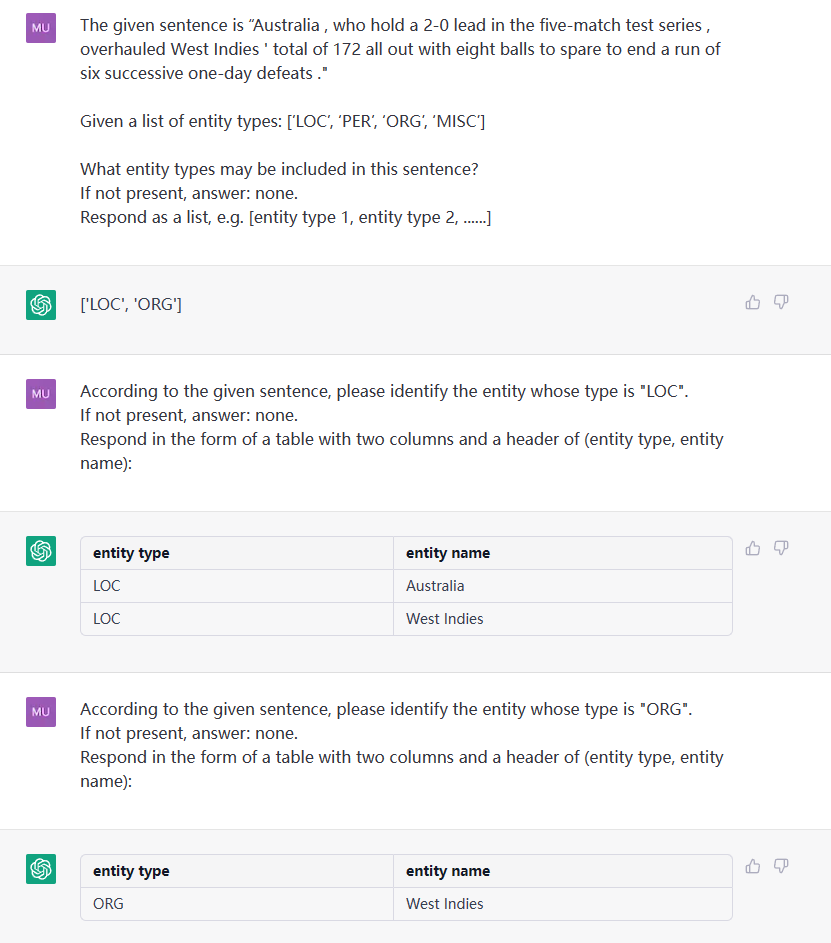
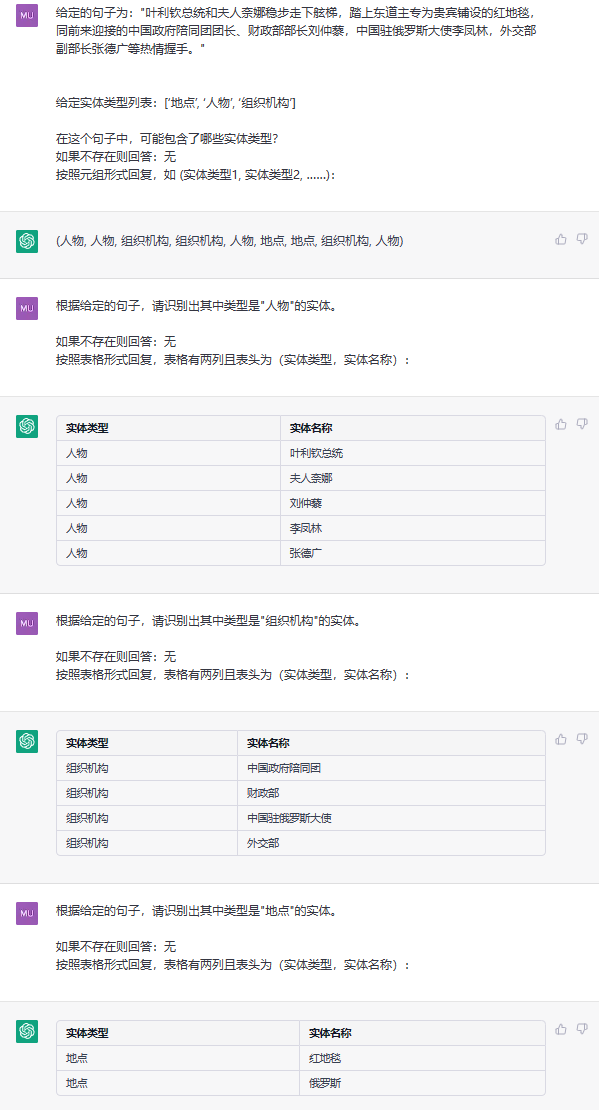
Esta tarefa visa extrair entidades de textos simples, como (loc, Pequim) , (人物, 周恩来) .
Sentença: James trabalhou para o Google em Pequim, capital da China. ETL: ['loc', 'misc', 'org', 'por']
Ouptut: 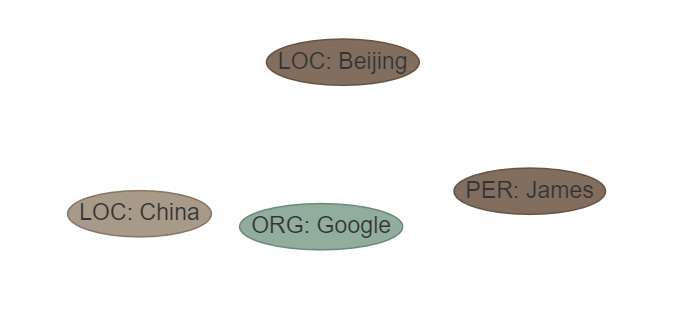
Sentença:中国 产党创立于中华民国大陆时期 , 由陈独秀和李大钊领导组织。 由陈独秀和李大钊领导组织。
ETL: ['' ',' '', '' ']
Ouptut: 
Esta tarefa visa extrair eventos de textos simples, como {Life-Divorce: {Pessoa: Bob, Hora: hoje, lugar: America}}, {竞赛行为-晋级: {时间: 无, 晋级方: 西北狼, 晋级赛事: 中甲榜首之争}} .
Sentença: Ontem Bob e sua esposa se divorciaram em Guangzhou.
ETL: Padrão, consulte o arquivo "Tipos Padrão"
Ouptut: 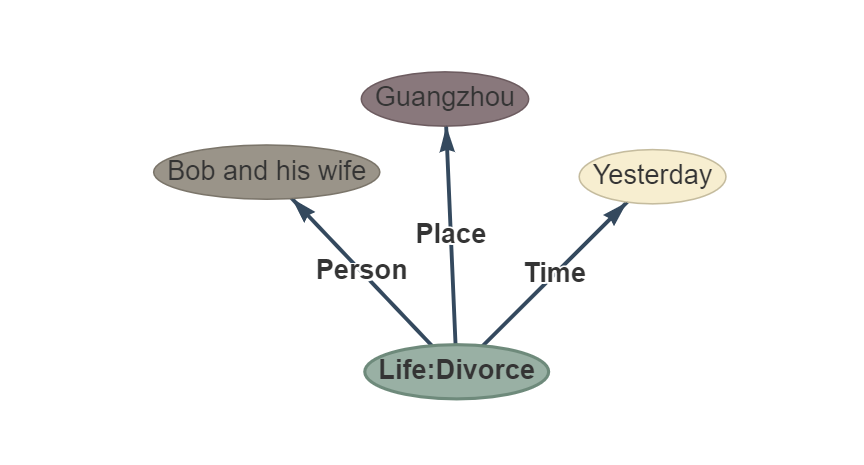
Sentença:在 2022 年卡塔尔世界杯决赛中 , 阿根廷以点球大战险胜法国。
ETL: Padrão, consulte o arquivo "Tipos Padrão"
Ouptut: 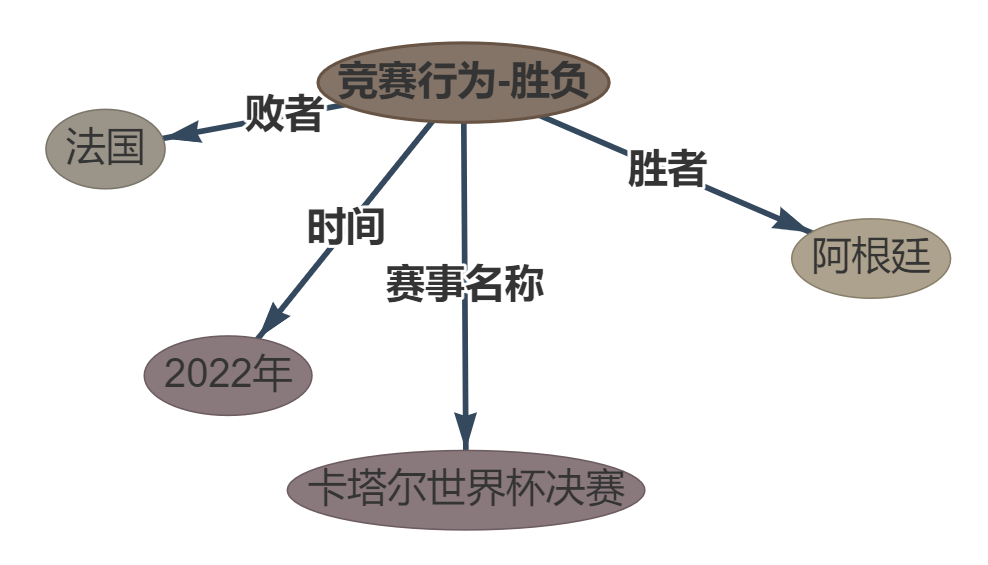
reação+balão
front-end e execute npm install para baixar as dependências necessárias.npm run start . Chatie deve abrir em uma nova guia do navegador.back-end e Run python run.py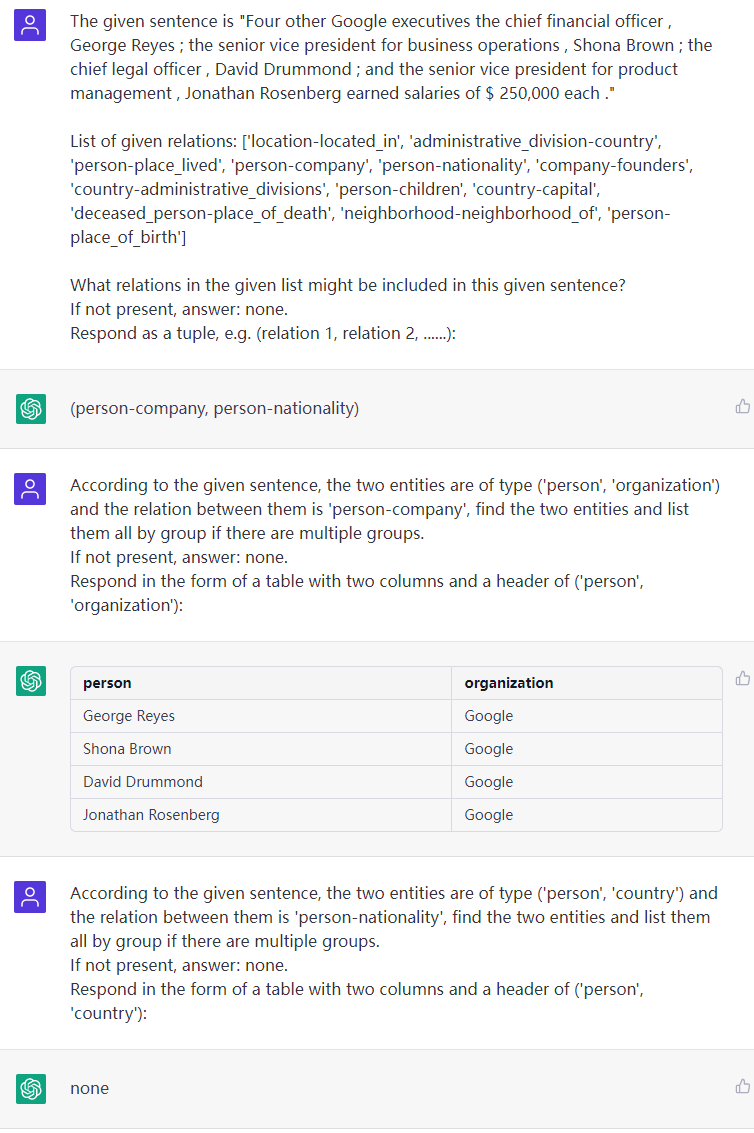
Estamos comprometidos em melhorar nosso projeto e fornecer a melhor experiência possível. Para conseguir isso, coletaremos seus dados para nos ajudar a entender como você interage com nosso projeto e identificaremos áreas para melhorias. Valorizamos a privacidade e a segurança de seus dados e garantimos os dados apenas para fins de melhorar nosso projeto.
Feche este artigo Arxiv: 2302.10205
@article{wei2023zero,
title={Zero-Shot Information Extraction via Chatting with ChatGPT},
author={Wei, Xiang and Cui, Xingyu and Cheng, Ning and Wang, Xiaobin and Zhang, Xin and Huang, Shen and Xie, Pengjun and Xu, Jinan and Chen, Yufeng and Zhang, Meishan and others},
journal={arXiv preprint arXiv:2302.10205},
year={2023}
}


