dalle flow
1.0.0


Um humano no loop ? fluxo de trabalho para criar imagens em HD a partir de texto
Dall · e o fluxo é um fluxo de trabalho interativo para gerar imagens de alta definição a partir do prompt de texto. Primeiro, ele aproveita Dall · E-MEGA, GLID-3 XL e difusão estável para gerar candidatos a imagem e, em seguida, chama o clipe como serviço para classificar os candidatos e o prompt. O candidato preferido é alimentado ao Glid-3 XL para difusão, que geralmente enriquece a textura e o fundo. Finalmente, o candidato é subsídio para 1024x1024 via Swinir.
O fluxo Dall · E é construído com Jina em uma arquitetura cliente-servidor, que oferece alta escalabilidade, streaming sem bloqueio e uma interface pitônica moderna. O cliente pode interagir com o servidor via GRPC/WebSocket/HTTP com TLS.
Por que humano no loop? A arte generativa é um processo criativo. Enquanto os recentes avanços de Dall · E liberam a criatividade das pessoas, ter um UX/UI de saída único de saída bloqueia a imaginação em uma única possibilidade, o que é ruim, por melhor que seja esse resultado único. Dall · e o fluxo é uma alternativa à linha, formalizando a arte generativa como um procedimento iterativo.
Dall · e o fluxo está na arquitetura cliente-servidor.
grpcs://api.clip.jina.ai:2096 (requer jina >= v3.11.0 ), você precisa primeiro obter um token de acesso daqui. Consulte Use o clipe como serviço para obter mais detalhes.flow_parser.py .grpcs://dalle-flow.dev.jina.ai . Todas as conexões estão agora com a criptografia TLS, reabrir o notebook no Google Colab.p2.x8large .ViT-L/14@336px do Clip-As-Service, steps 100->200 .















































Usar o cliente é super fácil. As etapas a seguir são melhor executadas no Jupyter Notebook ou Google Colab.
Você precisará instalar DocArray e Jina primeiro:
pip install " docarray[common]>=0.13.5 " jinaFornecemos um servidor de demonstração para você jogar:
️ Devido às solicitações massivas, nosso servidor pode ser atrasado em resposta. No entanto, estamos muito confiantes em manter o tempo de atividade alto. Você também pode implantar seu próprio servidor seguindo a instrução aqui.
server_url = 'grpcs://dalle-flow.dev.jina.ai'Agora vamos definir o prompt:
prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'Vamos enviá -lo ao servidor e visualizar os resultados:
from docarray import Document
doc = Document ( text = prompt ). post ( server_url , parameters = { 'num_images' : 8 })
da = doc . matches
da . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) Aqui, geramos 24 candidatos, 8 de Dalle-Mega, 8 de Glid3 XL e 8 da difusão estável, isso é definido em num_images , que leva cerca de ~ 2 minutos. Você pode usar um valor menor se for muito longo para você.

Os 24 candidatos são classificados por clipe como serviço, com o índice 0 como o melhor candidato julgado pelo clipe. Claro, você pode pensar de maneira diferente. Observe o número no canto superior esquerdo? Selecione o que você mais gosta e obtenha uma visão melhor:
fav_id = 3
fav = da [ fav_id ]
fav . embedding = doc . embedding
fav . display ()
Agora vamos enviar os candidatos selecionados ao servidor para difusão.
diffused = fav . post ( f' { server_url } ' , parameters = { 'skip_rate' : 0.5 , 'num_images' : 36 }, target_executor = 'diffusion' ). matches
diffused . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) Isso fornecerá 36 imagens com base na imagem selecionada. Você pode permitir que o modelo improvise mais, dando skip_rate um valor próximo de zero ou um valor quase um para forçar sua proximidade com a imagem fornecida. Todo o procedimento leva cerca de ~ 2 minutos.

Selecione a imagem que você mais gosta e dê uma olhada mais de perto:
dfav_id = 34
fav = diffused [ dfav_id ]
fav . display ()
Finalmente, envie ao servidor para a última etapa: Upscaling para 1024 x 1024px.
fav = fav . post ( f' { server_url } /upscale' )
fav . display ()É isso! É o único . Se não estiver satisfeito, repita o procedimento.

BTW, o DocArray é uma estrutura de dados poderosa e fácil de usar para dados não estruturados. É super produtivo para os cientistas de dados que trabalham em domínio cruzado/multimodal. Para saber mais sobre o DocArray, consulte os documentos.
Você pode hospedar seu próprio servidor seguindo as instruções abaixo.
Dall · e o fluxo precisa de uma GPU com VRAM de 21 GB em seu pico. Todos os serviços são espremidos nesta GPU, isso inclui (aproximadamente)
config.yml , 512x512)Os seguintes truques razoáveis podem ser usados para reduzir ainda mais o VRAM:
Requer pelo menos 50 GB de espaço livre no disco rígido, principalmente para baixar modelos pré -tenhados.
A Internet de alta velocidade é necessária. A Internet lenta/instável pode lançar um tempo limite frustrante ao baixar modelos.
O ambiente somente CPU não é testado e provavelmente não funcionará. O Google Colab provavelmente está jogando oom, portanto, também não funcionará.

Se você instalou Jina, o fluxograma acima pode ser gerado via:
# pip install jina
jina export flowchart flow.yml flow.svgSe você deseja usar difusão estável, primeiro precisará registrar uma conta no site Huggingface e concordar com os termos e condições do modelo. Depois de fazer login, você pode encontrar a versão do modelo exigido por aqui:
Compvis / SD-V1-5-Inpainting.ckpt
Sob a seção Download na seção de pesos , clique no link para sd-v1-x.ckpt . Os pesos mais recentes no momento da redação são sd-v1-5.ckpt .
Usuários do Docker : Coloque esse arquivo em uma pasta chamada ldm/stable-diffusion-v1 e renomeie It model.ckpt . Siga as instruções abaixo com cuidado porque o SD não está ativado por padrão.
Usuários nativos : Coloque esse arquivo em dalle/stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt depois de terminar o restante das etapas em "Run Native". Siga as instruções abaixo com cuidado porque o SD não está ativado por padrão.
Fornecemos uma imagem do Docker pré -construída que pode ser puxada diretamente.
docker pull jinaai/dalle-flow:latestFornecemos um Dockerfile que permite executar um servidor pronta para uso.
Nosso DockerFile está usando o CUDA 11.6 Como imagem base, você pode ajustá -lo de acordo com o seu sistema.
git clone https://github.com/jina-ai/dalle-flow.git
cd dalle-flow
docker build --build-arg GROUP_ID= $( id -g ${USER} ) --build-arg USER_ID= $( id -u ${USER} ) -t jinaai/dalle-flow .O edifício levará 10 minutos com a velocidade média da Internet, o que resulta em uma imagem do Docker de 18 GB.
Para executá -lo, simplesmente faça:
docker run -p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowComo alternativa, você também pode ser executado com alguns fluxos de trabalho ativados ou desativados para evitar falhas fora da memória. Para fazer isso, passe uma dessas variáveis ambientais:
DISABLE_DALLE_MEGA
DISABLE_GLID3XL
DISABLE_SWINIR
ENABLE_STABLE_DIFFUSION
ENABLE_CLIPSEG
ENABLE_REALESRGAN
Por exemplo, se você deseja desativar os fluxos de trabalho GLID3XL, execute:
docker run -e DISABLE_GLID3XL= ' 1 '
-p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow-v $HOME/.cache:/root/.cache evita o download de modelo repetido em todas as execuções do Docker.-p 51005:51005 é o seu porto público host. Certifique -se de que as pessoas possam acessar esta porta se você estiver servindo publicamente. O segundo par é a porta definida no fluxo.yml.ENABLE_STABLE_DIFFUSION .ENABLE_CLIPSEG .ENABLE_REALESRGAN . A difusão estável só pode ser ativada se você baixar os pesos e disponibilizá -los como um volume virtual enquanto habilita o sinalizador ambiental ( ENABLE_STABLE_DIFFUSION ) para SD .
Você deveria ter colocado os pesos anteriormente em uma pasta chamada ldm/stable-diffusion-v1 e rotulada para model.ckpt . Substitua YOUR_MODEL_PATH/ldm abaixo pelo caminho em seu próprio sistema para colocar os pesos na imagem do Docker.
docker run -e ENABLE_STABLE_DIFFUSION= " 1 "
-e DISABLE_DALLE_MEGA= " 1 "
-e DISABLE_GLID3XL= " 1 "
-p 51005:51005
-it
-v YOUR_MODEL_PATH/ldm:/dalle/stable-diffusion/models/ldm/
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowVocê deve ver a tela como seguir uma vez em execução:
Observe que, diferentemente da execução de nativamente, a execução dentro do Docker pode fornecer uma barra de progresso menos vívida, toras de cores e impressões. Isso se deve às limitações do terminal em um recipiente do docker. Não afeta o uso real.
A execução nativamente requer algumas etapas manuais, mas geralmente é mais fácil depurar.
mkdir dalle && cd dalle
git clone https://github.com/jina-ai/dalle-flow.git
git clone https://github.com/jina-ai/SwinIR.git
git clone --branch v0.0.15 https://github.com/AmericanPresidentJimmyCarter/stable-diffusion.git
git clone https://github.com/CompVis/latent-diffusion.git
git clone https://github.com/jina-ai/glid-3-xl.git
git clone https://github.com/timojl/clipseg.gitVocê deve ter a seguinte estrutura de pastas:
dalle/
|
|-- Real-ESRGAN/
|-- SwinIR/
|-- clipseg/
|-- dalle-flow/
|-- glid-3-xl/
|-- latent-diffusion/
|-- stable-diffusion/
cd dalle-flow
python3 -m virtualenv env
source env/bin/activate && cd -
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
pip install numpy tqdm pytorch_lightning einops numpy omegaconf
pip install https://github.com/crowsonkb/k-diffusion/archive/master.zip
pip install git+https://github.com/AmericanPresidentJimmyCarter/[email protected]
pip install basicsr facexlib gfpgan
pip install realesrgan
pip install https://github.com/AmericanPresidentJimmyCarter/xformers-builds/raw/master/cu116/xformers-0.0.14.dev0-cp310-cp310-linux_x86_64.whl &&
cd latent-diffusion && pip install -e . && cd -
cd stable-diffusion && pip install -e . && cd -
cd SwinIR && pip install -e . && cd -
cd glid-3-xl && pip install -e . && cd -
cd clipseg && pip install -e . && cd -Existem casais modelos que precisamos baixar para Glid-3-XL se você estiver usando isso:
cd glid-3-xl
wget https://dall-3.com/models/glid-3-xl/bert.pt
wget https://dall-3.com/models/glid-3-xl/kl-f8.pt
wget https://dall-3.com/models/glid-3-xl/finetune.pt
cd - clipseg e RealESRGAN exigem que você defina um caminho de pasta de cache correto, normalmente algo como $ home/.
cd dalle-flow
pip install -r requirements.txt
pip install jax~=0.3.24 Agora você está sob dalle-flow/ , execute o seguinte comando:
# Optionally disable some generative models with the following flags when
# using flow_parser.py:
# --disable-dalle-mega
# --disable-glid3xl
# --disable-swinir
# --enable-stable-diffusion
python flow_parser.py
jina flow --uses flow.tmp.ymlVocê deve ver esta tela imediatamente:

Na primeira partida, levará ~ 8 minutos para baixar o modelo Dall · E mega e outros modelos necessários. As execuções do processo devem levar apenas 1 minuto para alcançar a mensagem de sucesso.
Quando tudo estiver pronto, você verá:
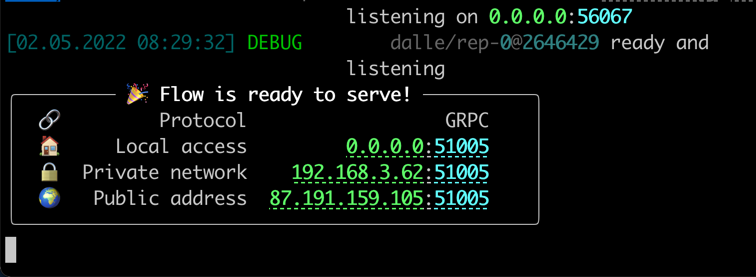
Parabéns! Agora você deve ser capaz de executar o cliente.
Você pode modificar e estender o fluxo do servidor como desejar, por exemplo, alterando o modelo, adicionando persistência ou até mesmo para o Instagram/OpenSea. Com Jina e DocArray, você pode facilmente tornar o fluxo nativo da nuvem de fluxo e pronto para a produção.
Para reduzir o uso do VRAM, você pode usar o CLIP-as-service como um executor externo disponível livremente em grpcs://api.clip.jina.ai:2096 .
Primeiro, verifique se você criou um token de acesso no site do console, ou CLI como seguinte
jina auth token create < name of PAT > -e < expiration days > Em seguida, você precisa alterar as configurações relacionadas ao Executor ( host , port , external , tls e grpc_metadata ) do flow.yml .
...
- name : clip_encoder
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [gateway]
...
- name : rerank
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
uses_requests :
' / ' : rank
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [dalle, diffusion] Você também pode usar o flow_parser.py para gerar e executar automaticamente o fluxo com o uso do CLIP-as-service como executor externo:
python flow_parser.py --cas-token " <your access token>'
jina flow --uses flow.tmp.yml
️ grpc_metadataestá disponível apenas após Jinav3.11.0. Se você estiver usando uma versão mais antiga, atualize para a versão mais recente.
Agora, você pode usar o CLIP-as-service gratuito em seu fluxo.
O fluxo Dall · E é apoiado por Jina AI e licenciado no Apache-2.0. Estamos contratando ativamente engenheiros de IA, engenheiros de solução para construir o próximo ecossistema de busca neural em código aberto.


