detecting fake text
1.0.0
Detectar o texto gerado a partir de grandes modelos de linguagem (por exemplo, GPT-2).
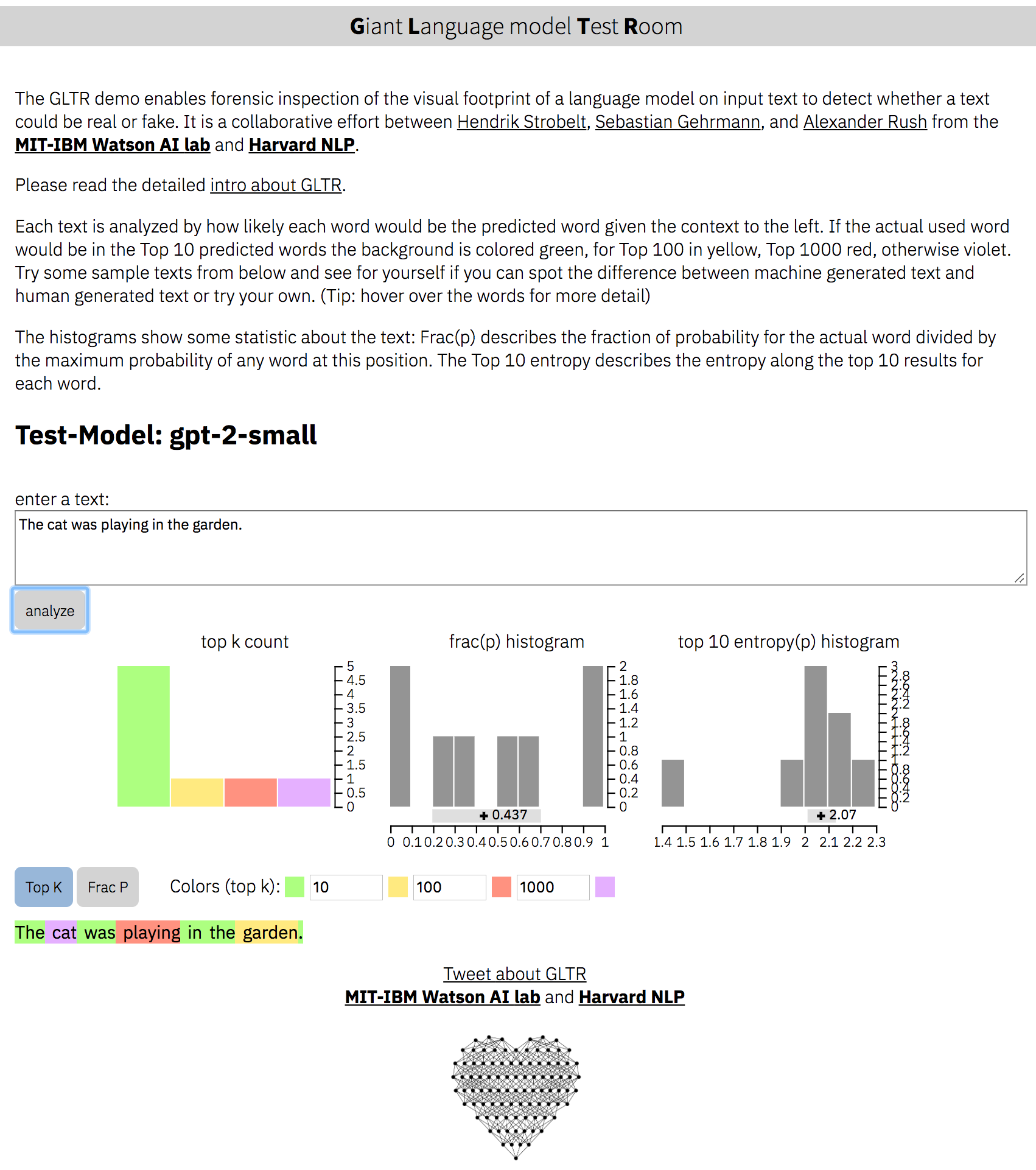
Página da Web: http://gltr.io
Online-Demo: http://gltr.io/dist/index.html
Papel: https://arxiv.org/abs/1906.04043
Um projeto de Hendrik Strobelt, Sebastian Gehrmann, Alexander M. Rush.
Colaboração do MIT-IBM Watson AI Lab e Harvardnlp
Instale dependências para Python> 3.6:
pip install -r requirements.txt Execute o servidor para gpt-2-small :
python server.py
A instância da demonstração é executada agora em http: // localhost: 5001/client/index.html
Inicie o servidor para BERT :
python server.py --model BERT A instância é executada agora em http: // localhost: 5001/client/index.html? NodeMO. Dica: fornecemos apenas textos de demonstração para gpt2-small .
usage: server.py [-h] [--model MODEL] [--nodebug NODEBUG] [--address ADDRESS]
[--port PORT] [--nocache NOCACHE] [--dir DIR] [--no_cors]
optional arguments:
-h, --help show this help message and exit
--model MODEL choose either 'gpt-2-small' (default) or 'BERT' or your own
--nodebug NODEBUG server in non-debugging mode
--port PORT port to launch UI and API (default:5001)
--no_cors launch API without CORS support (default: False)
O back -end define uma série de APIs do modelo que podem ser invocadas pelo servidor iniciando -o com o --model NAME . Para adicionar um modelo personalizado, você precisa escrever sua própria API no backend/api.py e adicionar o decorador @register_api(name=NAME) .
Cada API precisa ser uma classe que herda do AbstractLanguageChecker , que define duas funções check_probabilities e postprocess . Siga a documentação no api.py ao implementar a classe e as funções.
O código-fonte do front-end está no client/src .
Para modificar, é necessária a instalação de dependências de nós:
cd client/src ; npm install ; cd ../..Recompilação do front-end:
> rm -rf client/dist ; cd client/src/ ; npm run build ; cd ../..Apache 2
(c) 2019 por Hendrik Strobelt, Sebastian Gehrmann, Alexander M. Rush


