lang2sql
1.0.0
Este repositório fornece um guia passo a passo e um modelo para configurar uma linguagem natural para o gerador de código SQL com a API OPNEAI.
O tutorial também está disponível no meio.
Última atualização: 7 de janeiro de 2024
O rápido desenvolvimento de modelos de linguagem natural, especialmente modelos de idiomas grandes (LLMs), apresentou inúmeras possibilidades para vários campos. Um dos aplicativos mais comuns é usar o LLMS para codificação. Por exemplo, o ChatGPT da OpenAI e o Code Llama da Meta são LLMs que oferecem linguagem natural de ponta aos geradores de código. Um caso de uso potencial é uma linguagem natural para o gerador de código SQL, que poderia ajudar profissionais não técnicos com solicitações de dados simples e, com sorte, permitir que as equipes de dados se concentrem em tarefas mais intensivas em dados. Este tutorial concentra -se em configurar um idioma para o gerador de código SQL usando a API OpenAI.
Um aplicativo possível é um chatbot que pode responder às consultas do usuário com dados relevantes (Figura 1). O chatbot pode ser integrado a um canal Slack usando um aplicativo Python que executa as seguintes etapas:
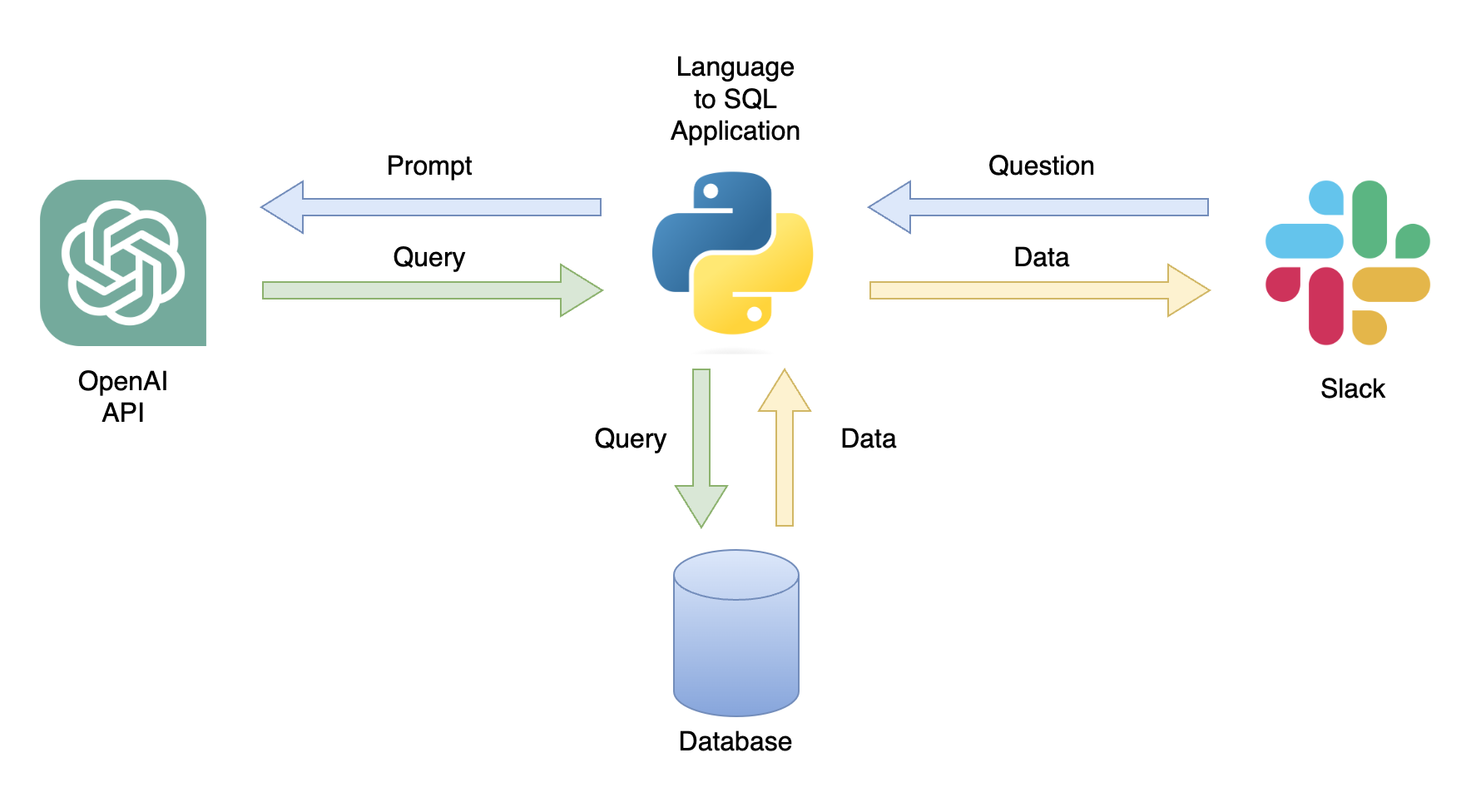
Neste tutorial, criaremos um aplicativo Python passo a passo que converte questões do usuário em consultas SQL.
Este tutorial fornece um guia passo a passo sobre como configurar um aplicativo Python que converte questões gerais em consultas SQL usando a API OpenAI. Isso inclui a seguinte funcionalidade:
A Figura 2 abaixo descreve a arquitetura geral de uma linguagem simples para o gerador de código SQL.
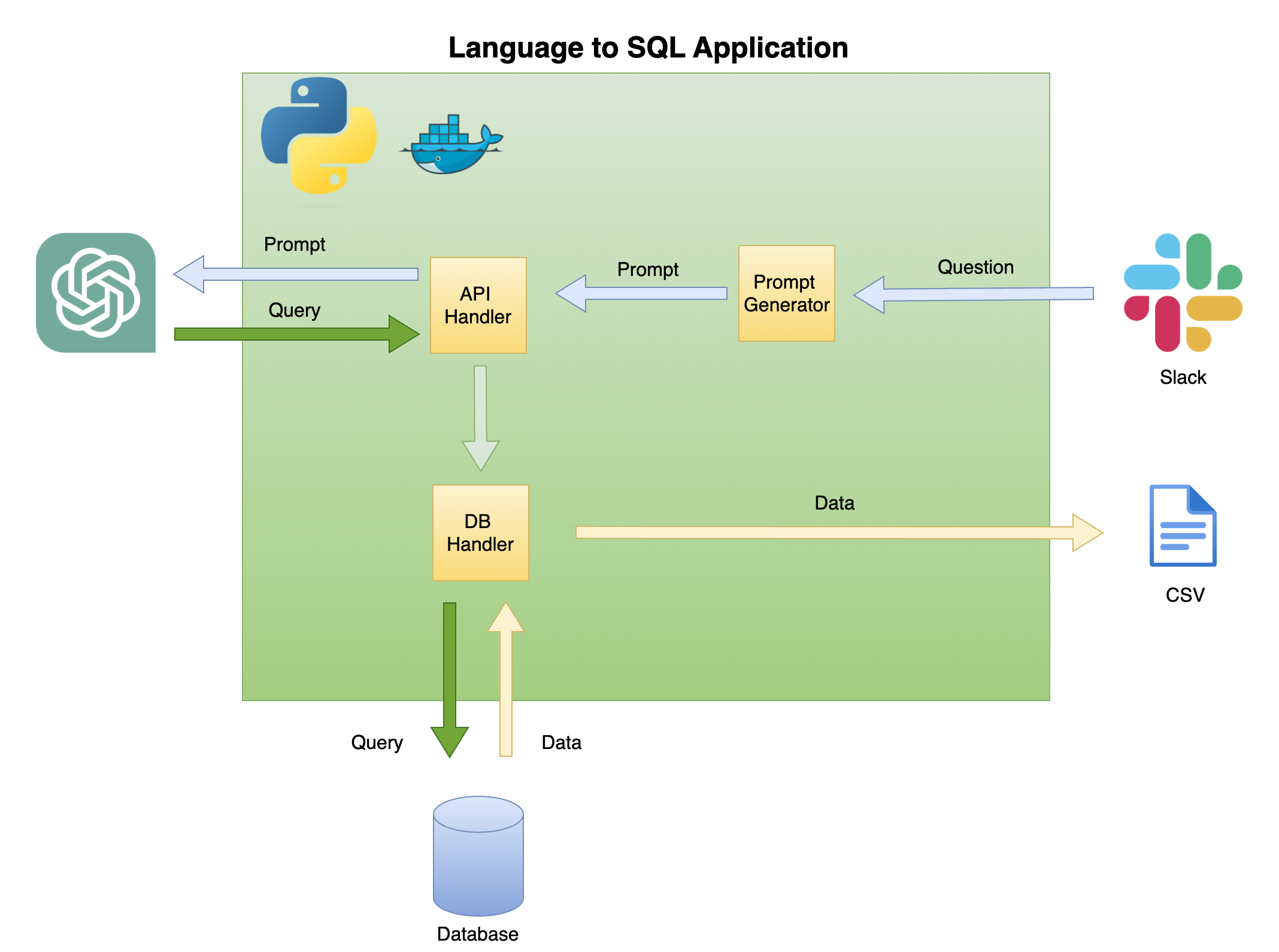
O escopo e o foco deste tutorial estão na caixa verde - construindo a seguinte funcionalidade:
Pergunta para solicitar - transforme a pergunta em um formato imediato:
Manipulador de API - uma função que funciona com a API OpenAI:
Manipulador de DB - uma função que envia a consulta SQL para o banco de dados e retorna os dados necessários
O principal pré -requisito para este tutorial é o conhecimento básico do Python. Isso inclui a seguinte funcionalidade:
Além disso, são necessários conhecimentos básicos do SQL e acesso à API do OpenAI.
Embora não seja necessário, ter um conhecimento básico do Docker é útil, pois o tutorial foi criado em um ambiente Dockerized usando a extensão de contêineres de dev do VSCODE. Se você não tiver experiência com o Docker ou a extensão, ainda poderá executar o tutorial criando um ambiente virtual e instalando as bibliotecas necessárias (conforme descrito abaixo). O conhecimento da engenharia imediata e da API OpenAI também é benéfica.
Criei um tutorial detalhado sobre a definição de um ambiente python Dockerized com o VSCode e a extensão dos contêineres de dev:
https://github.com/ramikrispin/vscode-python
Para configurar uma linguagem natural para a geração de código SQL, usaremos as seguintes bibliotecas Python:
pandas - para processar dados ao longo do processoduckdb - para simular o trabalho com o banco de dadosopenai - para trabalhar com a API Openaitime e os - para carregar arquivos CSV e campos de formatoEste repositório contém as configurações necessárias para iniciar um ambiente dockerizado com os requisitos do tutorial no VSCode e a extensão dos contêineres de dev. Mais detalhes estão disponíveis na próxima seção.
Como alternativa, você pode configurar um ambiente virtual e instalar os requisitos do tutorial seguindo as instruções abaixo usando as instruções na seção de ambiente virtual.
Este tutorial foi construído dentro de um ambiente dockerizado com o VSCode e a extensão dos contêineres de dev. Para executá -lo com o VSCode, você precisará instalar a extensão dos contêineres de dev e abrir o Docker Desktop (ou equivalente). As configurações do ambiente estão disponíveis na pasta .devcontainer :
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
O devcontainer.json possui as instruções de construção e as configurações do VSCode para este ambiente Dockerized:
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
Onde o argumento build define o método docker build e define os argumentos para a compilação. Nesse caso, definimos a versão Python para 3.10 e o ambiente virtual do CONDA como ang2sql . O argumento METHOD define o tipo de ambiente - o openai para instalar as bibliotecas de requisitos para este tutorial usando a API ou transformers do OpenAI para definir o ambiente para a API HuggingFaces (que está fora de escopo deste tutorial).
O argumento remoteEnv permite definir variáveis de ambiente. Vamos usá -lo para definir a chave da API OpenAI. Nesse caso, eu defino a variável localmente como OPENAI_KEY e estou carregando -a usando o argumento localEnv .
Se você quiser saber mais sobre como configurar um ambiente de desenvolvimento do Python com o VSCode e o Docker, verifique este tutorial.
Se você não estiver usando o ambiente dockerizado do tutorial, poderá criar um ambiente virtual local a partir da linha de comando usando o script abaixo:
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
NOTA: Eu usei conda e também deve funcionar com qualquer outro método de ambiente virutal.
Usamos as variáveis ENV_NAME e PYTHON_VER para definir o ambiente virtual e a versão Python, respectivamente.
Para confirmar que seu ambiente está definido corretamente, use a conda list para confirmar que as bibliotecas Python necessárias estão instaladas. Você deve esperar a saída abaixo:
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
Usaremos a API do OpenAI para acessar o ChatGPT usando o mecanismo Text-Davinci-003. Isso exigiu uma conta ativa do OpenAI e a chave da API. É simples definir uma conta de conta e API seguindo as instruções no link abaixo:
https://openai.com/product
Depois de definir o acesso à API e uma chave, recomendo adicionar a chave como uma variável de ambiente ao seu arquivo .zshrc (ou qualquer outro formato que você esteja usando para armazenar variáveis de ambiente no seu sistema de shell). Eu armazenei minha chave da API na variável de ambiente OPENAI_KEY . Por razões convincentes, recomendo que você use a mesma convenção de nomenclatura.
Para definir a variável no arquivo .zshrc (ou equivalente), adicione a linha abaixo ao arquivo:
export OPENAI_KEY= " YOUR_API_KEY " Se estiver usando o vscode ou executar do terminal, você deve reiniciar sua sessão após adicionar a variável ao arquivo .zshrc .
Para simular a funcionalidade do banco de dados, utilizaremos o conjunto de dados de crimes de Chicago. Esse conjunto de dados fornece informações detalhadas sobre os crimes registrados na cidade de Chicago desde 2001. Com quase 8 milhões de registros e 22 colunas, o conjunto de dados inclui informações como classificação de crime, localização, tempo, resultado etc. Os dados estão disponíveis para download do portal de dados de Chicago. Como armazenamos os dados localmente como o quadro de dados do Pandas e usamos o DuckDB para simular a consulta SQL, baixamos um subconjunto dos dados usando os últimos três anos.
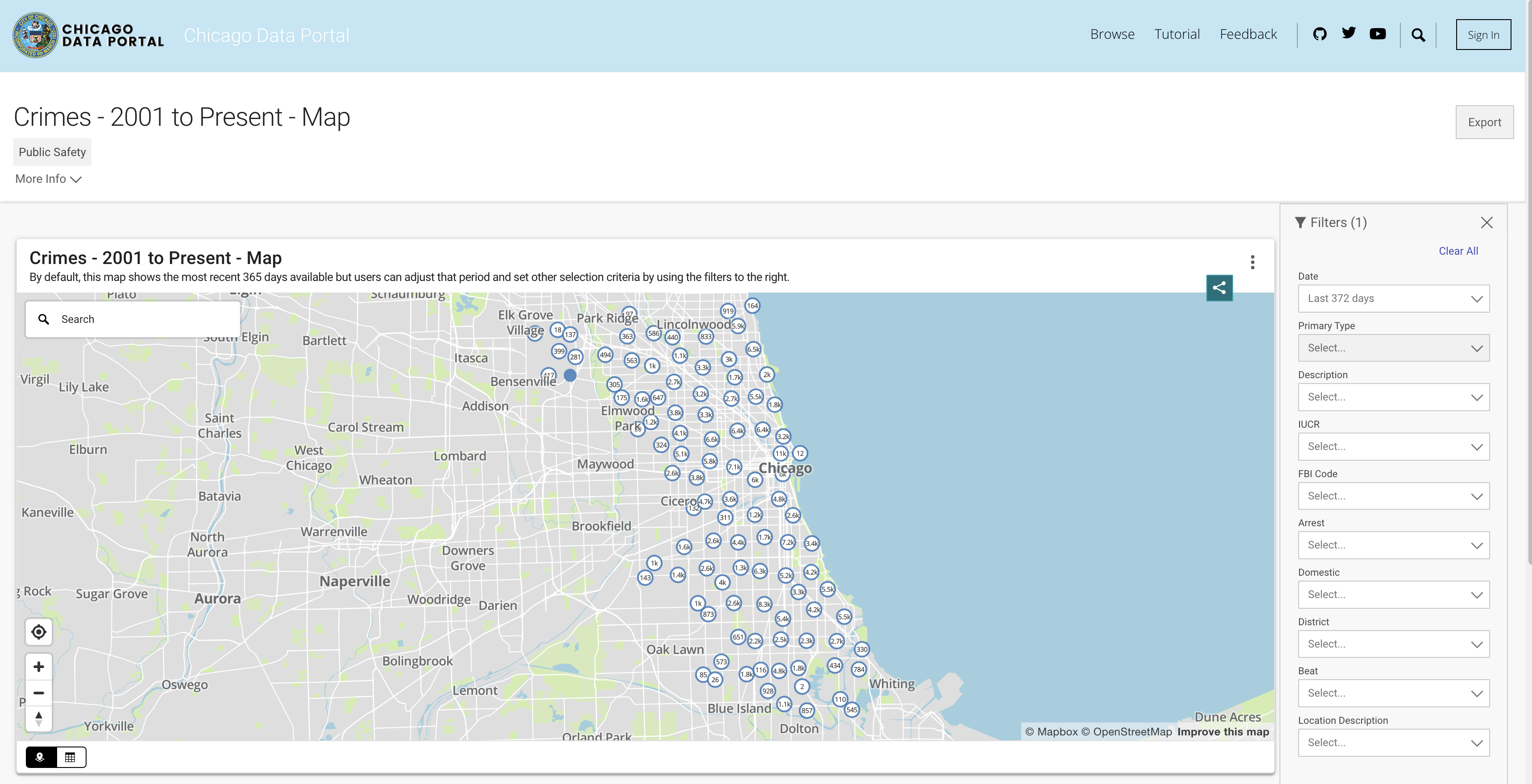
Você pode extrair os dados da API ou baixar um arquivo CSV. Para evitar ligar para a API cada vez que executo o script, baixo os arquivos e os guardo na pasta de dados. Abaixo estão os links para os conjuntos de dados por ano:
Para baixar os dados, use o botão Export no lado superior direito, selecione a opção CSV e clique no botão Download , como visto na Figura 4.
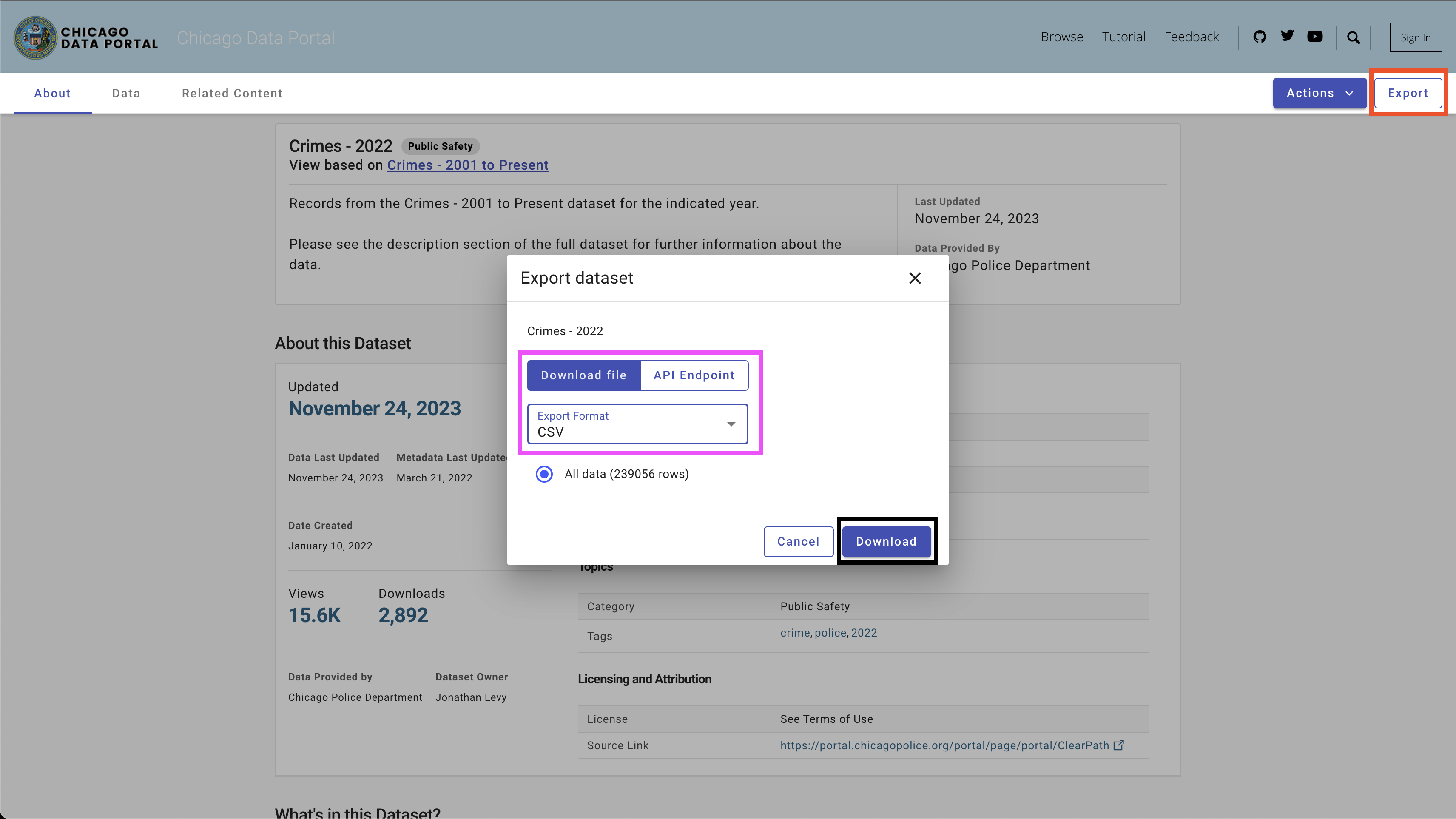
Usei a seguinte Convenção de Nomeação - Chicago_CRIME_YEAR.CSV e salvei os arquivos na pasta data . Cada tamanho de arquivo é próximo de 50 MB. Portanto, eu os adicionei ao arquivo de ignorar Git na pasta data e eles não estão disponíveis neste repositório. Depois de baixar os arquivos e definir seus nomes, você deve ter os seguintes arquivos na pasta:
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
NOTA: A partir do momento da criação deste tutorial, os dados para 2023 ainda estão sendo atualizados. Portanto, você pode receber resultados ligeiramente diferentes ao executar algumas das consultas na seção a seguir.
Vamos para a parte emocionante, que está configurando um gerador de código SQL. Nesta seção, criaremos uma função Python que adota a pergunta de um usuário, a tabela SQL associada e a chave da API do OpenAI e produz a consulta SQL que responde à pergunta do usuário.
Vamos começar carregando o conjunto de dados de crimes de Chicago e as bibliotecas Python necessárias.
Primeira coisa primeiro - vamos carregar as bibliotecas Python necessárias:
import pandas as pd
import duckdb
import openai
import time
import osUtilizaremos as bibliotecas do sistema operacional e do tempo para carregar arquivos CSV e reformar certos campos. Os dados serão processados usando a biblioteca Pandas e simularemos os comandos SQL com a biblioteca DuckDB . Por fim, estabeleceremos uma conexão com a API OpenAI usando a Biblioteca Openai .
Em seguida, carregaremos os arquivos CSV na pasta de dados. O código abaixo lê todos os arquivos CSV disponíveis na pasta de dados:
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]Se você baixou os arquivos correspondentes para os anos 2021 a 2023 e usou a mesma convenção de nomenclatura, você deve esperar a seguinte saída:
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]Em seguida, leremos e carregamos todos os arquivos e os anexaremos em um quadro de dados de pandas:
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . headSe você carregou os arquivos corretamente, deve esperar a seguinte saída:
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) Nota: Ao criar este tutorial, dados parciais para 2023 estavam disponíveis. Anexar os três arquivos resultaria em mais linhas do que o mostrado (648830 linhas).
Antes de entrarmos no código do Python, vamos pausar e revisar como a engenharia rápida funciona e como podemos ajudar o ChatGPT (e geralmente qualquer LLM) a gerar os melhores resultados. Usaremos nesta seção a interface da Web ChatGPT.
Um fator importante nos modelos de aprendizado estatístico e de máquina é que a qualidade da saída depende da qualidade da entrada. Como diz a famosa frase- lixo, lixo . Da mesma forma, a qualidade da saída LLM depende da qualidade do prompt.
Por exemplo, vamos supor que queremos contar o número de casos que acabaram com uma prisão.
Se usarmos o seguinte prompt:
Create an SQL query that counts the number of records that ended up with an arrest.
Aqui está a saída do chatgpt:
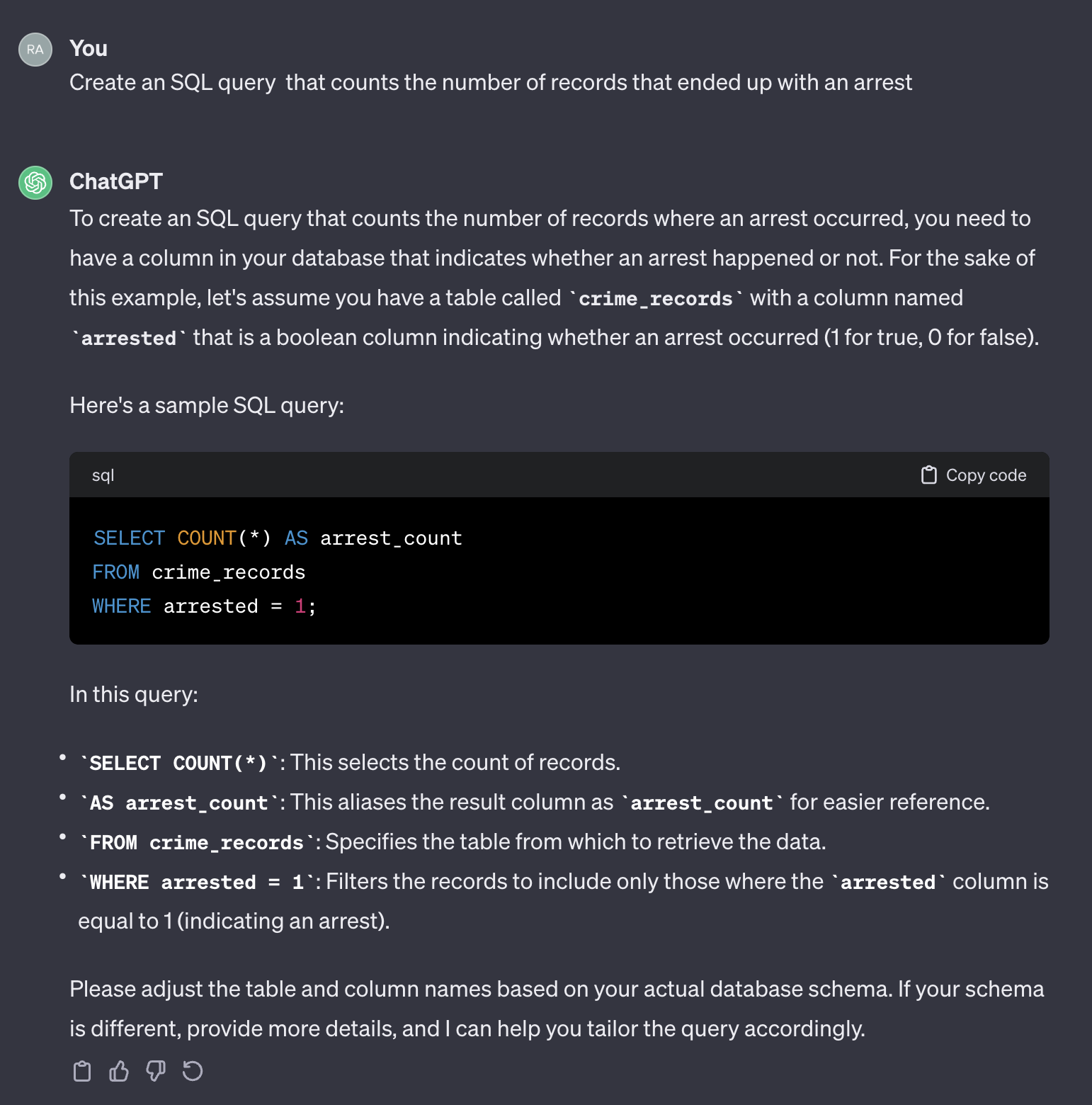
Vale a pena notar que o ChatGPT fornece uma resposta genérica. Embora geralmente esteja correto, pode não ser prático usar em um processo automatizado. Em primeiro lugar, os nomes de campo na resposta não correspondem aos da tabela real que precisamos consultar. Em segundo lugar, o campo que representa o resultado da parada é um booleano ( true ou false ) em vez de um número inteiro ( 0 ou 1 ).
Chatgpt, nesse sentido, age como um humano. É improvável que você receba uma resposta mais precisa de um humano postando a mesma pergunta em um formulário de codificação, como o Stack Overflow ou qualquer outra plataforma semelhante. Dado que não fornecemos nenhum contexto ou informação adicional sobre as características da tabela, esperando que o ChatGPT adivinhe os nomes de campos e seus valores seriam razoáveis. O contexto é um fator crucial em qualquer prompt. Para ilustrar esse ponto, vamos ver como o ChatGPT lida com o seguinte prompt:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
Aqui está a saída do chatgpt:
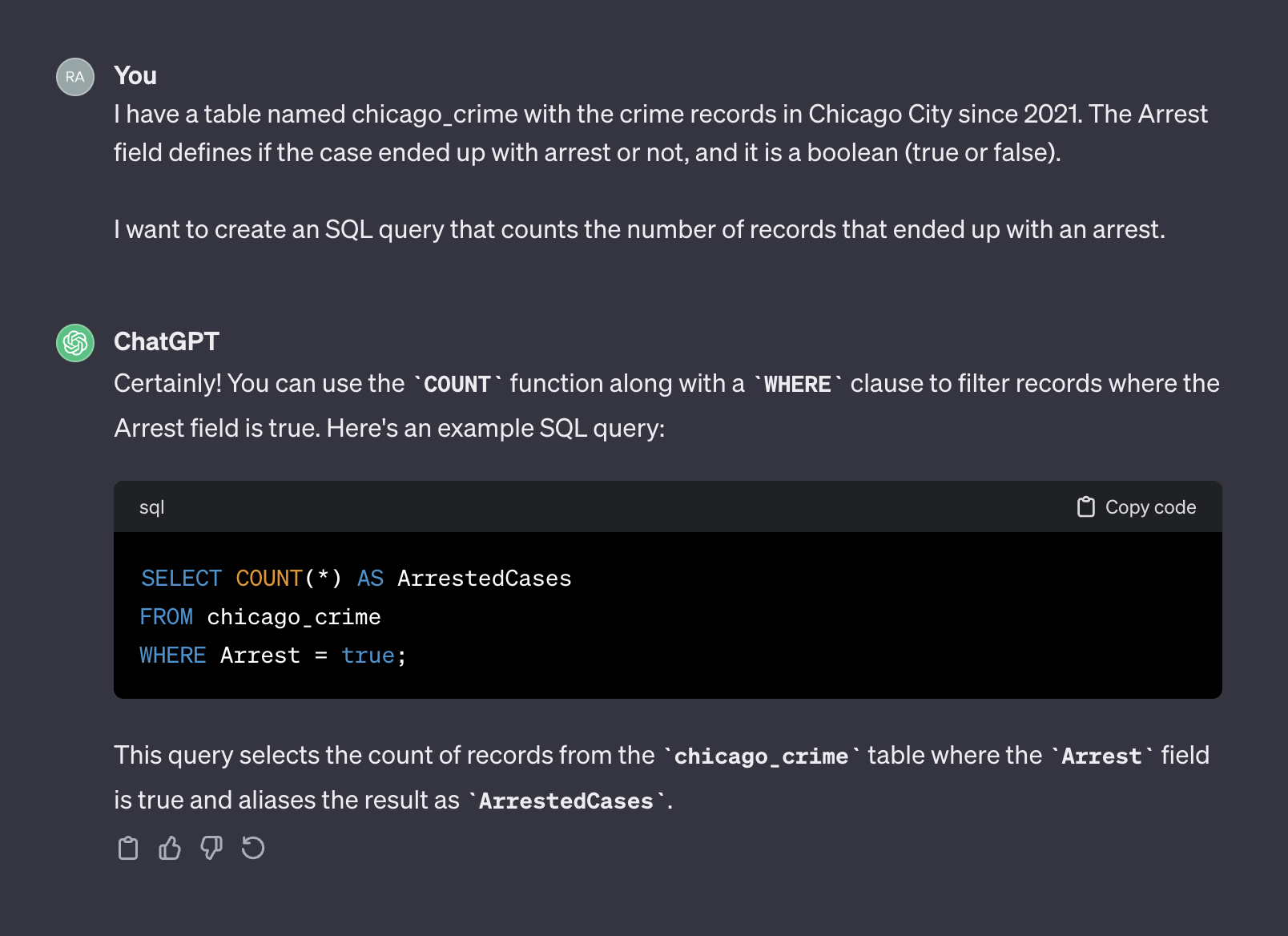
Desta vez, depois de adicionar contexto, o ChatGPT retornou uma consulta correta que podemos usar como está. Geralmente, ao trabalhar com um gerador de texto, o prompt deve incluir dois componentes - contexto e solicitação. No prompt acima, o primeiro parágrafo representa o contexto do prompt:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
Onde o segundo parágrafo representa a solicitação:
I want to create an SQL query that counts the number of records that ended up with an arrest.
A API do OpenAI refere -se ao contexto como um system e solicitação como user .
A documentação da API OpenAI fornece uma recomendação de como definir o system e os componentes user em um prompt ao solicitar para gerar um código SQL:
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
Na próxima seção, usaremos o exemplo do OpenAI acima e a generizaremos em um modelo de uso geral.
Na seção anterior, discutimos a importância da engenharia imediata e como fornecer um bom contexto pode melhorar a precisão da resposta do LLM. Além disso, vimos a estrutura imediata recomendada pelo OpenAI para geração de código SQL. Nesta seção, nos concentraremos em generalizar o processo de criação de instruções para a geração SQL com base nesses princípios. O objetivo é criar uma função Python que receba um nome de tabela e uma pergunta do usuário e cria o prompt de acordo. Por exemplo, para a tabela Tabela chicago_crime que carregamos antes e a pergunta que fizemos na seção anterior, a função deve criar o prompt abaixo:
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
Vamos começar com a estrutura rápida. Adotaremos o formato OpenAI e usaremos o seguinte modelo:
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" Onde o system_template recebeu dois elementos:
Para este tutorial, usaremos a biblioteca do DuckDB para lidar com o quadro de dados dos pandas, pois era uma tabela SQL e extrair os nomes e atributos de campo da tabela usando a função duckdb.sql . Por exemplo, vamos usar o comando SQL DESCRIBE para extrair as informações da tabela chicago_crime .
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )Que deve devolver a tabela abaixo:
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘Nota: as informações de que precisamos - o nome da coluna e seu atributo estão disponíveis nas duas primeiras colunas. Portanto, precisaremos analisar essas colunas e combiná -las com o seguinte formato:
Column_Name Column_Attribute
Por exemplo, a coluna Case Number deve ser transferida para o seguinte formato:
Case Number VARCHAR
A função create_message abaixo orquestra o processo de pegar o nome da tabela e a pergunta e gerar o prompt usando a lógica acima:
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return m A função cria o modelo de prompt e retorna o system rápido e os componentes user e os nomes e atributos das colunas. Por exemplo, vamos executar o número de perguntas de prisão:
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )Isso retornará:
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object A saída da função create_message foi projetada para ajustar os argumentos do OpenAI API ChatCompletion.create , que revisaremos na próxima seção.
Esta seção se concentra na funcionalidade da Biblioteca Python OpenAI. A biblioteca OpenAI permite acesso contínuo à API REST OpenAI. Usaremos a biblioteca para conectar à API e enviar solicitações GET com nosso prompt.
Vamos começar conectando -se à API, alimentando nossa API ao openai.api_key Função:
openai . api_key = os . getenv ( 'OPENAI_KEY' ) Nota: Usamos a função getenv da biblioteca os para carregar a variável de ambiente OpenAi_Key. Como alternativa, você pode alimentar diretamente sua chave da API:
openai . api_key = "YOUR_OPENAI_API_KEY"A API OpenAI fornece acesso a uma variedade de LLMs com diferentes funcionalidades. Você pode usar a função Openai.model.list para obter uma lista dos modelos disponíveis:
openai . Model . list () Para transformá -lo em um bom formato, você pode envolvê -lo em um quadro de dados pandas :
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . headE deve esperar a seguinte saída:
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
Para o nosso caso de uso, geração de texto, usaremos o modelo gpt-3.5-turbo , que é uma melhoria do modelo GPT3. O modelo gpt-3.5-turbo representa uma série de modelos que continuam sendo atualizados e, por padrão, se a versão do modelo não for especificada, a API apontará para a versão estável mais recente. Ao criar este tutorial, o modelo padrão 3.5 foi gpt-3.5-turbo-0613 , usando 4.096 tokens e treinado com dados até setembro de 2021.
Para enviar uma solicitação GET com nosso prompt, usaremos a função ChatCompletion.create . A função tem muitos argumentos, e usaremos os seguintes:
model - o ID do modelo a ser usado, uma lista completa disponível aquimessages - Uma lista de mensagens compreendendo a conversa até agora (por exemplo, o prompt)temperature - Gerencie a aleatoriedade ou determinismo da saída do processo, definindo o nível de temperatura de amostragem. O nível de temperatura aceita valores entre 0 e 2. Quando o valor do argumento é maior, a saída se torna mais aleatória. Por outro lado, quando o valor do argumento está mais próximo de 0, a saída se torna mais determinística (reproduzível)max_tokens - o número máximo de tokens para gerar na conclusãoA lista completa dos argumentos de função disponíveis na API Documentaiton.
No exemplo abaixo, usaremos o mesmo prompt que o usado na interface da Web ChatGPT (ou seja, Figura 5), desta vez usando a API. Vamos gerar o prompt com a função create_message :
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query ) Vamos transformar o prompt acima na estrutura do argumento do ChatCompletion.create Função messages :
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
] Em seguida, enviaremos o prompt (ou seja, o objeto message ) para a API usando a função ChatCompletion.create :
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) Definiremos o argumento temperature para 0 para garantir alta reprodutibilidade e limitar o número de tokens na conclusão do texto para 256. A função retorna um objeto JSON com a conclusão do texto, os metadados e outras informações:
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}Usando as Índias de resposta, podemos extrair a consulta SQL:
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' Usando a função duckdb.sql para executar o código SQL:
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Na próxima seção, generalizaremos e funcionalizaremos todas as etapas.
Nas seções anteriores, introduzimos o formato prompt, definimos a função create_message e revisamos a funcionalidade da função ChatCompletion.create . Nesta seção, costuramos tudo juntos.
Uma coisa a observar sobre o código SQL retornado da função ChatCompletion.create é que a variável não retorna com cotações. Isso pode ser um problema quando o nome da variável na consulta combina duas ou mais palavras. Por exemplo, o uso de uma variável como Case Number ou Primary Type do chicago_crime dentro de uma consulta sem usar cotações resultará em um erro.
Usaremos a função auxiliar abaixo para adicionar cotações às variáveis na consulta se a consulta retornada não tiver uma:
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query ) As entradas de função são os nomes de consulta e as colunas da tabela correspondente. Ele faz um loop sobre os nomes das colunas e adiciona cotações se encontrar uma correspondência dentro da consulta. Por exemplo, podemos executá -lo com a consulta SQL que analisamos na saída da função ChatCompletion.create :
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' Você pode observar que ele adicionou cotações à variável Arrest .
Agora podemos apresentar a função lang2sql que aproveita as três funções que introduzimos até agora - create_message , ChatCompletion.create e add_quotes para traduzir uma pergunta do usuário em um código SQL:
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return output A função recebe, como entrada, a chave da API do OpenAI, o nome da tabela e os parâmetros principais da função ChatCompletion.create e retorna um objeto com o prompt, a resposta da API e a consulta analisada. Por exemplo, vamos tentar executar novamente a mesma consulta que usamos na seção anterior com a função lang2sql :
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )Podemos extrair a consulta SQL do objeto de saída:
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;Podemos testar a saída em relação aos resultados que recebemos na seção anterior:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Vamos agora adicionar complexidade adicional à pergunta e pedir casos que acabaram com uma prisão durante 2022:
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query ) Como você pode ver, o modelo identificou corretamente o campo relevante como Year e gerou a consulta correta:
print ( response . sql )O código SQL:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;Testando a consulta na tabela:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘Aqui está um exemplo de uma pergunta simples que exigia um agrupamento por uma variável específica:
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Você pode ver na saída de resposta que o código SQL neste caso está correto:
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "Esta é a saída da consulta:
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘Por último, mas não menos importante, o LLM pode identificar o contexto (por exemplo, qual variável), mesmo quando fornecemos um nome de variável parcial:
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Ele retorna o código SQL abaixo:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;Esta é a saída da consulta:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘Neste tutorial, demonstramos como criar um gerador de código SQL com algumas linhas de código Python e utilizar a API OpenAI. Vimos que a qualidade do prompt é crucial para o sucesso do código SQL resultante. Além do contexto fornecido pelo prompt, os nomes de campo também devem fornecer informações sobre as características do campo para ajudar o LLM a identificar a relevância do campo para a pergunta do usuário.
Embora este tutorial tenha sido limitado a trabalhar com uma única tabela (por exemplo, nenhuma junção entre tabelas), alguns LLMs, como os disponíveis no OpenAI, podem lidar com casos mais complexos, incluindo trabalhar com várias tabelas e identificar as operações de junção corretas. Ajustar a função LANG2SQL para lidar com várias tabelas pode ser uma boa etapa.
Este tutorial está licenciado sob uma licença Creative Commons Attribution-NonCommercial-Sharealike 4.0 International.


