Deep RL Keras
1.0.0
Implementação modular de algoritmos populares de aprendizado de reforço profundo em Keras:
Esta implementação requer Keras 2.1.6, bem como a academia Openai.
$ pip install gym keras==2.1.6O algoritmo ator-crítico é um método fora da política, sem modelo, onde o crítico atua como um aproximador da função de valor e o ator como um aproximador da função política. Ao treinar, o crítico prevê o erro TD e orienta o aprendizado de si mesmo e do ator. Na prática, aproximamos o erro TD usando a função de vantagem. Para mais estabilidade, usamos um backbone computacional compartilhado em ambas as redes, bem como uma formulação N das recompensas com desconto. Também incorporamos um termo de regularização de entropia (aprendizado "suave" para incentivar a exploração. Embora o A2C seja simples e eficiente, executá -lo nos jogos Atari rapidamente se torna intratável devido ao longo tempo de computação.
De maneira semelhante à do algoritmo A2C, a implementação do A3C incorpora atualizações de peso assíncronas, permitindo computação muito mais rápida. Utilizamos vários agentes para executar a ascensão de gradiente de forma assíncrona, em vários threads. Testamos A3C no ambiente Atari Breakout.
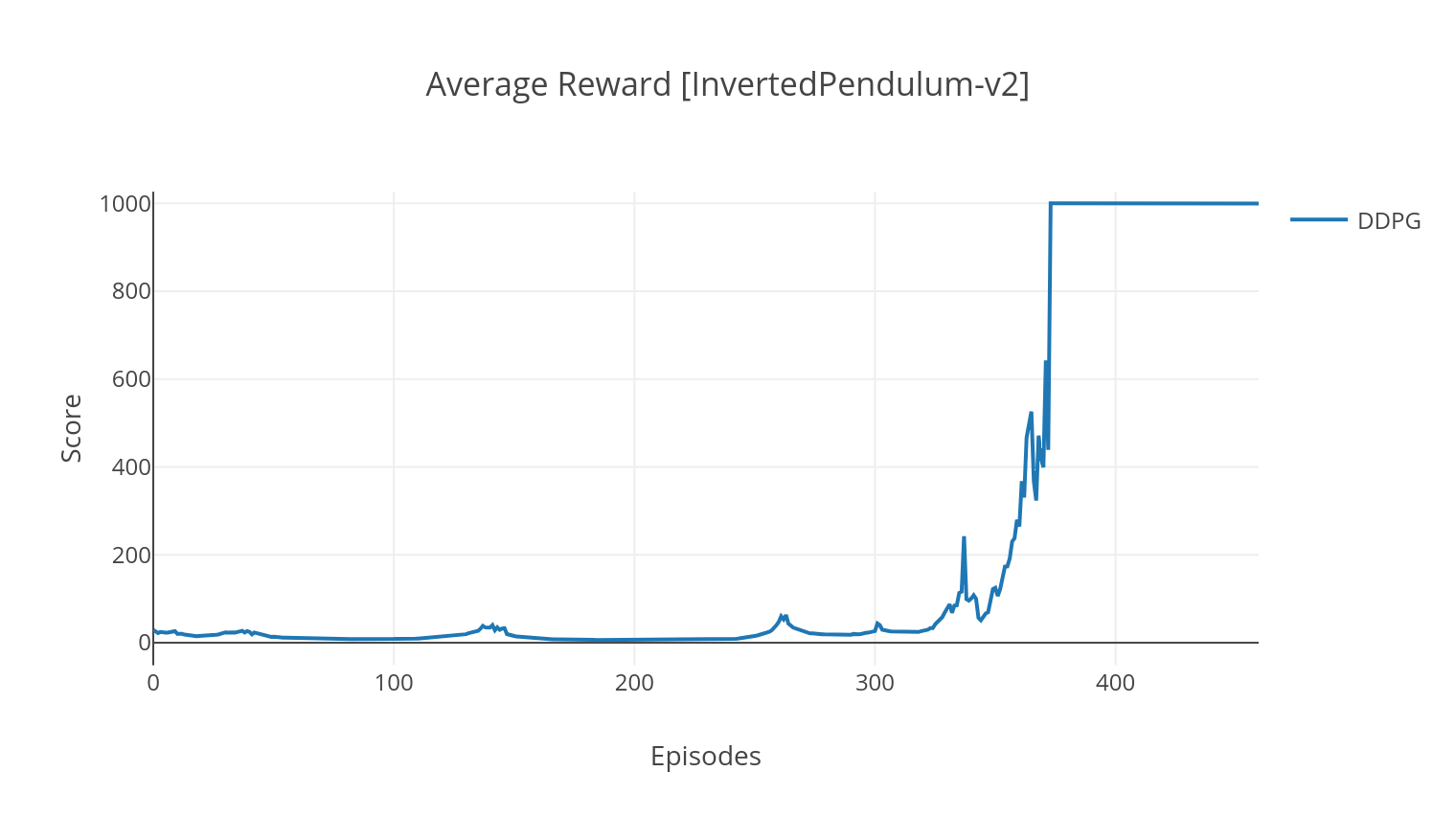
O algoritmo DDPG é um algoritmo fora de política sem modelo para espaços de ação contínua. Da mesma forma que A2C, é um algoritmo de ator crítico no qual o ator é treinado em uma política de destino determinística, e o crítico prevê valores Q. Para reduzir a variação e aumentar a estabilidade, usamos a experiência de reprodução e as redes de destino separadas. Além disso, como sugerido pelo OpenAI, incentivamos a exploração por meio do ruído do espaço dos parâmetros (em oposição ao ruído do espaço de ação tradicional). Testamos o DDPG no ambiente Lunar Lander.
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2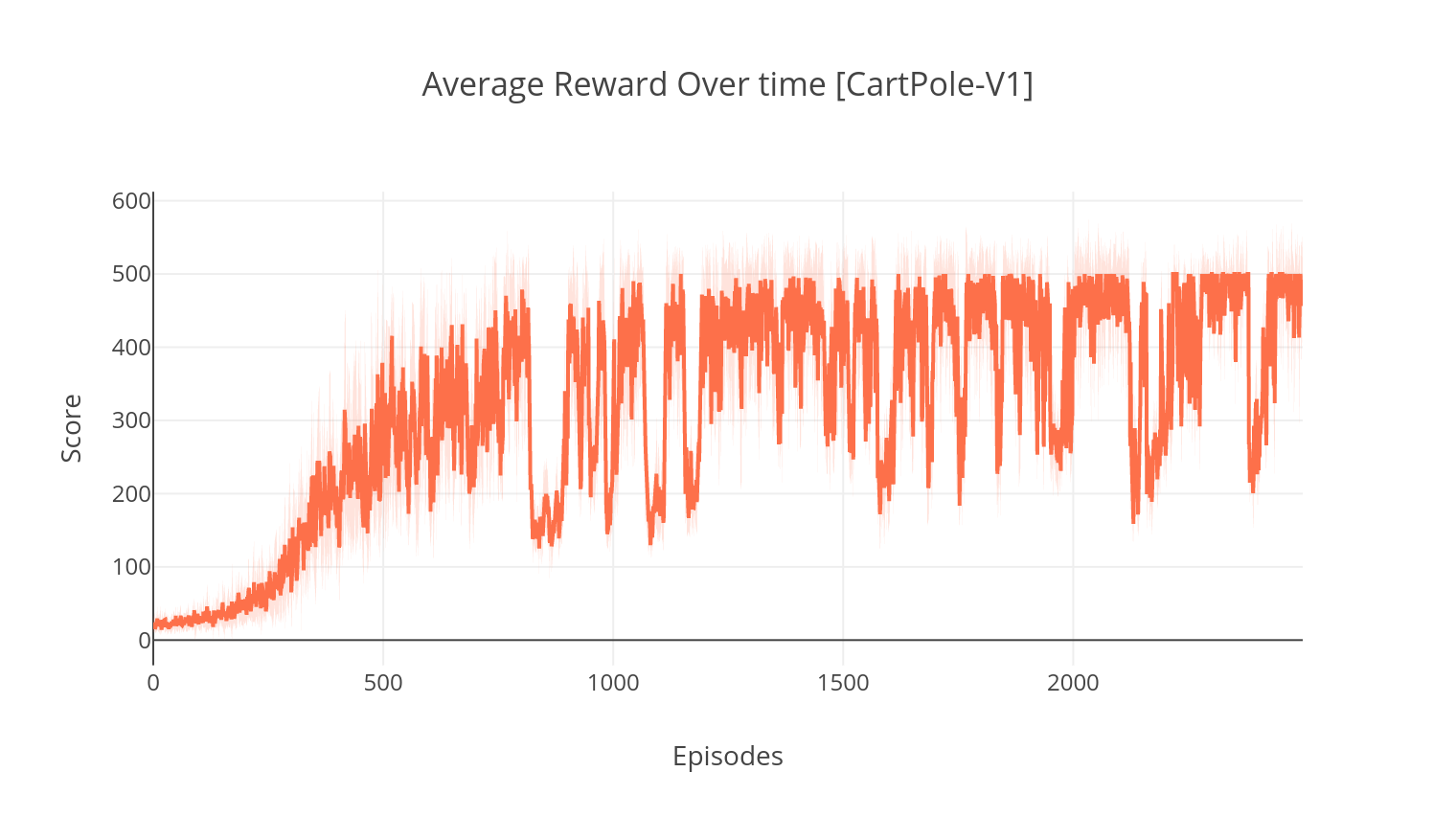
O algoritmo DQN é um algoritmo Q-Learning, que usa uma rede neural profunda como um aproximador da função de valor Q. Estimamos os valores Q-Al-Target, alavancando a equação Bellman e reunimos experiência por meio de uma política de Epsilon-Greedy. Para mais estabilidade, experimentamos experiências passadas aleatoriamente (Replay). Uma variante do algoritmo DQN é o duplo DQN (ou DDQN). Para uma estimativa mais precisa de nossos valores Q, usamos uma segunda rede para modelar as superestimações dos valores Q pela rede original. Essa rede de destino é atualizada a uma taxa mais lenta, a cada etapa de treinamento.
Podemos melhorar ainda mais nosso algoritmo DDQN, adicionando a experiência priorizada (PER), que visa realizar amostragem de importância na experiência coletada. A experiência é classificada por seu erro TD e armazenada em uma estrutura de Sumtree, que permite uma recuperação eficiente das transições (S, A, R, S ') com o maior erro.
Na variante de duelo do DQN, incorporamos uma camada intermediária na rede Q para estimar o valor do estado e a função de vantagem dependente do estado. Após a reformulação (ver Ref), acontece que podemos expressar o valor Q estimado como o valor do estado, ao qual adicionamos a estimativa de vantagem e subtraia sua média. Essa fatoração de valores independentes do estado e dependente do estado ajuda a desembaraçar o aprendizado entre as ações e produz melhores resultados.
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling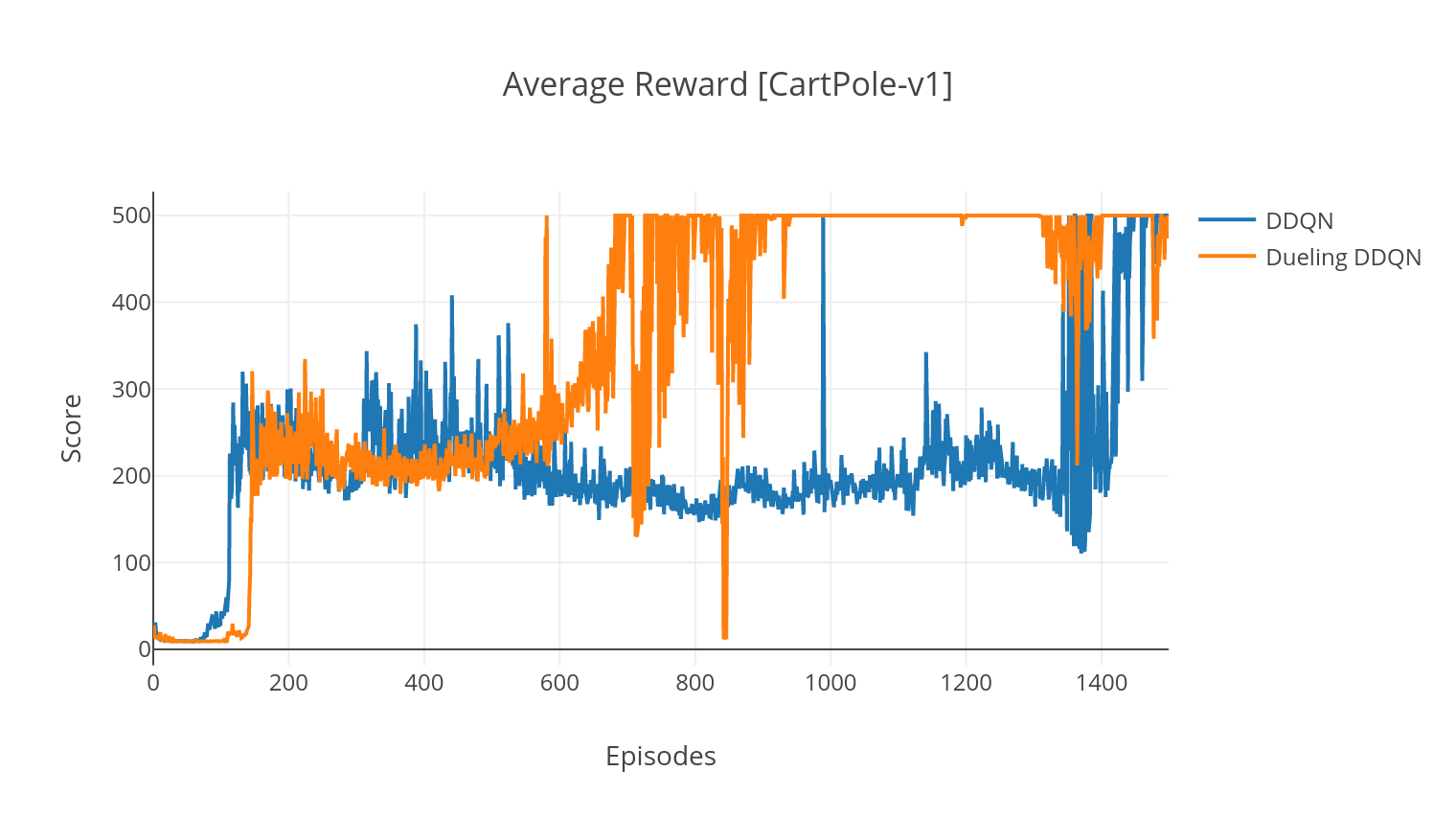
| Argumento | Descrição | Valores |
|---|---|---|
| --tipo | Tipo de algoritmo RL para executar | Escolha entre {a2c, a3c, ddqn, ddpg} |
| --env | Especifique o ambiente | Breakoutnoframeskip-v4 (padrão) |
| --NB_EPISODES | Número de episódios para executar | 5000 (padrão) |
| --atch_size | Tamanho do lote (DDQN, DDPG) | 32 (padrão) |
| -Consecutive_frames | Número de quadros consecutivos empilhados | 4 (padrão) |
| --is_atari | Se o ambiente é um jogo Atari com entrada de pixels | - |
| --with_per | Se deve usar a experiência priorizada (com DDQN) | - |
| -duelo | Se deve usar redes de duelo (com DDQN) | - |
| --n_threads | Número de threads (A3C) | 16 (padrão) |
| --Gather_stats | Se deve calcular estatísticas de pontuações em média em mais de 10 jogos (lentamente, veja abaixo) | - |
| -Render | Se deve renderizar o meio ambiente como está treinando | - |
| --GPU | Índice de GPU | 0 |
Todos os modelos são salvos em <algorithm_folder>/models/ quando terminar o treinamento. Você pode visualizá -los em execução no mesmo ambiente em que foram treinados executando o script load_and_run.py . Para os modelos DQN, você deve especificar o caminho para o modelo desejado no argumento --model_path . Para modelos de ator-crítico, você precisa especificar os dois arquivos de peso nos argumentos --actor_path e --critic_path .
Usando o Tensorboard, você pode monitorar a pontuação do agente, pois está treinando. Ao treinar, será criada uma pasta de log com o nome que corresponde ao ambiente escolhido. Por exemplo, para seguir a progressão A2C no CartPole-V1, basta executar:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/ Ao treinar com o argumento --gather_stats , um arquivo de log é gerado contendo pontuações em média em mais de 10 jogos em todos os episódios: logs.csv . Usando plotly, você pode visualizar a recompensa média por episódio. Para fazer isso, você precisará primeiro instalar o plotly e obter uma licença gratuita.
pip3 install plotlyPara configurar suas credenciais, execute:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )Finalmente, para plotar os resultados, execute:
python3 utils/plot_results.py < path_to_your_log_file >

