GPTCache
v0.1.44
Slash seu LLM API custa em 10x?, Aumente a velocidade por 100x ⚡
? O GPTCACHE foi totalmente integrado com? ️? Langchain! Aqui estão instruções de uso detalhadas.
? A imagem do Docker do Servidor Gptcache foi lançada, o que significa que qualquer idioma poderá usar o GPTCache!
? Este projeto está passando por um desenvolvimento rápido e, como tal, a API pode estar sujeita a alterações a qualquer momento. Para obter as informações mais atualizadas, consulte a documentação mais recente e a nota de lançamento.
Nota: Como o número de modelos grandes está crescendo explosivamente e sua forma de API está em constante evolução, não adicionamos mais suporte para novas API ou modelos. Incentivamos o uso do uso da API GET e Set em GPTCache, aqui está o código de demonstração: https://github.com/zilliztech/gptcache/blob/main/examples/adapter/api.py
pip install gptcache
O ChatGPT e vários modelos de idiomas grandes (LLMS) possuem versatilidade incrível, permitindo o desenvolvimento de uma ampla gama de aplicações. No entanto, à medida que seu aplicativo cresce em popularidade e encontra níveis mais altos de tráfego, as despesas relacionadas às chamadas da API da LLM podem se tornar substanciais. Além disso, os serviços da LLM podem exibir tempos de resposta lentos, especialmente ao lidar com um número significativo de solicitações.
Para enfrentar esse desafio, criamos o GPTCache, um projeto dedicado a criar um cache semântico para armazenar respostas do LLM.
Observação :
python --versionpython -m pip install --upgrade pip . # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py installEsses exemplos ajudarão você a entender como usar a correspondência exata e semelhante com o cache. Você também pode executar o exemplo no COLAB. E mais exemplos que você pode consultar o bootcamp
Antes de executar o exemplo, verifique se a variável de ambiente OpenAI_API_KEY está definida executando echo $OPENAI_API_KEY .
Se ainda não estiver definido, pode ser definido usando export OPENAI_API_KEY=YOUR_API_KEY nos sistemas Unix/Linux/MacOS ou set OPENAI_API_KEY=YOUR_API_KEY nos sistemas Windows.
É importante observar que esse método é efetivo apenas temporariamente; portanto, se você deseja um efeito permanente, precisará modificar o arquivo de configuração da variável de ambiente. Por exemplo, em um Mac, você pode modificar o arquivo localizado em
/etc/profile.
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Se você fizer o ChatGPT exatamente as mesmas duas perguntas, a resposta para a segunda pergunta será obtida no cache sem solicitar o ChatGPT novamente.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Depois de obter uma resposta do ChatGPT em resposta a várias perguntas semelhantes, as respostas às perguntas subsequentes podem ser recuperadas do cache sem a necessidade de solicitar o ChatGPT novamente.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Você sempre pode passar um parâmetro de temperatura enquanto solicita o serviço ou modelo da API.
A faixa de
temperatureé [0, 2], o valor padrão é 0,0.Uma temperatura mais alta significa uma possibilidade maior de pular a pesquisa de cache e solicitar um modelo grande diretamente. Quando a temperatura for 2, ele pula o cache e envia uma solicitação para o modelo grande diretamente, com certeza. Quando a temperatura for 0, ele pesquisará o cache antes de solicitar um grande serviço de modelo.
O padrão
post_process_messages_funcétemperature_softmax. Nesse caso, consulte a referência da API para saber comotemperatureafeta a saída.
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])Para usar exclusivamente o GPTCache, apenas as seguintes linhas de código são necessárias e não há necessidade de modificar qualquer código existente.
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()Mais documentos:
O GPTCache oferece os seguintes benefícios primários:
Os serviços on -line geralmente exibem localidade de dados, com os usuários acessar frequentemente o conteúdo popular ou de tendências. Os sistemas de cache aproveitam esse comportamento armazenando dados comumente acessados, o que, por sua vez, reduz o tempo de recuperação de dados, melhora os tempos de resposta e facilita a carga nos servidores de back -end. Os sistemas de cache tradicionais normalmente utilizam uma correspondência exata entre uma nova consulta e uma consulta em cache para determinar se o conteúdo solicitado está disponível no cache antes de buscar os dados.
No entanto, o uso de uma abordagem de correspondência exata para caches LLM é menos eficaz devido à complexidade e variabilidade das consultas LLM, resultando em uma baixa taxa de acerto de cache. Para resolver esse problema, o GPTCache adota estratégias alternativas, como o cache semântico. O cache semântico identifica e armazena consultas semelhantes ou relacionadas, aumentando assim a probabilidade de atingimento de cache e aumentando a eficiência geral do cache.
A GPTCache emprega algoritmos de incorporação para converter consultas em incorporação e usa uma loja de vetores para pesquisa de similaridade nessas incorporações. Esse processo permite que o GPTCache identifique e recupere consultas semelhantes ou relacionadas do armazenamento de cache, conforme ilustrado na seção Módulos.
Apresentando um design modular, o GPTCache facilita para os usuários personalizar seu próprio cache semântico. O sistema oferece várias implementações para cada módulo, e os usuários podem até desenvolver suas próprias implementações para atender às suas necessidades específicas.
Em um cache semântico, você pode encontrar falsos positivos durante hits de cache e falsos negativos durante as perdas do cache. A GPTCache oferece três métricas para avaliar seu desempenho, que são úteis para os desenvolvedores otimizarem seus sistemas de cache:
Um benchmark de amostra está incluído para os usuários começarem a avaliar o desempenho de seu cache semântico.
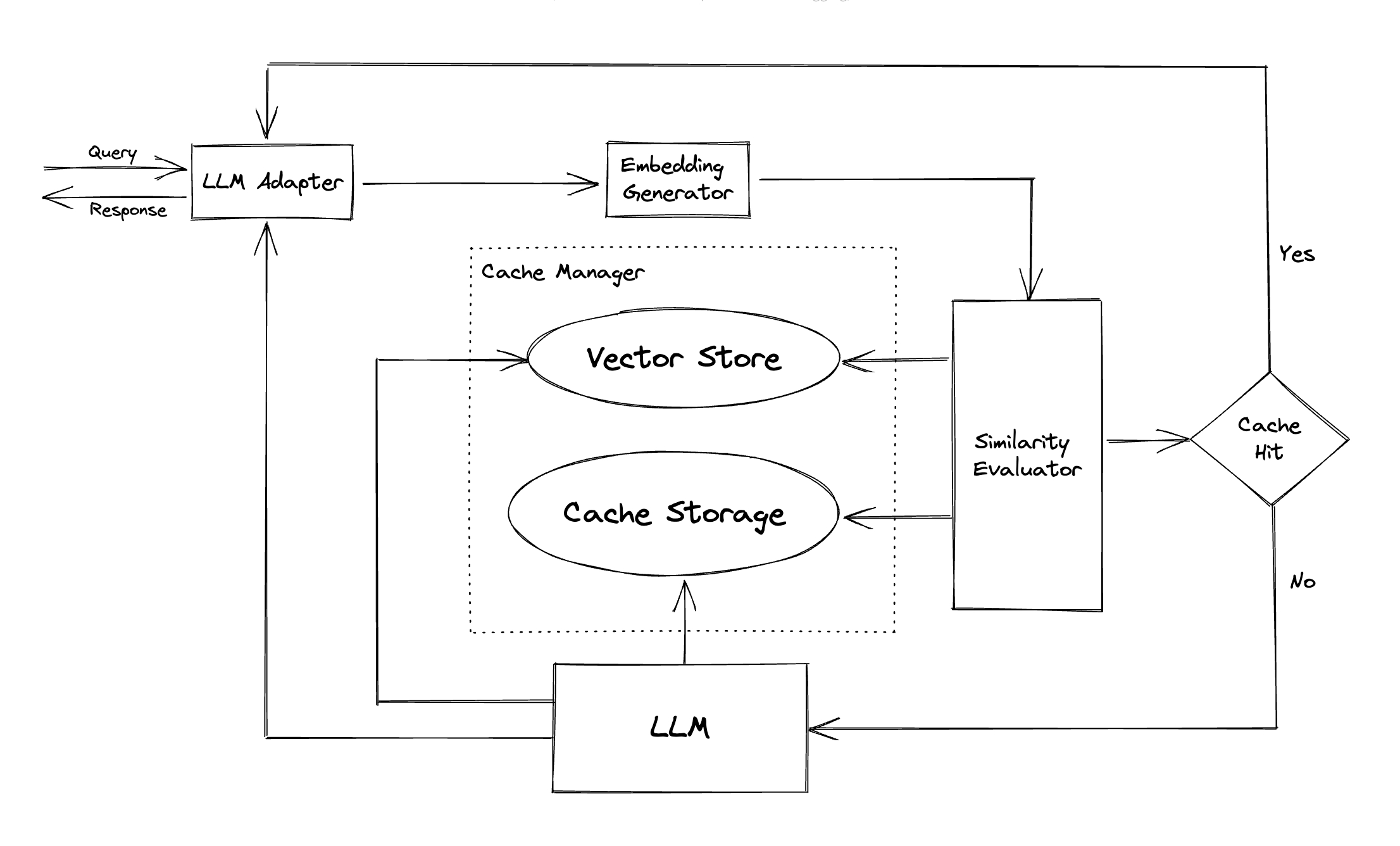
Adaptador LLM : O adaptador LLM foi projetado para integrar diferentes modelos LLM, unificando suas APIs e solicitando protocolos. O GPTCache oferece uma interface padronizada para esse fim, com suporte atual para a integração do ChatGPT.
Adaptador multimodal (experimental) : O adaptador multimodal foi projetado para integrar diferentes modelos multimodais diferentes, unificando suas APIs e solicitando protocolos. O GPTCache oferece uma interface padronizada para esse fim, com suporte atual para integrações de geração de imagens, transcrição de áudio.
Gerador de incorporação : Este módulo é criado para extrair incorporações de solicitações de pesquisa de similaridade. O GPTCache oferece uma interface genérica que suporta várias APIs de incorporação e apresenta uma variedade de soluções para escolher.
Armazenamento de cache : o armazenamento de cache é onde a resposta do LLMS, como o ChatGPT, é armazenada. As respostas em cache são recuperadas para ajudar na avaliação da similaridade e são devolvidas ao solicitante se houver uma boa correspondência semântica. Atualmente, o GPTCache suporta o SQLite e oferece uma interface universalmente acessível para extensão deste módulo.
Vector Store : O módulo Vector Store ajuda a encontrar as solicitações mais semelhantes da incorporação extraída da solicitação de entrada. Os resultados podem ajudar a avaliar a semelhança. O GPTCache fornece uma interface amigável que suporta várias lojas de vetores, incluindo Milvus, Zilliz Cloud e FAISS. Mais opções estarão disponíveis no futuro.
Cache Manager : O Cache Manager é responsável por controlar a operação do armazenamento de cache e do Vector Store .
cachetools do Python ou de maneira distribuída usando o Redis como uma loja de valores-chave.Atualmente, o GPTCache toma decisões sobre despejos baseados apenas no número de linhas. Essa abordagem pode resultar em avaliação imprecisa de recursos e pode causar erros de fora da memória (OOM). Estamos investigando e desenvolvendo ativamente uma estratégia mais sofisticada.
Se você escalar sua implantação do GPTCACHE em horizontalmente usando o cache de memória, não será possível. Como as informações em cache seriam limitadas ao único pod.
Com o cache distribuído, as informações de cache consistentes em todas as réplicas que podemos usar lojas de cache distribuídas como o Redis.
Avaliador de similaridade : Este módulo coleta dados do armazenamento de cache e do Vector Store e usa várias estratégias para determinar a semelhança entre a solicitação de entrada e as solicitações do Vector Store . Com base nessa semelhança, ele determina se uma solicitação corresponde ao cache. O GPTCache fornece uma interface padronizada para integrar várias estratégias, juntamente com uma coleção de implementações para usar. As definições de similaridade a seguir são apoiadas atualmente ou serão suportadas no futuro:
Nota : Nem todas as combinações de diferentes módulos podem ser compatíveis entre si. Por exemplo, se desativarmos o extrator de incorporação , o Vector Store poderá não funcionar como pretendido. No momento, estamos trabalhando na implementação de uma verificação de sanidade combinada para o GPTCACHACH .
Em breve! Fique atento!
Estamos extremamente abertos a contribuições, seja por meio de novos recursos, infraestrutura aprimorada ou documentação aprimorada.
Para obter instruções abrangentes sobre como contribuir, consulte nosso Guia de Contribuição.


