Reading_groups
1.0.0
O poder da computação : muitas evidências mostram que os avanços no aprendizado de máquina são amplamente impulsionados pela computação, não pela pesquisa, consulte "a lição amarga" e muitas vezes há fenômenos de emergência e homogeneização. Estudos mostraram que o uso da computação de inteligência artificial duplica a cada 3,4 meses, enquanto a melhoria da eficiência só dobra a cada 16 meses. Entre eles, a quantidade de cálculo é impulsionada principalmente pelo poder da computação, enquanto a eficiência é impulsionada pela pesquisa. Isso significa que o crescimento da computação historicamente dominou os avanços no aprendizado de máquina e em seus subcampos. Isso é ainda mais comprovado pelo surgimento do GPT-4. Apesar disso, ainda precisamos prestar atenção se haverá uma arquitetura mais subvertida no futuro, como o S4. A maioria dos hotspots atuais de pesquisa da PNL é baseada em LLM mais avançado (~ 100b,
Para mais documentos de tópicos da LLM, consulte aqui e aqui.
Documentos ( categoria aproximada )
recurso
【Testes no GPT-4, Limitação】 Faíscas de Inteligência Geral Artificial: Experiências iniciais com GPT-4
【Documentos de instrução, incluindo SFT, PPO, etc., um dos artigos mais importantes】 Modelos de linguagem de treinamento para seguir as instruções com feedback humano
【Supervisão escalável: como os humanos podem continuar melhorando seus modelos depois que seus modelos excedem suas próprias tarefas? 】 Medir o progresso da supervisão escalável para grandes modelos de linguagem
【Definição de alinhamento, produzido por DeepMind】 Alinhamento de agentes de linguagem
Um assistente de idioma geral como laboratório de alinhamento
[Artigo retrô, modelo pesquisado usando CCA+] Melhorando os modelos de linguagem recuperando de trilhões de tokens
Modelos de linguagem de ajuste fino de preferências humanas
Treinar um assistente útil e inofensivo com o aprendizado de reforço com o feedback humano
【Grande modelo em chinês e inglês, excedendo o GPT-3】 GLM-130B: um modelo pré-treinado bilíngue aberto
【Otimização de destino pré-treinamento】 UL2: Unificando paradigmas de aprendizado de idiomas
【Os novos benchmarks, bibliotecas de modelos e novos métodos do Alinhamento】 Aprendizagem de reforço (não) para processamento de linguagem natural?: Benchmarks, linhas de base e blocos de construção para otimização de políticas de linguagem natural
【MLM sem as tags [Mask] através da tecnologia】 Deficiência de representação na modelagem de linguagem mascarada
【Texto para o treinamento de imagem alivia as necessidades do vocabulário e resiste a certos ataques】 Modelagem de idiomas com pixels
Lexmae: Pré-Treinamento de Léxico-Bottlenecked para Recuperação em larga escala
Incoder: um modelo generativo para preenchimento e síntese de código
[Pesquise imagens relacionadas a texto para o modelo de idioma pré-treinamento] Modelagem de idiomas visualmente com agente
Um modelo de linguagem auto-terminante não monotônica
【Comparação e ajuste fino do feedback negativo através do ProPT Design】 cadeia de retrospectiva alinha modelos de linguagem com feedback
【Modelo de pardal】 Melhorando o alinhamento de agentes de diálogo por meio de julgamentos humanos direcionados
[Use pequenos parâmetros do modelo para acelerar o processo de treinamento de um modelo grande (não começando do zero)] Aprendendo a cultivar modelos pré -traidos para treinamento de transformadores eficientes
[Modelo de fusão de conhecimento semi-paramétrico de MOE para múltiplas fontes de conhecimento] Conhecimento em Contexto: Rumo a modelos de linguagem semi-paramétricos conhecedores
[Método de mescla
[É muito inspirador que o mecanismo de pesquisa substitua a arquitetura geral da FFN no transformador (× 2,54 tempo) para dissociar o conhecimento armazenado em parâmetros do modelo] Modelo de linguagem com memória plug-in knowldge
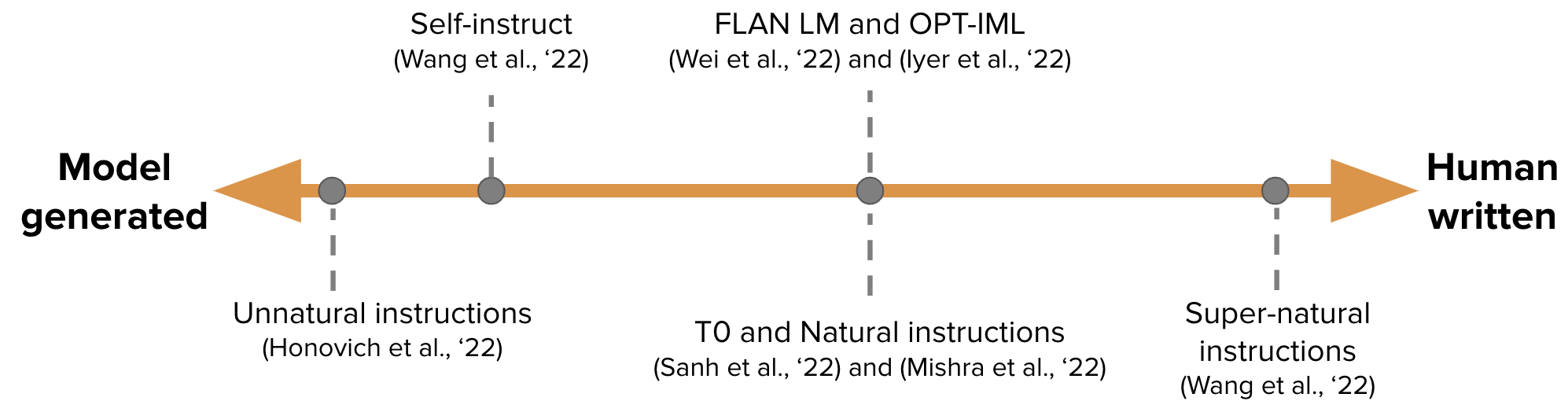
【Gerar automaticamente dados de ajuste de instrução para treinamento GPT-3】 Auto-instrução: alinhando o modelo de linguagem com instruções auto-geradas
- 
Para modelos de linguagem mascarada dependentes condicionalmente
【Calibre iterativamente, os corretores independentes gerados imperfeitamente, o artigo de acompanhamento de Sean Weleck】 Gerando sequências aprendendo a se auto-corrigir
[Aprendizagem contínua: adicione um Propt para a nova tarefa, e o Propt da tarefa anterior e o grande modelo permanecem inalterados] Pronhos progressivos: aprendizado contínuo para modelos de idiomas sem esquecer
[EMNLP 2022, Atualização contínua do modelo] MEMPROMPT: Edição rápida assistida pela memória com feedback do usuário
【Nova arquitetura neural (folnet), que contém viés de indução lógica de primeira ordem】 Representações de idiomas de aprendizado com viés lógico indutivo
Ganlm: pré-treinamento do codificador com um discriminador auxiliar
Model Modelo de idioma pré-treinamento com base em modelos de espaço de estado, excedendo Bert】 Pré-tremendo sem atenção
[Considere o feedback humano durante o pré-treinamento] Modelos de idiomas pré-treinamento com preferências humanas
[Modelo de lhama de código aberto da Meta, 7B-65B, treina mais modelos pequenos rotulados do que o normal, alcançando o desempenho ideal sob vários orçamentos de inferência] Llama: modelos de linguagem de fundação abertos e eficientes
[Ensinar grandes modelos de idiomas a se auto-restabelecer e explicar o código gerado através de um pequeno número de exemplos, mas eles foram usados assim agora] Ensinando grandes modelos de idiomas a se auto-debugar
Quão longe os camelos podem ir? Explorando o estado de instrução em recursos abertos
Lima: menos é mais para o alinhamento
【Árvore da pensamento, cada vez mais como o AlphaGo】 Solução de problemas deliberados com grandes modelos de linguagem
【O método de raciocínio em várias etapas para aplicar a ICL é muito inspirador】 React: sinergizando raciocínio e atuação em modelos de linguagem
【O COT gera diretamente o código do programa e, em seguida, permite que o Execute do Intretador Python】 Programa de Pensamentos de Pontuação: Defentrangendo o Computação do Raciocínio para Tarefas de Raciocínio Numérico
[Big Model gera diretamente o contexto de evidência] gerar em vez de recuperar: modelos de idiomas grandes são geradores de contexto fortes
【Modelo de escrita com 4 operações específicas】 Parer: um modelo de linguagem colaborativa
【Combinando Python, executores SQL e grandes modelos】 Modelos de linguagem de ligação em linguagens simbólicas
[Recuperar o código de geração de documentos] DocPropting: Gerando código recuperando os documentos
[Haverá muitos artigos em aterramento+LLM na próxima série] LLM-Planner: Planejamento fundamentado de poucos tiro para agentes incorporados com grandes modelos de idiomas
【Generação auto -iterativa (verificada usando dados de treinamento Python)】 Modelos de idiomas podem se ensinar a programar melhor
Artigos relacionados: especializar modelos de linguagem menores para raciocínio em várias etapas
Estrela: Raciocínio de bootstrapping com raciocínio, do Neurips 22 (Gere dados COT para o ajuste fino do modelo), causando uma série de artigos de berço que ensinam pequenos modelos.
Idéias semelhantes [destilação de conhecimento] Ensinando pequenos modelos de idiomas à razão e aprendizagem, destilando o contexto
Idéias semelhantes Kaist e Xiang Ren Grupos ([Raciocínio de Cot (Professor)] Pinto: Raciocínio de idiomas fiel usando justificativas geradas, etc.) e modelos de idiomas grandes estão raciocinando professores
ETH [Cot Data Trains Decomposição de problemas e modelos de solução de problemas separadamente] Destilando recursos de raciocínio de várias etapas de modelos de linguagem grandes em modelos menores por meio de decomposições semânticas
【Deixe os modelos pequenos aprenderem habilidades de berço】 Destilação de aprendizado no contexto: transferindo a capacidade de aprendizado de poucas fotos dos modelos de linguagem pré-treinados
【Big Model Ensine Modelo Pequeno Modelo】 Modelos de linguagem grandes são os professores de raciocínio
[O Big Model gera evidências (recitação) e depois realiza pequenas amostras de proposta de livro fechado e resposta] Modelos de linguagem agentada por recitação
[Métodos de linguagem natural de raciocínio indutivo] Modelos de idiomas como raciocínio indutivo
[O GPT-3 é usado para anotação de dados (como classificação emocional)] O GPT-3 é um bom anotador de dados?
【Modelos para aumento de dados com base no treinamento de multitarefa para menos amostra de dados de dados】 knowda: modelo de mistura de conhecimento all-in-one para aumento de dados em PNs de baixo recurso
【Trabalho de planejamento processual, não está interessado no tempo】 Planejamento processual neuro-simbólico com senso de senso comum.
[Objetivo: gerar artigos de fato corretos para consultas, aterrando em grandes corpus da web
【Combinando os resultados do simulador de física externa no contexto】 Olhos da Mente: Raciocínio do Modelo de Linguagem Aumentado através da simulação
[Recupere a tarefa de aprimorar o COT para fazer o conhecimento intensivo] Recuperação de intercalação com o raciocínio da cadeia de pensamentos para perguntas de várias etapas intensivas em conhecimento
【Contraste o conhecimento potencial (binário) no modelo de linguagem de reconhecimento não supervisionado】 Descobrir conhecimento latente em modelos de linguagem sem supervisão
[Grupo Percy Liang, mecanismo de pesquisa confiável, apenas 51,5% das sentenças geradas são totalmente suportadas por citações] Avaliando verificabilidade em mecanismos de pesquisa generativos
Promoção de pontia progressiva melhora o raciocínio em grandes modelos de idiomas
Auto-alinhamento orientado a princípios de modelos de linguagem do zero com supervisão humana mínima
Julgando LLM-AS-A-JUDGE COM MT-BANCE E ARENA DE CHATBOT
[Na minha opinião, é um dos artigos mais importantes. Treinamento e a largura e a profundidade dos detalhes da arquitetura, como a largura e a profundidade.
[Um dos outros artigos mais importantes, Chinchilla, em computação limitada, o modelo ideal não é o maior modelo, mas um modelo menor treinado com mais dados (60-70b)] treinamento de modelos de linguagem grande computados e ideais
[Quais metas de arquitetura e otimização ajudam a generalização zero-amostra] Que arquitetura de modelos de idiomas e objetivos pré-treinos funcionam melhor para a generalização zero?
【Grokking “Epifany” Learning Process Memorization-> Formação do circuito-> Limpeza】 Medidas de progresso para grocking via interpretação mecanicista
[Investigar as características do modelo baseado em busca e descobriu que ambos são de raciocínio limitado] pode recuperar os modelos de linguagem agente-agente?
[Estrutura de avaliação de interação de idiomas humano-AI] Avaliando a interação do modelo em linguagem humana
Que algoritmo de aprendizado é o aprendizado no contexto?
【Edição de modelos, este é um tópico quente】 Memória de edição em massa em um transformador
[A sensibilidade do modelo ao contexto irrelevante, adicionando informações irrelevantes aos exemplos no prompt e adicionando instruções que ignoram o contexto irrelevante resolvido parcialmente] modelos de linguagem grandes podem ser facilmente distraídos por contexto irrelevante
【O berço zero-shot mostrará preconceitos e toxicidade sob questões sensíveis】 No segundo pensamento, não vamos pensar passo a passo!
【O berço do grande modelo tem recursos de linguagem cruzada】 Modelos de idiomas são motivos multilíngues de cadeia de pensamento
[Quanto menor a confusão de diferentes seqüências rápidas, melhor o desempenho] Promotos desmistificantes nos modelos de idiomas por meio da estimativa de perplexidade
[Tarefa de resolução de implicação binária de modelos grandes, essa sugestão é difícil e não há fenômeno de escala]. Benchmark_tasks/ Impicity)
【Aumentação baseada em complexidade para raciocínio em várias etapas
O que importa na poda estruturada de modelos de linguagem generativa?
[DataSet Ambibench, Ambiguidade de tarefas: o modelo RLHF de escala tem o melhor desempenho em tarefas desambiguações. Ajuste fino é mais útil do que poucos acumulação】 Ambiguidade de tarefas em humanos e modelos de idiomas
【Teste GPT-3, incluindo memória, calibração, preconceito, etc.】 Avanndo o GPT-3 a ser confiável
[Estudo da OSU que parte do COT é eficaz para o desempenho] para entender a solicitação da cadeia de pensamentos: um estudo empírico do que importa
[Pesquisa sobre o modelo entre linguagem de avisos discretos] pode ser solicitado a extração de informações discretas generalizar entre os modelos de idiomas?
【A taxa de memória é uma relação linear logarítmica com o tamanho do modelo, o comprimento do prefixo e a taxa de repetição no treinamento】 Quantificando memorização em modelos de linguagem neural
【É muito inspirador, decomponha o problema em sub-perguntas por meio da iteração do GPT e responda】 Medindo e estreitando a lacuna de composicionalidade nos modelos de linguagem
[Teste análogo do GPT-3 semelhante às questões de inteligência dos funcionários públicos] Raciocínio analógico emergente em grandes modelos de linguagem
Treinamento de texto curto, teste de texto longo, avaliação da adaptabilidade do comprimento da variável do modelo】 Um transformador de comprimento extrapolável
[Quando não confiar em modelos de linguagem: investigando eficácia e limitações de memórias paramétricas e não paramétricas
【ICL é outra forma de atualização de gradiente】 Por que o GPT pode aprender no contexto?
GPT-3 é um psicopata? Avaliando grandes modelos de linguagem de uma perspectiva psicológica
[Pesquisa sobre o processo de treinamento do modelo OPT em diferentes tamanhos e descobriu que a confusão é um indicador de trajetórias de treinamento de ICL] de treinamento de modelos de linguagem em escalas
[EMNLP 2022, o corpus inglês puro pré-treinado contém outros idiomas, e os recursos de linguagem cruzada do modelo podem vir de vazamento de dados] A contaminação da linguagem ajuda
[Substituir anteriores semânticos e usar informações no Propt é uma capacidade de surto] Modelos de linguagem maiores fazem aprendizado no contexto de maneira diferente
【EMNLP 2022 Resultados】 Qual modelo de idioma para treinar se você tiver um milhão de horas de GPU?
[Apresentando a tecnologia CFG durante o raciocínio melhora muito a capacidade de conformidade de instruções de modelos pequenos] Fique no tópico com orientação sem classificador
【Treine seu próprio modelo de lhama com o GPT-4 do OpenAI, e só posso dizer que eu admiro você】 Instruções Tuning com GPT-4
Reflexão: um agente autônomo com memória dinâmica e auto-reflexão
【Aprendizado imediato de estilo personalizado, OPT】 Sotts extensíveis para modelos de idiomas
[Acelerando a decodificação de grandes modelos, usando o consenso direto entre modelos pequenos e modelos grandes a serem usados várias vezes por vez, afinal, a entrada será muito lenta se for longa] acelerando o grande modelo de linguagem decodificação com amostragem especializada
[Use o prompt Soft para reduzir o declínio na capacidade da ICL causada por ajuste fino, ajustando o primeiro estágio, ajustando o segundo estágio] Preservando a capacidade de aprendizado no contexto em um modelo de grande idioma.
【Tarefas de análise semântica, métodos de seleção de amostras de ICL, Codex e T5-Large】 Diversidades Diviações Melhoram a generalização da composição do contexto
【Um novo método de otimização para geração de texto】 Modelos de geração de linguagem de adaptação sob distância de variação total
[Estimativa de incerteza da geração condicional, usando agrupamentos semânticos combinados com várias saídas de amostragem para estimar a entropia de aglomerados] incerteza semântica: invariâncias linguísticas para estimativa de incerteza na geração de linguagem natural
Ajuste: melhorando as habilidades de aprendizado zero de modelos de linguagem menores
【Muito inspirador, método de geração de texto sob restrições de texto livre】 Geração de texto controlável com restrições de linguagem
[Ao gerar previsões, use a similaridade para selecionar a frase em vez de token softmax] modelagem de linguagem mascarada não paramétrica
[Método da ICL para texto longo] As janelas de contexto paralelo melhoram o aprendizado no contexto de grandes modelos de linguagem
【Amostra de modelo InstructGPT gerando ICL por si só】 Auto-criação de grandes modelos de linguagem para QA de domínio aberto
【Mecanismos de transferência e atenção permitem que a ICL digite mais amostras de anotação】 Condução estruturada: dimensionando o aprendizado no contexto para 1.000 exemplos
Calibração de momento para geração de texto
【Dois métodos de seleção de amostras de ICL, experimentos com base em OPT e GPTJ】 Curadoria de dados cuidadosa estabiliza o aprendizado no contexto
【Análise dos indicadores de avaliação de Mauve (Pillutla et al.)】 Sobre a utilidade de incorporações, aglomerados e cordas para avaliação de geração de texto
Promptgator: Recuperação densa de poucos tiros de 8 exemplos
[Três sapateiros, Zhuge liang] A autoconsistência melhora o raciocínio da cadeia de pensamentos em modelos de linguagem
[Inverter, entrada e etiqueta geram instruções para condições] Adivinhe a instrução!
【Auto-verificação de derivação reversa da LLM】 Modelos de linguagem grandes são motivos com auto-verificação
【Métodos de pesquisa - Cenários de segurança sob o processo de geração de evidências】 FOVATE, atributo e racionalizar: Rumo a IA segura e confiável
[Estimativa de confiança de fragmentos extraídos por informações geradas por texto com base na pesquisa de feixes] Como a pesquisa de feixe melhora a estimativa de confiança no nível da altura na marcação generativa de sequência?
SPT: Ajuste rápido semi-paramétrico para o aprendizado de várias tarefas
【Uma discussão sobre resumo extraído de rótulo de ouro】 resumo de texto com expectativa Oracle
【Método de detecção de ood com base na distância marciana】 Detecção fora da distribuição e geração seletiva para modelos de linguagem condicional
[Módulo de atenção integra o prompt para prever o nível da amostra] Modelo Ensemble em vez de fusão rápida: um método de transferência de conhecimento específico para amostra para um ajuste rápido de poucos anos
【Prompt para várias tarefas por decomposição e destilação em um prompt】 A ajuste imediato de várias tarefas permite o aprendizado de transferência com eficiência de parâmetro
[Os indicadores de avaliação do texto gerado passo a passo podem ser usados como tópico para compartilhar na próxima vez] Roscoe: um conjunto de métricas para marcar raciocínio passo a passo
[A probabilidade de sequência de calibração melhora a geração de linguagem condicional]
【Método de ataque de texto com base na otimização do gradiente】 TEXTGRADOR: Avaliação de robustez em PNL por otimização orientada a gradiente
[Modelagem GMM Limites de classificação de decisão da ICL para calibrar] Calibração prototípica para aprendizado de poucos modelos de linguagem
【Problema de reescrita e método de agregação de ICL baseado em gráfico】 Pergunte-me qualquer coisa: uma estratégia simples para solicitar modelos de linguagem
[Banco de dados para selecionar bons candidatos como ICLs de piscinas de exemplo não anotadas] Anotação seletiva torna os modelos de idiomas melhores alunos de poucos anos
PromptBoosting: Classificação de texto de caixa preta com dez passes para a frente
Ataques de backdoor guiados por atenção contra transformadores
【Máscara de máscara imediata Seleção de etiqueta automática】 Modelos de idiomas pré-treinados podem ser totalmente aprendizes de tiro zero
[Compressa o comprimento do vetor de entrada FID e reordená-lo ao produzir para a classificação de documentos de saída] FID-LIGHT: Geração de texto de recuperação eficiente e eficaz, geração de texto
【Explicação sobre a geração de grandes modelos】 pinto: raciocínio de linguagem fiel usando justificativas geradas por motivos solicitados
【Encontre um subconjunto de impactos pré-treinamento】 Orca: interpretar modelos de idiomas solicitados por meio de localização, apoiando evidências no oceano de dados pré-trepingos
[Projeto imediato, destinado à instrução, gera a primeira etapa e a filtragem de classificação de dois estágios] Modelos de idiomas grandes são engenheiros de prompt em nível humano
Conhecimento desaprendendo para mitigar riscos de privacidade em modelos de idiomas
Editando modelos com aritmética de tarefas
[Não insira instruções e amostras sempre, converta-as em módulos com eficiência de parâmetro,] Dica: Ajuste da instrução HyperNetwork para generalização eficiente de tiro zero
[Método de geração de exibição ICL sem seleção de amostra manual] Z-ICL: Zero Shot In Context Learning with Pseudo-Demonsronstrations
[Instrução e texto de tarefas geram incorporação] Um incorporador, qualquer tarefa: INCLIMENTOS DE TEXTO DE INSTRUÇÃO FINETUNED
【Big Model Ensine
[Problema de inconsistência entre a segmentação de palavras e o destino do modelo de geração de extração de informações] Assuntos de consistência da tokenização para modelos generativos em tarefas extrativas de PNL
Parsel: Uma estrutura de linguagem natural unificada para raciocínio algorítmico
[Seleção de amostras de ICL, seleção de primeira fase e classificação de segunda fase] Aprendizagem no contexto auto-adaptável
[Leitura intensiva, método de seleção não supervisionado por prontidão legível, em direção ao primeiro ajuste de prompt de leitura humana: The Shining é um bom filme de Kubrick, e um bom prompt também
【Prontoqa DataSet Tests Capacidade de inferência do COT e descobre que a capacidade de planejamento ainda é limitada modelos de idiomas podem (tipo de) motivo: uma análise formal sistemática da cadeia de pensamento
【Conjunto de dados de raciocínio】 wikiwy: respondendo e explicando perguntas de causa e efeito
【Conjunto de dados de raciocínio】 Rua: um raciocínio estruturado e uma explicação de várias tarefas
【Conjunto de dados de raciocínio, comparando o OPT pré-treinamento e ajuste fino, incluindo modelos de ajuste fino da COT】 Alerta: adaptação de modelos de linguagem às tarefas de raciocínio
[Resumo do recente raciocínio da equipe de Zhang Ningyu da Universidade de Zhejiang] Raciocínio com o Modelo de Língua Promoting: Uma Pesquisa
[Resumo da tecnologia e direção de geração de texto da equipe de Xiao Yanghua em Fudan] Aproveitando o conhecimento e o raciocínio para a geração de linguagem natural do tipo humano: uma breve revisão
[Resumo dos recentes artigos de raciocínio, Jie Huang, da UIUC] para o raciocínio em grandes modelos de idiomas: uma pesquisa
【Revisão de tarefas, conjuntos de dados e métodos de raciocínio matemático e DL】 Uma pesquisa de aprendizado profundo para o raciocínio matemático
Uma pesquisa sobre processamento de linguagem natural para programação
DataSet de modelagem de recompensa:
Red-teaming数据集,harmless vs. helpful, RLHF +scale更难被攻击(另一个有效的技术是CoT fine-tuning):
【知识】+【推理】+【生成】
如果对您有帮助,请star支持一下,欢迎Pull Request~
主观整理,时间上主要从ICLR 2023 Rebuttal期间开始的,包括ICLR,ACL,ICML等预印版论文。
不妥之处或者建议请指正! Dongfang Li, [email protected]


