JARVIS ChatGPT
1.0.0
Um assistente interativo baseado em voz equipado com uma variedade de vozes sintéticas (incluindo a voz de Jarvis de Ironman)
 Imagem de Midjourney Ai
Imagem de Midjourney Ai
Já sonhou em pedir dicas de sistema hiper-intelligente para melhorar sua armadura? Agora você pode! Bem, talvez não a parte da armadura ... Este projeto explora o OpenAi Whisper, o Openai Chatgpt e o IBM Watson.
Motivação do projeto:
Muitas vezes as idéias vêm no pior momento e desaparecem antes de você ter tempo para explorá -las melhor. O objetivo deste projeto é desenvolver um sistema capaz de fornecer dicas e opiniões em quase-real-time sobre qualquer coisa que você peça. O Ultimate Assistant poderá ser acessado a partir de qualquer microfone autorizado dentro de sua casa ou telefone, ele deve funcionar constantemente em segundo plano e, quando convocado, deve ser capaz de gerar respostas significativas (com uma voz foda), além de interagir com o PC ou um servidor e salvar/ler/escrever arquivos que podem ser acessados posteriormente. Ele deve ser capaz de executar pesquisas, reunir material da Internet (extrair conteúdo das páginas HTML, transcrever vídeos do YouTube, encontrar trabalhos científicos ...) e fornecer resumos que podem ser usados como contexto para tomar decisões informadas. Além disso, pode interagir com alguns gadgets externos (IoT), mas isso é extra.
Demonstração:
Posso compartilhar o primeiro rascunho do modo de pesquisa. Essa modalidade era pensada para as pessoas que frequentemente lidam com trabalhos de pesquisa.
PS: Este modo não é super estável e precisa ser trabalhado em
PPS: Este projeto será descontinuado por algum tempo, pois estarei trabalhando na minha tese até 2024. No entanto, já existem tantas coisas que podem ser melhoradas, então voltarei!
ISENÇÃO DE RESPONSABILIDADE:
O projeto pode consumir seu crédito OpenAI, resultando em cobrança indesejada;
Não assumo a responsabilidade por nenhuma acusação indesejada;
Considere definir limitações no consumo de crédito na sua conta OpenAI;
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 );Você pode confiar na nova
setup.batque fará a maioria das coisas para você.
Script principal que você deve executar: openai_api_chatbot.py Se desejar usar a versão mais recente da API OpenAI dentro da pasta Demos, você encontrará algumas orientações para os pacotes usados no projeto, se tiver erros, você poderá verificar esses arquivos primeiro para direcionar o problema. Principalmente é armazenado na pasta Assistant: get_audio.py armazena todas as funções para lidar com interações com microfones, tools.py voice.py Agents.py lide a parte Langchain do sistema (aqui você pode adicionar ou remover ferramentas dos kits de ferramentas dos agentes)
Os scripts restantes são suplementares à geração de voz e não devem ser editados.
Você pode executar setup.bat se estiver executando no Windows/Linux. O script executará todas as etapas da instalação manual em sequência. Consulte os que, caso o procedimento falhe.
A instalação automática também executará o Vicuna Instalação (Vicuna Instalation Guide)
pip install -r venv_requirements.txt ; Isso pode levar algum tempo; Se você encontrar conflitos em pacotes específicos, instale -os manualmente sem o ==<version> ;whisper_edits na pasta whisper do seu ambiente (. Venv lib site-packages whisper ) Essas edições adicionarão apenas um atributo ao modelo de sussurro para acessar sua dimensão mais facilmente;demos/tts_demo.py ); cd Vicuna
call vicuna.ps1
env.txt e renomeie -o para .env (sim, remova a extensão txt)torch.cuda.is_available() e torch.cuda.get_device_name(0) dentro de Pyhton; .tests.py . Essa tentativa de executar operações básicas que podem levantar erros;VirtualAssistant.__init__() ; 
__main__() em whisper_model = whisper.load_model("large") ; Mas espero que sua memória GPU seja grande da mesma forma. openai_api_chatbot.py ):Ao executar, você verá muitas informações sendo exibidas. Estou constantemente me esforçando para melhorar a legibilidade da execução, todo o projeto é uma enorme beta, perdoa pequenas variações das telas abaixo. Enfim, é isso que acontece em termos gerais quando você atinge 'run':
Jarvis para convocar o assistente. Neste ponto, uma conversa começará e você poderá falar em qualquer idioma que desejar (se seguiu a etapa 2). A conversa será encerrada quando você 1) dizer uma palavra de parada 2) diga algo com uma palavra (como 'ok') 3) quando você para de fazer perguntas por mais de 30 segundos 
chat_history com sua pergunta, ele enviará uma solicitação com a API e atualizará o histórico assim que receber uma resposta completa do ChatGPT (isso pode levar até 5 a 10 segundos, considere explicitamente pedir uma resposta curta se estiver com pressa);say() executará a duplicação de voz para falar com a voz de Jarvis/alguém; Se o argumento não estiver em inglês, o IBM Watson enviará a resposta de um de seus bons modelos de texto para fala. Se tudo falhar, as funções dependerão do pyttsx3, que é uma alternativa rápida, mas não tão legal;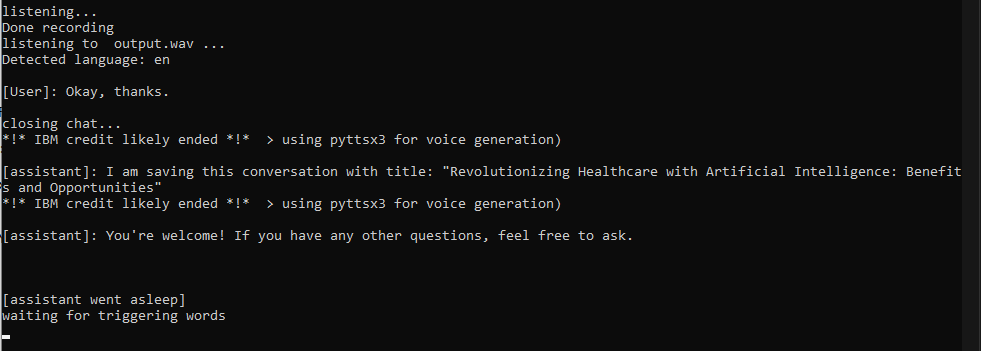
Eu fiz algumas solicitações e encerrei a conversa
Não é o ideal que eu conheço, mas funciona por enquanto
VirtualAssistant completa com memória e acesso de armazenamento local atualmente trabalhando em:
seguindo:
Verifique o UpdateHistory.md do projeto para obter mais informações.
Divirta-se!
Categorias: Instale, Geral, Tempo de Execução
O problema é sobre sussurro. Você deve reinstalá-lo manualmente com pip install whisper-openai
pip install --upgrade openai . Os requisitos não são atualizados a cada compromisso. Embora isso possa gerar erros, você pode instalar rapidamente os módulos que faltavam, ao mesmo tempo em que mantém o ambiente limpo de conflitos quando eu tento novos pacotes (e tento muitos deles)
Isso significa que o modelo que você selecionou é grande demais para a memória do dispositivo CUDA. Infelizmente, não há muito que você possa fazer sobre isso, exceto carregar um modelo menor. Se o modelo menor não o satisfazer, convém falar 'mais claro' ou fazer com que os prompts mais longos permitam que o modelo preveja com mais precisão o que você está dizendo. Isso parece inconveniente, mas, no meu caso, melhorou bastante minha língua inglesa :)
Este ainda é um bug presente, não espere ter longas conversas com seu assistente, pois simplesmente terá memória suficiente para lembrar toda a conversa em algum momento. Uma correção está em desenvolvimento, pode consistir em adotar uma abordagem de 'janelas deslizantes', mesmo que possa causar repetição de alguns conceitos.
No momento (abril de 2023), estou trabalhando quase sem parar nisso. Provavelmente vou fazer uma pausa no verão porque estarei trabalhando na minha tese.
Se você tiver dúvidas, pode entrar em contato comigo levantando um problema e farei o possível para ajudar o mais rápido possível.
Gianmarco Guarnier


