IncarnaMind
1.0.0
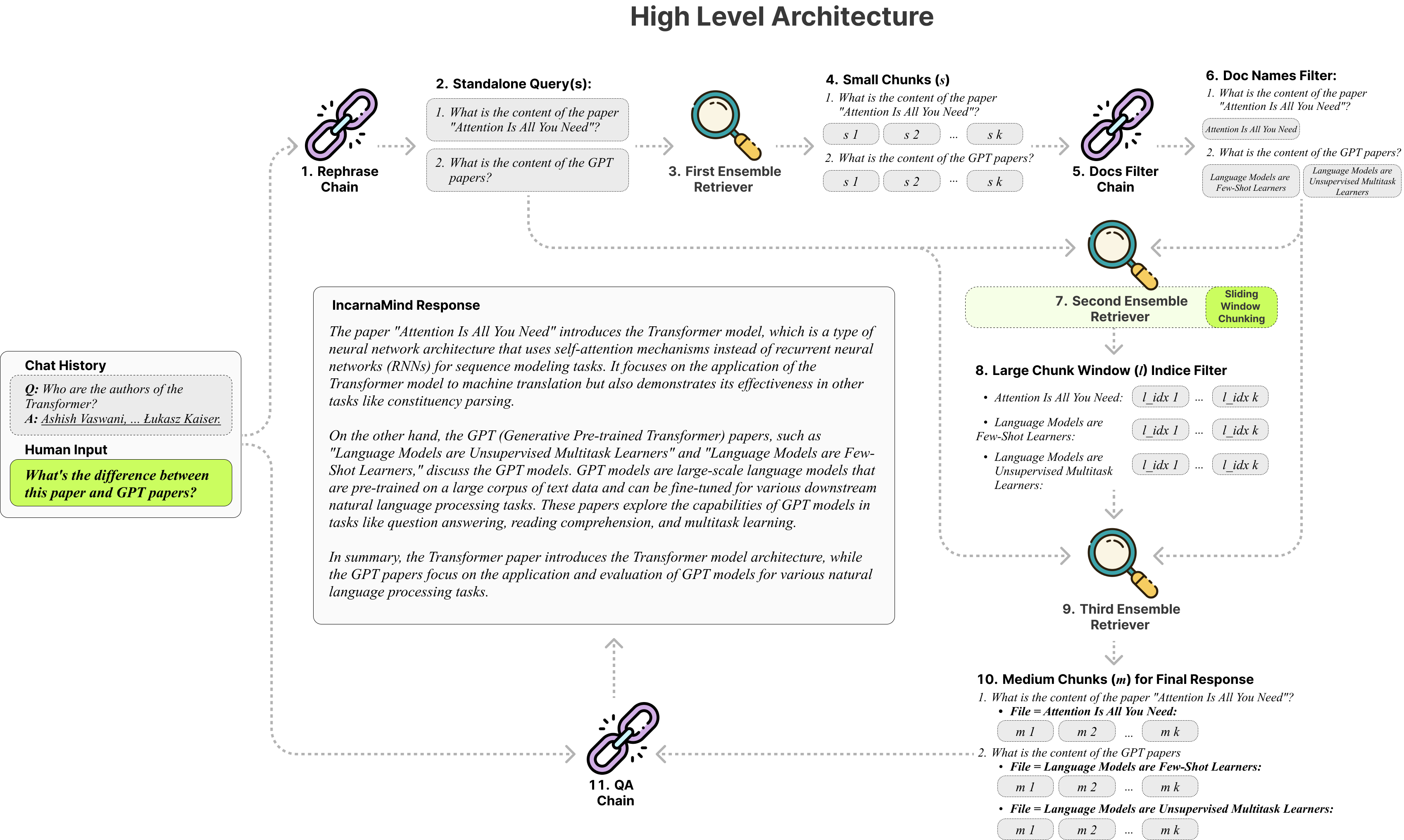
O Incarnamind permite que você converse com seus documentos pessoais? (PDF, TXT) usando modelos de idiomas grandes (LLMS) como GPT (Visão geral da arquitetura). Embora o OpenAI tenha lançado recentemente uma API de ajuste fino para modelos GPT, ele não permite que os modelos básicos pré-terem aprenda novos dados, e as respostas podem ser propensas a alucinações factuais. Utilize nosso mecanismo de chunking de janelas deslizantes e o Ensemble Retriever permite uma consulta eficiente de informações de granulação fina e grossa em seus documentos da verdade para aumentar o LLMS.
Sinta -se à vontade para usá -lo e recebemos algum feedback e novas sugestões de recursos?
Aqui está uma tabela de comparação dos diferentes modelos que testei, apenas para referência:
| Métricas | GPT-4 | GPT-3.5 | Claude 2.0 | Llama2-70b | LLAMA2-70B-GGUF | LLAMA2-70B-API |
|---|---|---|---|---|---|---|
| Raciocínio | Alto | Médio | Alto | Médio | Médio | Médio |
| Velocidade | Médio | Alto | Médio | Muito baixo | Baixo | Médio |
| GPU RAM | N / D | N / D | N / D | Muito alto | Alto | N / D |
| Segurança | Baixo | Baixo | Baixo | Alto | Alto | Baixo |
Chunking fixo : as ferramentas tradicionais de pano dependem de tamanhos de pedaços fixos, limitando sua adaptabilidade no manuseio da complexidade e contexto de dados variados.
Precisão vs. Semântica : Os métodos atuais de recuperação geralmente se concentram no entendimento semântico ou na recuperação precisa, mas raramente ambos.
Limitação de documentos únicos : Muitas soluções só podem consultar um documento de cada vez, restringindo a recuperação de informações de vários documentos.
Estabilidade : O Encarnamind é compatível com o OpenAI GPT, Claude antrópico, llama2 e outros LLMs de código aberto, garantindo análise estável.
Chunking adaptável : Nossa técnica de chunking de janela deslizante ajusta dinamicamente o tamanho e a posição da janela para o RAG, equilibrando o acesso de dados de granulação fina e granulada com base na complexidade e no contexto de dados.
QA de conversação de vários documentos : suporta consultas simples e multi-hop em vários documentos simultaneamente, quebrando a limitação de documentos únicos.
Compatibilidade do arquivo : suporta formatos de arquivo pdf e txt.
Compatibilidade do modelo LLM : suporta o OpenAI GPT, Claude antrópico, LLAMA2 e outros LLMs de código aberto.

A instalação é simples, você só precisa executar alguns comandos.
git clone https://github.com/junruxiong/IncarnaMind
cd IncarnaMindCrie o ambiente virtual do conda:
conda create -n IncarnaMind python=3.10Ativar:
conda activate IncarnaMindInstale todos os requisitos:
pip install -r requirements.txtInstale o LLAMA-CPP SEPERACLY se você quiser executar o LLMS local quantizado:
NVIDIA , use cuBLAS CMAKE_ARGS= " -DLLAMA_CUBLAS=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirM1/M2 ), use CMAKE_ARGS= " -DLLAMA_METAL=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirConfigure suas teclas de uma/todas as API no arquivo configParser.ini :
[tokens]
OPENAI_API_KEY = (replace_me)
ANTHROPIC_API_KEY = (replace_me)
TOGETHER_API_KEY = (replace_me)
# if you use full Meta-Llama models, you may need Huggingface token to access.
HUGGINGFACE_TOKEN = (replace_me)(Opcional) Configure seus parâmetros personalizados no arquivo configParser.ini :
[parameters]
PARAMETERS 1 = (replace_me)
PARAMETERS 2 = (replace_me)
...
PARAMETERS n = (replace_me)Coloque todos os seus arquivos (nomeie cada arquivo corretamente para maximizar o desempenho) no diretório /dados e execute o seguinte comando para ingerir todos os dados: (Você pode excluir arquivos de exemplo no diretório /dados antes de executar o comando)
python docs2db.pyPara iniciar a conversa, execute um comando como:
python main.pyAguarde o script exigir sua entrada como a abaixo.
Human:Quando você inicia um bate -papo, o sistema gera automaticamente um arquivo Incarnamind.log . Se você deseja editar o log, edite no arquivo configparser.ini .
[logging]
enabled = True
level = INFO
filename = IncarnaMind.log
format = %(asctime)s [%(levelname)s] %(name)s: %(message)sAgradecimentos especiais a Langchain, Chroma DB, LocalGPT, LLAMA-CPP por suas contribuições inestimáveis para a comunidade de código aberto. Seu trabalho tem sido fundamental para tornar o projeto Incarnamind uma realidade.
Se você deseja citar nosso trabalho, use a seguinte entrada do Bibtex:
@misc { IncarnaMind2023 ,
author = { Junru Xiong } ,
title = { IncarnaMind } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub Repository } ,
howpublished = { url{https://github.com/junruxiong/IncarnaMind} }
}Licença Apache 2.0


